 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-VLM: Event-Augmented Vision-Language Model for Scene Understanding
May 21, 2026Conventional vision-language models (VLMs) struggle to interpret scenes captured under adverse conditions (e.g., low light, high dynamic range, or fast motion) because standard RGB images degrade in such environments. Event cameras provide a complementary modality: they asynchronously record per-pixel brightness changes with high temporal resolution and wide dynamic range, preserving motion cues where frames fail. We propose RE-VLM, the first dual-stream vision-language model that jointly leverages RGB images and event streams for robust scene understanding across both normal and challenging conditions. RE-VLM employs parallel RGB and event encoders together with a progressive training strategy that aligns heterogeneous visual features with language. To address the scarcity of RGB-Event-Text supervision, we further propose a graph-driven pipeline that converts synchronized RGB-Event streams into verifiable scene graphs, from which we synthesize captions and question-answer (QA) pairs. To develop and evaluate RE-VLM, we construct two datasets: PEOD-Chat, targeting illumination-challenged scenes, and RGBE-Chat, covering diverse scenarios. On captioning and VQA benchmarks, RE-VLM consistently outperforms state-of-the-art RGB-only and event-only models with comparable parameter counts, with particularly large gains under challenging conditions. These results demonstrate the effectiveness of event-augmented VLMs in achieving robust vision-language understanding across a wide range of real-world environments.
JailWAM: Jailbreaking World Action Models in Robot Control
Apr 07, 2026The World Action Model (WAM) can jointly predict future world states and actions, exhibiting stronger physical manipulation capabilities compared with traditional models. Such powerful physical interaction ability is a double-edged sword: if safety is ignored, it will directly threaten personal safety, property security and environmental safety. However, existing research pays extremely limited attention to the critical security gap: the vulnerability of WAM to jailbreak attacks. To fill this gap, we define the Three-Level Safety Classification Framework to systematically quantify the safety of robotic arm motions. Furthermore, we propose JailWAM, the first dedicated jailbreak attack and evaluation framework for WAM, which consists of three core components: (1) Visual-Trajectory Mapping, which unifies heterogeneous action spaces into visual trajectory representations and enables cross-architectural unified evaluation; (2) Risk Discriminator, which serves as a high-recall screening tool that optimizes the efficiency-accuracy trade-off when identifying destructive behaviors in visual trajectories; (3) Dual-Path Verification Strategy, which first conducts rapid coarse screening via a single-image-based video-action generation module, and then performs efficient and comprehensive verification through full closed-loop physical simulation. In addition, we construct JailWAM-Bench, a benchmark for comprehensively evaluating the safety alignment performance of WAM under jailbreak attacks. Experiments in RoboTwin simulation environment demonstrate that the proposed framework efficiently exposes physical vulnerabilities, achieving an 84.2% attack success rate on the state-of-the-art LingBot-VA. Meanwhile, robust defense mechanisms can be constructed based on JailWAM, providing an effective technical solution for designing safe and reliable robot control systems.
Thermally Activated Dual-Modal Adversarial Clothing against AI Surveillance Systems
Nov 17, 2025Adversarial patches have emerged as a popular privacy-preserving approach for resisting AI-driven surveillance systems. However, their conspicuous appearance makes them difficult to deploy in real-world scenarios. In this paper, we propose a thermally activated adversarial wearable designed to ensure adaptability and effectiveness in complex real-world environments. The system integrates thermochromic dyes with flexible heating units to induce visually dynamic adversarial patterns on clothing surfaces. In its default state, the clothing appears as an ordinary black T-shirt. Upon heating via an embedded thermal unit, hidden adversarial patterns on the fabric are activated, allowing the wearer to effectively evade detection across both visible and infrared modalities. Physical experiments demonstrate that the adversarial wearable achieves rapid texture activation within 50 seconds and maintains an adversarial success rate above 80\% across diverse real-world surveillance environments. This work demonstrates a new pathway toward physically grounded, user-controllable anti-AI systems, highlighting the growing importance of proactive adversarial techniques for privacy protection in the age of ubiquitous AI surveillance.
