 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPM : A Pre-trained Plug-in Model for Click-through Rate Prediction
Mar 15, 2024



Click-through rate (CTR) prediction is a core task in recommender systems. Existing methods (IDRec for short) rely on unique identities to represent distinct users and items that have prevailed for decades. On one hand, IDRec often faces significant performance degradation on cold-start problem; on the other hand, IDRec cannot use longer training data due to constraints imposed by iteration efficiency. Most prior studies alleviate the above problems by introducing pre-trained knowledge(e.g. pre-trained user model or multi-modal embeddings). However, the explosive growth of online latency can be attributed to the huge parameters in the pre-trained model. Therefore, most of them cannot employ the unified model of end-to-end training with IDRec in industrial recommender systems, thus limiting the potential of the pre-trained model. To this end, we propose a $\textbf{P}$re-trained $\textbf{P}$lug-in CTR $\textbf{M}$odel, namely PPM. PPM employs multi-modal features as input and utilizes large-scale data for pre-training. Then, PPM is plugged in IDRec model to enhance unified model's performance and iteration efficiency. Upon incorporating IDRec model, certain intermediate results within the network are cached, with only a subset of the parameters participating in training and serving. Hence, our approach can successfully deploy an end-to-end model without causing huge latency increases. Comprehensive offline experiments and online A/B testing at JD E-commerce demonstrate the efficiency and effectiveness of PPM.
Confidence Ranking for CTR Prediction
Jun 28, 2023Model evolution and constant availability of data are two common phenomena in large-scale real-world machine learning applications, e.g. ads and recommendation systems. To adapt, the real-world system typically retrain with all available data and online learn with recently available data to update the models periodically with the goal of better serving performance. In this paper, we propose a novel framework, named Confidence Ranking, which designs the optimization objective as a ranking function with two different models. Our confidence ranking loss allows direct optimization of the logits output for different convex surrogate functions of metrics, e.g. AUC and Accuracy depending on the target task and dataset. Armed with our proposed methods, our experiments show that the introduction of confidence ranking loss can outperform all baselines on the CTR prediction tasks of public and industrial datasets. This framework has been deployed in the advertisement system of JD.com to serve the main traffic in the fine-rank stage.
Always Strengthen Your Strengths: A Drift-Aware Incremental Learning Framework for CTR Prediction
Apr 17, 2023Click-through rate (CTR) prediction is of great importance in recommendation systems and online advertising platforms. When served in industrial scenarios, the user-generated data observed by the CTR model typically arrives as a stream. Streaming data has the characteristic that the underlying distribution drifts over time and may recur. This can lead to catastrophic forgetting if the model simply adapts to new data distribution all the time. Also, it's inefficient to relearn distribution that has been occurred. Due to memory constraints and diversity of data distributions in large-scale industrial applications, conventional strategies for catastrophic forgetting such as replay, parameter isolation, and knowledge distillation are difficult to be deployed. In this work, we design a novel drift-aware incremental learning framework based on ensemble learning to address catastrophic forgetting in CTR prediction. With explicit error-based drift detection on streaming data, the framework further strengthens well-adapted ensembles and freezes ensembles that do not match the input distribution avoiding catastrophic interference. Both evaluations on offline experiments and A/B test shows that our method outperforms all baselines considered.
