 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadGS-Reg: Registering Spine CT with Biplanar X-rays via Joint 3D Radiative Gaussians Reconstruction and 3D/3D Registration
Aug 28, 2025Computed Tomography (CT)/X-ray registration in image-guided navigation remains challenging because of its stringent requirements for high accuracy and real-time performance. Traditional "render and compare" methods, relying on iterative projection and comparison, suffer from spatial information loss and domain gap. 3D reconstruction from biplanar X-rays supplements spatial and shape information for 2D/3D registration, but current methods are limited by dense-view requirements and struggles with noisy X-rays. To address these limitations, we introduce RadGS-Reg, a novel framework for vertebral-level CT/X-ray registration through joint 3D Radiative Gaussians (RadGS) reconstruction and 3D/3D registration. Specifically, our biplanar X-rays vertebral RadGS reconstruction module explores learning-based RadGS reconstruction method with a Counterfactual Attention Learning (CAL) mechanism, focusing on vertebral regions in noisy X-rays. Additionally, a patient-specific pre-training strategy progressively adapts the RadGS-Reg from simulated to real data while simultaneously learning vertebral shape prior knowledge. Experiments on in-house datasets demonstrate the state-of-the-art performance for both tasks, surpassing existing methods. The code is available at: https://github.com/shenao1995/RadGS_Reg.
UMMAFormer: A Universal Multimodal-adaptive Transformer Framework for Temporal Forgery Localization
Aug 28, 2023
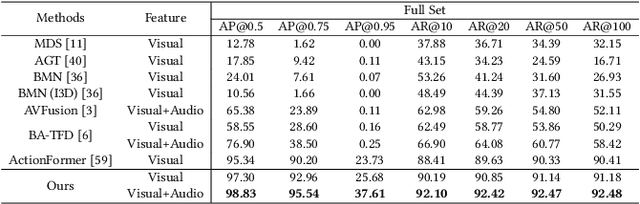
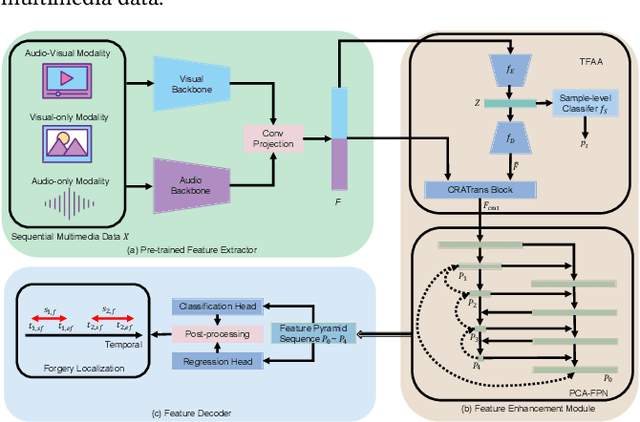

The emergence of artificial intelligence-generated content (AIGC) has raised concerns about the authenticity of multimedia content in various fields. However, existing research for forgery content detection has focused mainly on binary classification tasks of complete videos, which has limited applicability in industrial settings. To address this gap, we propose UMMAFormer, a novel universal transformer framework for temporal forgery localization (TFL) that predicts forgery segments with multimodal adaptation. Our approach introduces a Temporal Feature Abnormal Attention (TFAA) module based on temporal feature reconstruction to enhance the detection of temporal differences. We also design a Parallel Cross-Attention Feature Pyramid Network (PCA-FPN) to optimize the Feature Pyramid Network (FPN) for subtle feature enhancement. To evaluate the proposed method, we contribute a novel Temporal Video Inpainting Localization (TVIL) dataset specifically tailored for video inpainting scenes. Our experiments show that our approach achieves state-of-the-art performance on benchmark datasets, including Lav-DF, TVIL, and Psynd, significantly outperforming previous methods. The code and data are available at https://github.com/ymhzyj/UMMAFormer/.