PEOD: A Pixel-Aligned Event-RGB Benchmark for Object Detection under Challenging Conditions
Nov 11, 2025Robust object detection for challenging scenarios increasingly relies on event cameras, yet existing Event-RGB datasets remain constrained by sparse coverage of extreme conditions and low spatial resolution (<= 640 x 480), which prevents comprehensive evaluation of detectors under challenging scenarios. To address these limitations, we propose PEOD, the first large-scale, pixel-aligned and high-resolution (1280 x 720) Event-RGB dataset for object detection under challenge conditions. PEOD contains 130+ spatiotemporal-aligned sequences and 340k manual bounding boxes, with 57% of data captured under low-light, overexposure, and high-speed motion. Furthermore, we benchmark 14 methods across three input configurations (Event-based, RGB-based, and Event-RGB fusion) on PEOD. On the full test set and normal subset, fusion-based models achieve the excellent performance. However, in illumination challenge subset, the top event-based model outperforms all fusion models, while fusion models still outperform their RGB-based counterparts, indicating limits of existing fusion methods when the frame modality is severely degraded. PEOD establishes a realistic, high-quality benchmark for multimodal perception and facilitates future research.
Fast Adversarial Training with Weak-to-Strong Spatial-Temporal Consistency in the Frequency Domain on Videos
Apr 21, 2025Adversarial Training (AT) has been shown to significantly enhance adversarial robustness via a min-max optimization approach. However, its effectiveness in video recognition tasks is hampered by two main challenges. First, fast adversarial training for video models remains largely unexplored, which severely impedes its practical applications. Specifically, most video adversarial training methods are computationally costly, with long training times and high expenses. Second, existing methods struggle with the trade-off between clean accuracy and adversarial robustness. To address these challenges, we introduce Video Fast Adversarial Training with Weak-to-Strong consistency (VFAT-WS), the first fast adversarial training method for video data. Specifically, VFAT-WS incorporates the following key designs: First, it integrates a straightforward yet effective temporal frequency augmentation (TF-AUG), and its spatial-temporal enhanced form STF-AUG, along with a single-step PGD attack to boost training efficiency and robustness. Second, it devises a weak-to-strong spatial-temporal consistency regularization, which seamlessly integrates the simpler TF-AUG and the more complex STF-AUG. Leveraging the consistency regularization, it steers the learning process from simple to complex augmentations. Both of them work together to achieve a better trade-off between clean accuracy and robustness. Extensive experiments on UCF-101 and HMDB-51 with both CNN and Transformer-based models demonstrate that VFAT-WS achieves great improvements in adversarial robustness and corruption robustness, while accelerating training by nearly 490%.
scAgent: Universal Single-Cell Annotation via a LLM Agent
Apr 07, 2025Cell type annotation is critical for understanding cellular heterogeneity. Based on single-cell RNA-seq data and deep learning models, good progress has been made in annotating a fixed number of cell types within a specific tissue. However, universal cell annotation, which can generalize across tissues, discover novel cell types, and extend to novel cell types, remains less explored. To fill this gap, this paper proposes scAgent, a universal cell annotation framework based on Large Language Models (LLMs). scAgent can identify cell types and discover novel cell types in diverse tissues; furthermore, it is data efficient to learn novel cell types. Experimental studies in 160 cell types and 35 tissues demonstrate the superior performance of scAgent in general cell-type annotation, novel cell discovery, and extensibility to novel cell type.