A Pre-Computing Solution for Online Advertising Serving
Jul 04, 2022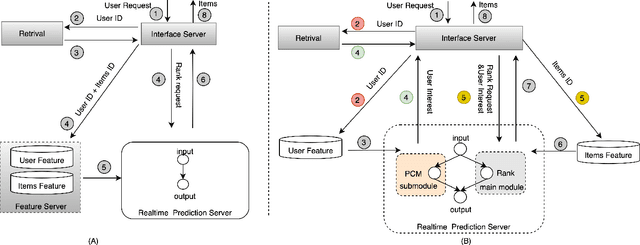

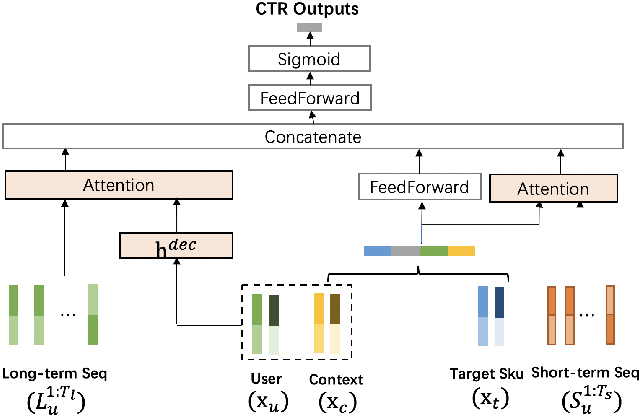
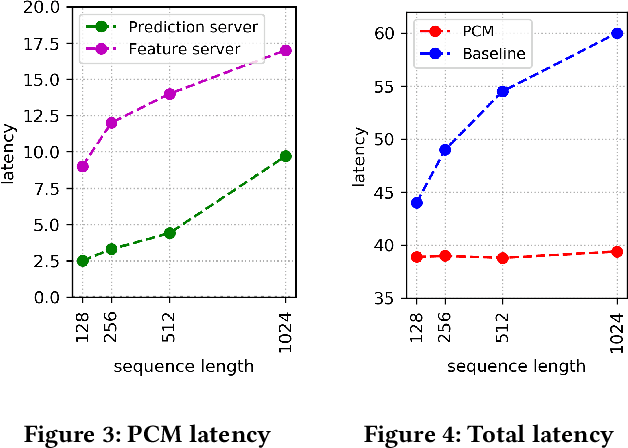
Click-Through Rate (CTR) prediction plays a key role in online advertising systems and online advertising. Constrained by strict requirements on online inference efficiency, it is often difficult to deploy useful but computationally intensive modules such as long-term behaviors modeling. Most recent works attempt to mitigate the online calculation issue of long historical behaviors by adopting two-stage methods to balance online efficiency and effectiveness. However, the information gaps caused by two-stage modeling may result in a diminished performance gain. In this work, we propose a novel framework called PCM to address this challenge in the view of system deployment. By deploying a pre-computing sub-module parallel to the retrieval stage, our PCM effectively reduces overall inference time which enables complex modeling in the ranking stage. Comprehensive offline and online experiments are conducted on the long-term user behaviors module to validate the effectiveness of our solution for the complex models. Moreover, our framework has been deployed into a large-scale real-world E-commerce system serving the main interface of hundreds of millions of active users, by deploying long sequential user behavior model in PCM. We achieved a 3\% CTR gain, with almost no increase in the ranking latency, compared to the base framework demonstrated from the online A/B test. To our knowledge, we are the first to propose an end-to-end solution for online training and deployment on complex CTR models from the system framework side.
NDGGNET-A Node Independent Gate based Graph Neural Networks
May 11, 2022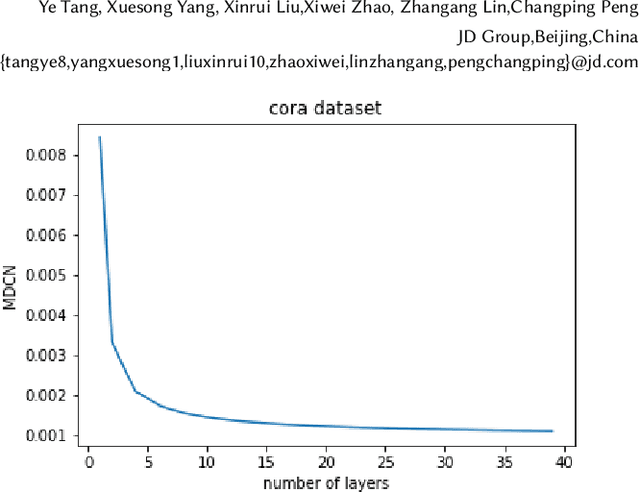
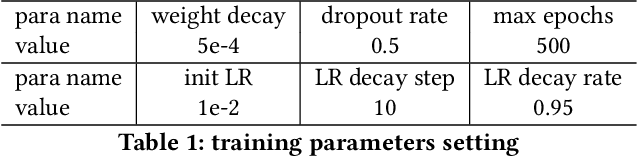
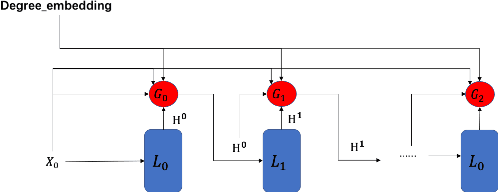
Graph Neural Networks (GNNs) is an architecture for structural data, and has been adopted in a mass of tasks and achieved fabulous results, such as link prediction, node classification, graph classification and so on. Generally, for a certain node in a given graph, a traditional GNN layer can be regarded as an aggregation from one-hop neighbors, thus a set of stacked layers are able to fetch and update node status within multi-hops. For nodes with sparse connectivity, it is difficult to obtain enough information through a single GNN layer as not only there are only few nodes directly connected to them but also can not propagate the high-order neighbor information. However, as the number of layer increases, the GNN model is prone to over-smooth for nodes with the dense connectivity, which resulting in the decrease of accuracy. To tackle this issue, in this thesis, we define a novel framework that allows the normal GNN model to accommodate more layers. Specifically, a node-degree based gate is employed to adjust weight of layers dynamically, that try to enhance the information aggregation ability and reduce the probability of over-smoothing. Experimental results show that our proposed model can effectively increase the model depth and perform well on several datasets.
