 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Alignment and Disentanglement for Cross-Domain CTR Prediction with Domain-Encompassing Features
Jan 24, 2026Cross-domain recommendation (CDR) has been increasingly explored to address data sparsity and cold-start issues. However, recent approaches typically disentangle domain-invariant features shared between source and target domains, as well as domain-specific features for each domain. However, they often rely solely on domain-invariant features combined with target domain-specific features, which can lead to suboptimal performance. To overcome the limitations, this paper presents the Adversarial Alignment and Disentanglement Cross-Domain Recommendation ($A^2DCDR$ ) model, an innovative approach designed to capture a comprehensive range of cross-domain information, including both domain-invariant and valuable non-aligned features. The $A^2DCDR$ model enhances cross-domain recommendation through three key components: refining MMD with adversarial training for better generalization, employing a feature disentangler and reconstruction mechanism for intra-domain disentanglement, and introducing a novel fused representation combining domain-invariant, non-aligned features with original contextual data. Experiments on real-world datasets and online A/B testing show that $A^2DCDR$ outperforms existing methods, confirming its effectiveness and practical applicability. The code is provided at https://github.com/youzi0925/A-2DCDR/tree/main.
RadGS-Reg: Registering Spine CT with Biplanar X-rays via Joint 3D Radiative Gaussians Reconstruction and 3D/3D Registration
Aug 28, 2025Computed Tomography (CT)/X-ray registration in image-guided navigation remains challenging because of its stringent requirements for high accuracy and real-time performance. Traditional "render and compare" methods, relying on iterative projection and comparison, suffer from spatial information loss and domain gap. 3D reconstruction from biplanar X-rays supplements spatial and shape information for 2D/3D registration, but current methods are limited by dense-view requirements and struggles with noisy X-rays. To address these limitations, we introduce RadGS-Reg, a novel framework for vertebral-level CT/X-ray registration through joint 3D Radiative Gaussians (RadGS) reconstruction and 3D/3D registration. Specifically, our biplanar X-rays vertebral RadGS reconstruction module explores learning-based RadGS reconstruction method with a Counterfactual Attention Learning (CAL) mechanism, focusing on vertebral regions in noisy X-rays. Additionally, a patient-specific pre-training strategy progressively adapts the RadGS-Reg from simulated to real data while simultaneously learning vertebral shape prior knowledge. Experiments on in-house datasets demonstrate the state-of-the-art performance for both tasks, surpassing existing methods. The code is available at: https://github.com/shenao1995/RadGS_Reg.
Neural Graph Matching for Video Retrieval in Large-Scale Video-driven E-commerce
Aug 01, 2024