* 11 pages, 8 figures, 66 references. This paper has been accepted for ACM MM 2023
Erase and Restore: Simple, Accurate and Resilient Detection of $L_2$ Adversarial Examples
Jan 01, 2020
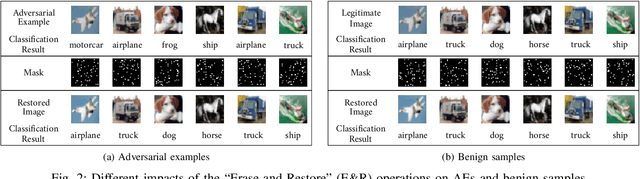
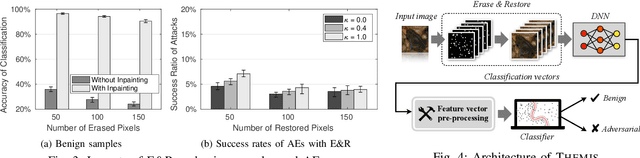
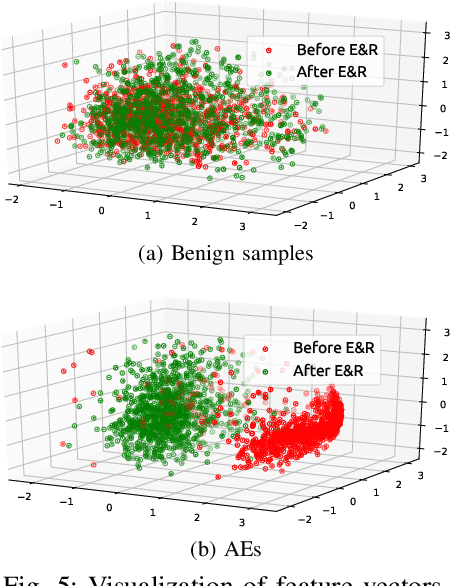
By adding carefully crafted perturbations to input images, adversarial examples (AEs) can be generated to mislead neural-network-based image classifiers. $L_2$ adversarial perturbations by Carlini and Wagner (CW) are regarded as among the most effective attacks. While many countermeasures against AEs have been proposed, detection of adaptive CW $L_2$ AEs has been very inaccurate. Our observation is that those deliberately altered pixels in an $L_2$ AE, altogether, exert their malicious influence. By randomly erasing some pixels from an $L_2$ AE and then restoring it with an inpainting technique, such an AE, before and after the steps, tends to have different classification results, while a benign sample does not show this symptom. Based on this, we propose a novel AE detection technique, Erase and Restore (E\&R), that exploits the limitation of $L_2$ attacks. On two popular image datasets, CIFAR-10 and ImageNet, our experiments show that the proposed technique is able to detect over 98% of the AEs generated by CW and other $L_2$ algorithms and has a very low false positive rate on benign images. Moreover, our approach demonstrate strong resilience to adaptive attacks. While adding noises and inpainting each have been well studied, by combining them together, we deliver a simple, accurate and resilient detection technique against adaptive $L_2$ AEs.
A Cross-Architecture Instruction Embedding Model for Natural Language Processing-Inspired Binary Code Analysis
Dec 23, 2018



Given a closed-source program, such as most of proprietary software and viruses, binary code analysis is indispensable for many tasks, such as code plagiarism detection and malware analysis. Today, source code is very often compiled for various architectures, making cross-architecture binary code analysis increasingly important. A binary, after being disassembled, is expressed in an assembly languages. Thus, recent work starts exploring Natural Language Processing (NLP) inspired binary code analysis. In NLP, words are usually represented in high-dimensional vectors (i.e., embeddings) to facilitate further processing, which is one of the most common and critical steps in many NLP tasks. We regard instructions as words in NLP-inspired binary code analysis, and aim to represent instructions as embeddings as well. To facilitate cross-architecture binary code analysis, our goal is that similar instructions, regardless of their architectures, have embeddings close to each other. To this end, we propose a joint learning approach to generating instruction embeddings that capture not only the semantics of instructions within an architecture, but also their semantic relationships across architectures. To the best of our knowledge, this is the first work on building cross-architecture instruction embedding model. As a showcase, we apply the model to resolving one of the most fundamental problems for binary code similarity comparison---semantics-based basic block comparison, and the solution outperforms the code statistics based approach. It demonstrates that it is promising to apply the model to other cross-architecture binary code analysis tasks.
Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs
Aug 08, 2018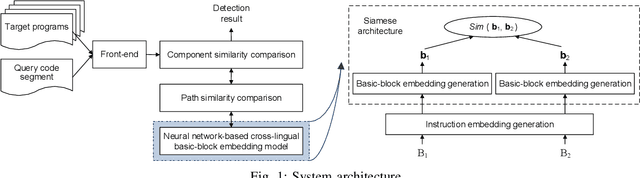
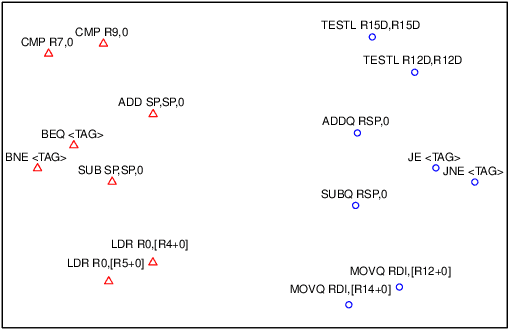
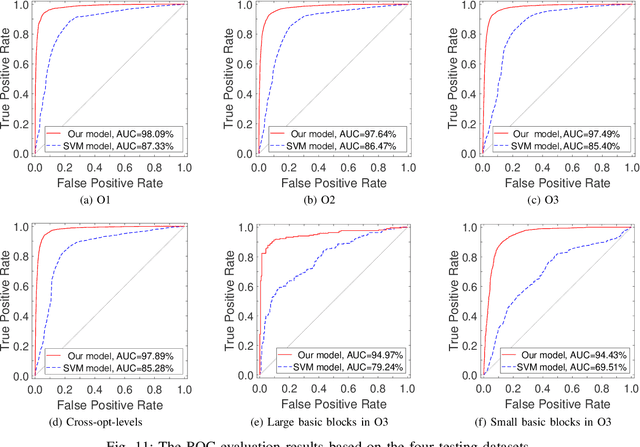
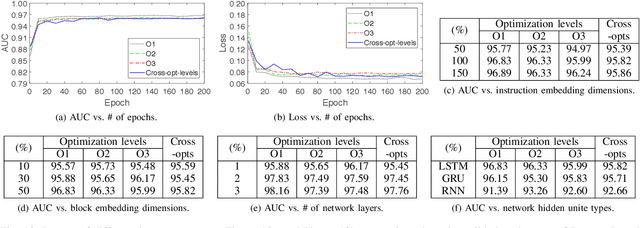
Binary code analysis allows analyzing binary code without having access to the corresponding source code. A binary, after disassembly, is expressed in an assembly language. This inspires us to approach binary analysis by leveraging ideas and techniques from Natural Language Processing (NLP), a rich area focused on processing text of various natural languages. We notice that binary code analysis and NLP share a lot of analogical topics, such as semantics extraction, summarization, and classification. This work utilizes these ideas to address two important code similarity comparison problems. (I) Given a pair of basic blocks for different instruction set architectures (ISAs), determining whether their semantics is similar or not; and (II) given a piece of code of interest, determining if it is contained in another piece of assembly code for a different ISA. The solutions to these two problems have many applications, such as cross-architecture vulnerability discovery and code plagiarism detection. We implement a prototype system INNEREYE and perform a comprehensive evaluation. A comparison between our approach and existing approaches to Problem I shows that our system outperforms them in terms of accuracy, efficiency and scalability. And the case studies utilizing the system demonstrate that our solution to Problem II is effective. Moreover, this research showcases how to apply ideas and techniques from NLP to large-scale binary code analysis.