IA-GCN: Interactive Graph Convolutional Network for Recommendation
Apr 08, 2022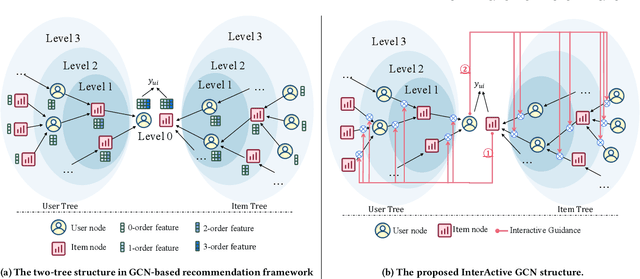

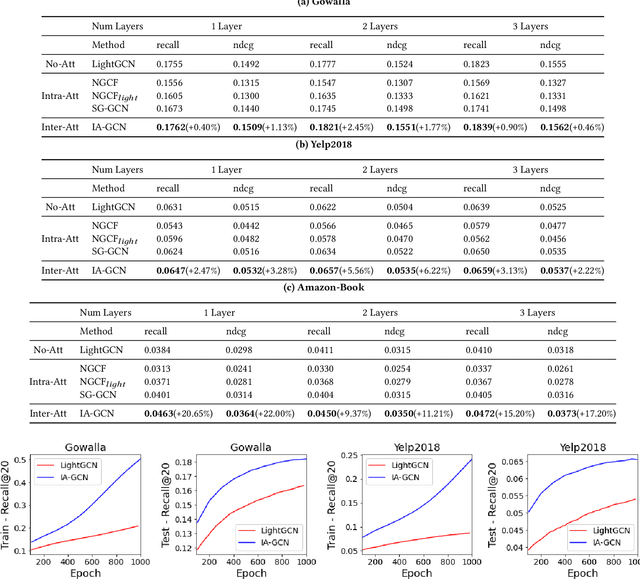
Recently, Graph Convolutional Network (GCN) has become a novel state-of-art for Collaborative Filtering (CF) based Recommender Systems (RS). It is a common practice to learn informative user and item representations by performing embedding propagation on a user-item bipartite graph, and then provide the users with personalized item suggestions based on the representations. Despite effectiveness, existing algorithms neglect precious interactive features between user-item pairs in the embedding process. When predicting a user's preference for different items, they still aggregate the user tree in the same way, without emphasizing target-related information in the user neighborhood. Such a uniform aggregation scheme easily leads to suboptimal user and item representations, limiting the model expressiveness to some extent. In this work, we address this problem by building bilateral interactive guidance between each user-item pair and proposing a new model named IA-GCN (short for InterActive GCN). Specifically, when learning the user representation from its neighborhood, we assign higher attention weights to those neighbors similar to the target item. Correspondingly, when learning the item representation, we pay more attention to those neighbors resembling the target user. This leads to interactive and interpretable features, effectively distilling target-specific information through each graph convolutional operation. Our model is built on top of LightGCN, a state-of-the-art GCN model for CF, and can be combined with various GCN-based CF architectures in an end-to-end fashion. Extensive experiments on three benchmark datasets demonstrate the effectiveness and robustness of IA-GCN.