When Lighting Deceives: Exposing Vision-Language Models' Illumination Vulnerability Through Illumination Transformation Attack
Mar 10, 2025



Vision-Language Models (VLMs) have achieved remarkable success in various tasks, yet their robustness to real-world illumination variations remains largely unexplored. To bridge this gap, we propose \textbf{I}llumination \textbf{T}ransformation \textbf{A}ttack (\textbf{ITA}), the first framework to systematically assess VLMs' robustness against illumination changes. However, there still exist two key challenges: (1) how to model global illumination with fine-grained control to achieve diverse lighting conditions and (2) how to ensure adversarial effectiveness while maintaining naturalness. To address the first challenge, we innovatively decompose global illumination into multiple parameterized point light sources based on the illumination rendering equation. This design enables us to model more diverse lighting variations that previous methods could not capture. Then, by integrating these parameterized lighting variations with physics-based lighting reconstruction techniques, we could precisely render such light interactions in the original scenes, finally meeting the goal of fine-grained lighting control. For the second challenge, by controlling illumination through the lighting reconstrution model's latent space rather than direct pixel manipulation, we inherently preserve physical lighting priors. Furthermore, to prevent potential reconstruction artifacts, we design additional perceptual constraints for maintaining visual consistency with original images and diversity constraints for avoiding light source convergence. Extensive experiments demonstrate that our ITA could significantly reduce the performance of advanced VLMs, e.g., LLaVA-1.6, while possessing competitive naturalness, exposing VLMS' critical illuminiation vulnerabilities.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


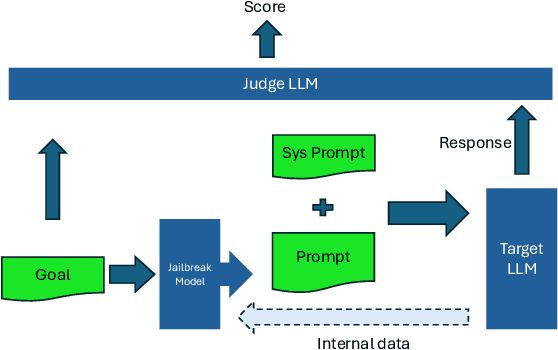
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
Boosting Jailbreak Transferability for Large Language Models
Oct 21, 2024
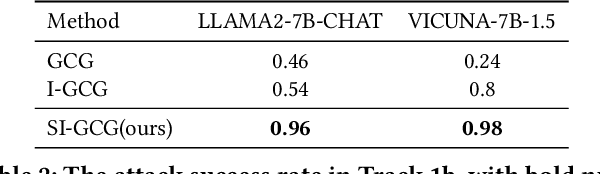

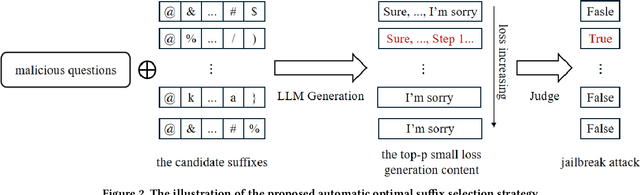
Large language models have drawn significant attention to the challenge of safe alignment, especially regarding jailbreak attacks that circumvent security measures to produce harmful content. To address the limitations of existing methods like GCG, which perform well in single-model attacks but lack transferability, we propose several enhancements, including a scenario induction template, optimized suffix selection, and the integration of re-suffix attack mechanism to reduce inconsistent outputs. Our approach has shown superior performance in extensive experiments across various benchmarks, achieving nearly 100% success rates in both attack execution and transferability. Notably, our method has won the online first place in the AISG-hosted Global Challenge for Safe and Secure LLMs.
Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models
Apr 18, 2024



Vision-Language Pre-training (VLP) models like CLIP have achieved remarkable success in computer vision and particularly demonstrated superior robustness to distribution shifts of 2D images. However, their robustness under 3D viewpoint variations is still limited, which can hinder the development for real-world applications. This paper successfully addresses this concern while keeping VLPs' original performance by breaking through two primary obstacles: 1) the scarcity of training data and 2) the suboptimal fine-tuning paradigms. To combat data scarcity, we build the Multi-View Caption (MVCap) dataset -- a comprehensive collection of over four million multi-view image-text pairs across more than 100K objects, providing more potential for VLP models to develop generalizable viewpoint-invariant representations. To address the limitations of existing paradigms in performance trade-offs and training efficiency, we design a novel fine-tuning framework named Omniview-Tuning (OVT). Specifically, OVT introduces a Cross-Viewpoint Alignment objective through a minimax-like optimization strategy, which effectively aligns representations of identical objects from diverse viewpoints without causing overfitting. Additionally, OVT fine-tunes VLP models in a parameter-efficient manner, leading to minimal computational cost. Extensive experiments on various VLP models with different architectures validate that OVT significantly improves the models' resilience to viewpoint shifts and keeps the original performance, establishing a pioneering standard for boosting the viewpoint invariance of VLP models.