With the rapid development of the short video industry, traditional e-commerce has encountered a new paradigm, video-driven e-commerce, which leverages attractive videos for product showcases and provides both video and item services for users. Benefitting from the dynamic and visualized introduction of items,video-driven e-commerce has shown huge potential in stimulating consumer confidence and promoting sales. In this paper, we focus on the video retrieval task, facing the following challenges: (1) Howto handle the heterogeneities among users, items, and videos? (2)How to mine the complementarity between items and videos for better user understanding? In this paper, we first leverage the dual graph to model the co-existing of user-video and user-item interactions in video-driven e-commerce and innovatively reduce user preference understanding to a graph matching problem. To solve it, we further propose a novel bi-level Graph Matching Network(GMN), which mainly consists of node- and preference-level graph matching. Given a user, node-level graph matching aims to match videos and items, while preference-level graph matching aims to match multiple user preferences extracted from both videos and items. Then the proposed GMN can generate and improve user embedding by aggregating matched nodes or preferences from the dual graph in a bi-level manner. Comprehensive experiments show the superiority of the proposed GMN with significant improvements over state-of-the-art approaches (e.g., AUC+1.9% and CTR+7.15%). We have developed it on a well-known video-driven e-commerce platform, serving hundreds of millions of users every day
NDGGNET-A Node Independent Gate based Graph Neural Networks
May 11, 2022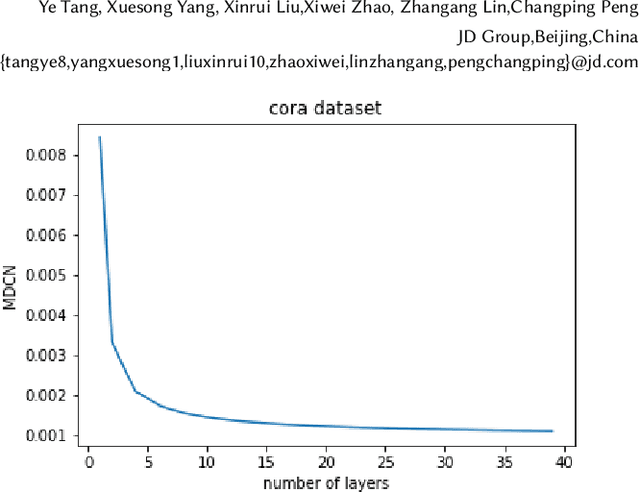
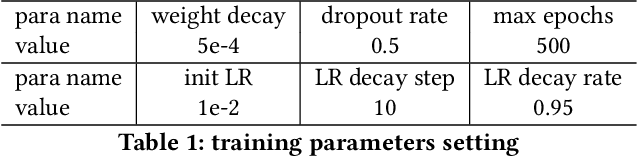
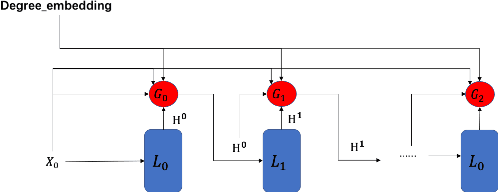
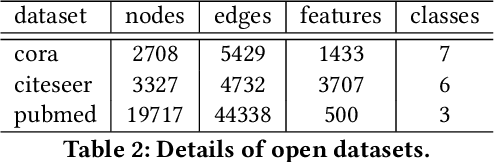
Graph Neural Networks (GNNs) is an architecture for structural data, and has been adopted in a mass of tasks and achieved fabulous results, such as link prediction, node classification, graph classification and so on. Generally, for a certain node in a given graph, a traditional GNN layer can be regarded as an aggregation from one-hop neighbors, thus a set of stacked layers are able to fetch and update node status within multi-hops. For nodes with sparse connectivity, it is difficult to obtain enough information through a single GNN layer as not only there are only few nodes directly connected to them but also can not propagate the high-order neighbor information. However, as the number of layer increases, the GNN model is prone to over-smooth for nodes with the dense connectivity, which resulting in the decrease of accuracy. To tackle this issue, in this thesis, we define a novel framework that allows the normal GNN model to accommodate more layers. Specifically, a node-degree based gate is employed to adjust weight of layers dynamically, that try to enhance the information aggregation ability and reduce the probability of over-smoothing. Experimental results show that our proposed model can effectively increase the model depth and perform well on several datasets.
LIAF-Net: Leaky Integrate and Analog Fire Network for Lightweight and Efficient Spatiotemporal Information Processing
Nov 12, 2020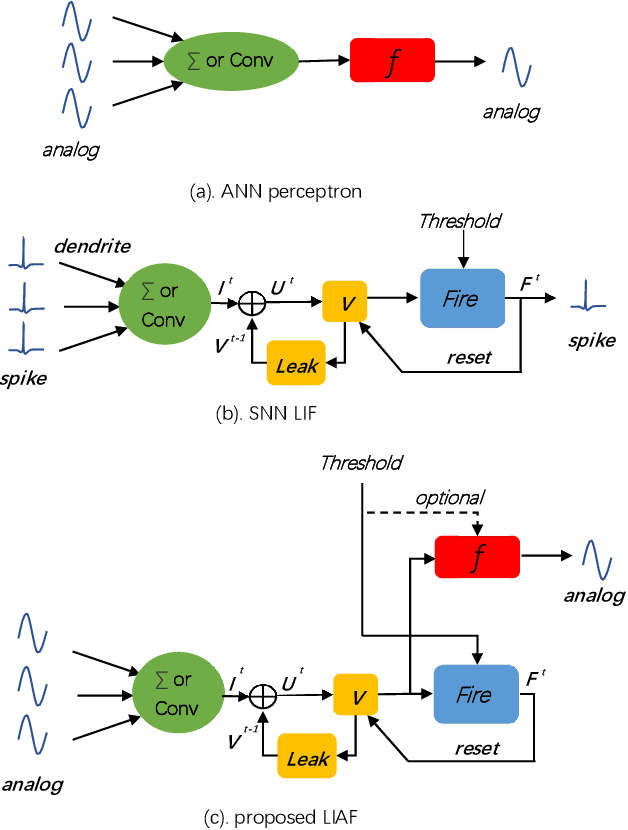
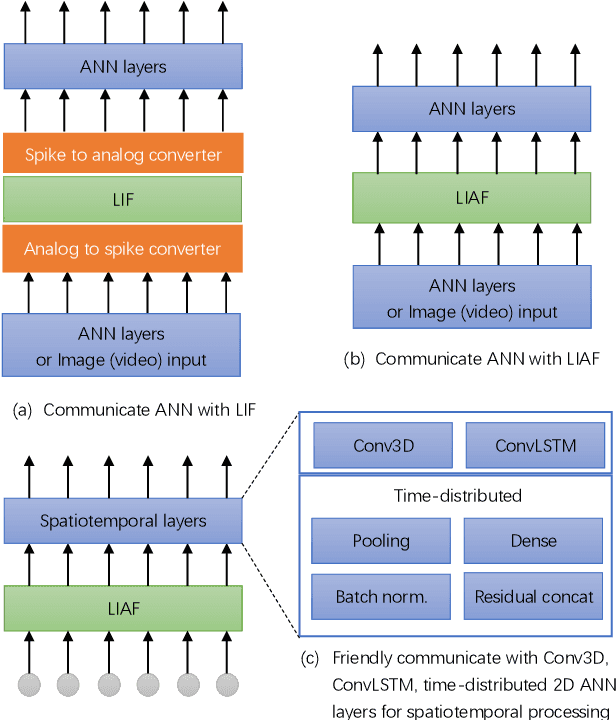
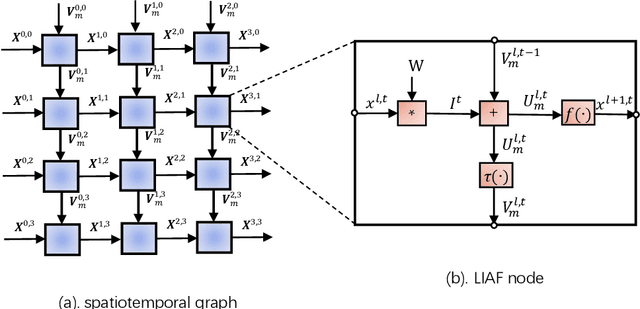
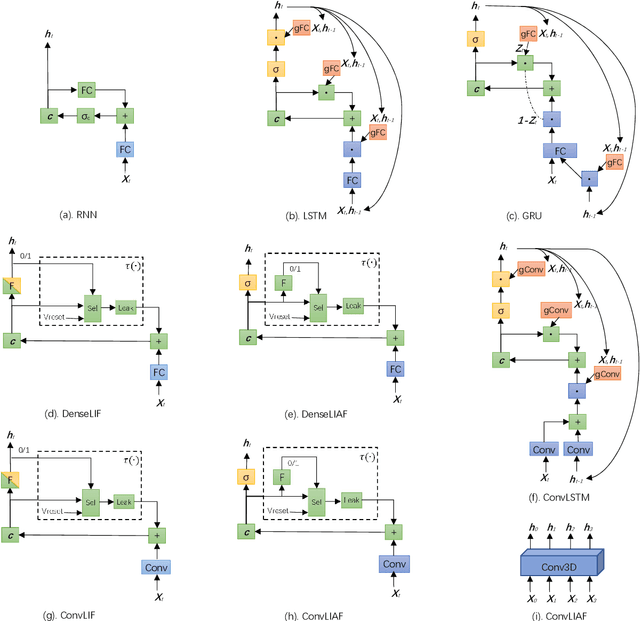
Spiking neural networks (SNNs) based on Leaky Integrate and Fire (LIF) model have been applied to energy-efficient temporal and spatiotemporal processing tasks. Thanks to the bio-plausible neuronal dynamics and simplicity, LIF-SNN benefits from event-driven processing, however, usually faces the embarrassment of reduced performance. This may because in LIF-SNN the neurons transmit information via spikes. To address this issue, in this work, we propose a Leaky Integrate and Analog Fire (LIAF) neuron model, so that analog values can be transmitted among neurons, and a deep network termed as LIAF-Net is built on it for efficient spatiotemporal processing. In the temporal domain, LIAF follows the traditional LIF dynamics to maintain its temporal processing capability. In the spatial domain, LIAF is able to integrate spatial information through convolutional integration or fully-connected integration. As a spatiotemporal layer, LIAF can also be used with traditional artificial neural network (ANN) layers jointly. Experiment results indicate that LIAF-Net achieves comparable performance to Gated Recurrent Unit (GRU) and Long short-term memory (LSTM) on bAbI Question Answering (QA) tasks, and achieves state-of-the-art performance on spatiotemporal Dynamic Vision Sensor (DVS) datasets, including MNIST-DVS, CIFAR10-DVS and DVS128 Gesture, with much less number of synaptic weights and computational overhead compared with traditional networks built by LSTM, GRU, Convolutional LSTM (ConvLSTM) or 3D convolution (Conv3D). Compared with traditional LIF-SNN, LIAF-Net also shows dramatic accuracy gain on all these experiments. In conclusion, LIAF-Net provides a framework combining the advantages of both ANNs and SNNs for lightweight and efficient spatiotemporal information processing.
Unsupervised Learning for Cell-level Visual Representation in Histopathology Images with Generative Adversarial Networks
Jul 07, 2018


The visual attributes of cells, such as the nuclear morphology and chromatin openness, are critical for histopathology image analysis. By learning cell-level visual representation, we can obtain a rich mix of features that are highly reusable for various tasks, such as cell-level classification, nuclei segmentation, and cell counting. In this paper, we propose a unified generative adversarial networks architecture with a new formulation of loss to perform robust cell-level visual representation learning in an unsupervised setting. Our model is not only label-free and easily trained but also capable of cell-level unsupervised classification with interpretable visualization, which achieves promising results in the unsupervised classification of bone marrow cellular components. Based on the proposed cell-level visual representation learning, we further develop a pipeline that exploits the varieties of cellular elements to perform histopathology image classification, the advantages of which are demonstrated on bone marrow datasets.