Rethinking Position Bias Modeling with Knowledge Distillation for CTR Prediction
Apr 01, 2022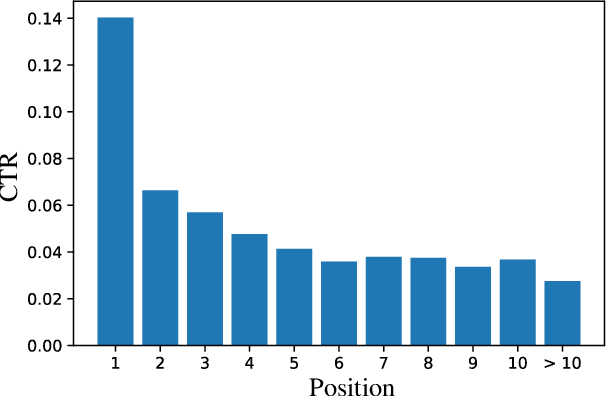
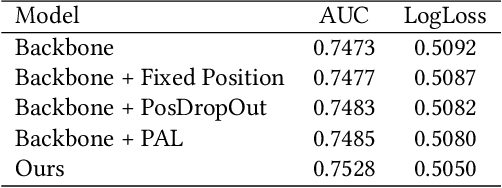
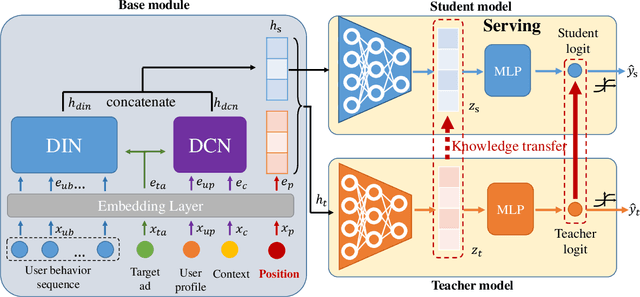
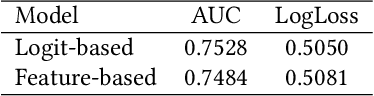
Click-through rate (CTR) Prediction is of great importance in real-world online ads systems. One challenge for the CTR prediction task is to capture the real interest of users from their clicked items, which is inherently biased by presented positions of items, i.e., more front positions tend to obtain higher CTR values. A popular line of existing works focuses on explicitly estimating position bias by result randomization which is expensive and inefficient, or by inverse propensity weighting (IPW) which relies heavily on the quality of the propensity estimation. Another common solution is modeling position as features during offline training and simply adopting fixed value or dropout tricks when serving. However, training-inference inconsistency can lead to sub-optimal performance. Furthermore, post-click information such as position values is informative while less exploited in CTR prediction. This work proposes a simple yet efficient knowledge distillation framework to alleviate the impact of position bias and leverage position information to improve CTR prediction. We demonstrate the performance of our proposed method on a real-world production dataset and online A/B tests, achieving significant improvements over competing baseline models. The proposed method has been deployed in the real world online ads systems, serving main traffic on one of the world's largest e-commercial platforms.
Concept Drift Adaptation for CTR Prediction in Online Advertising Systems
Apr 01, 2022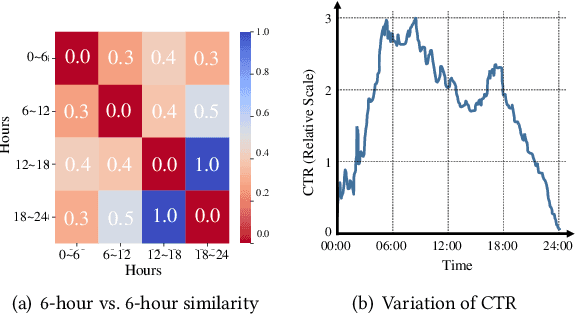
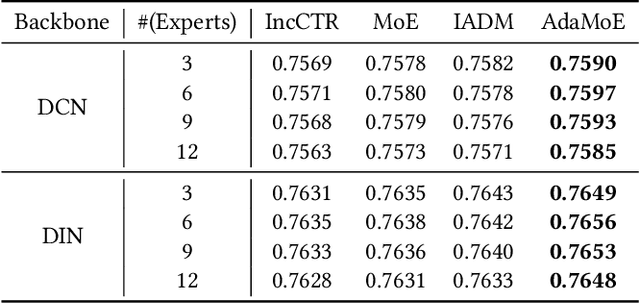
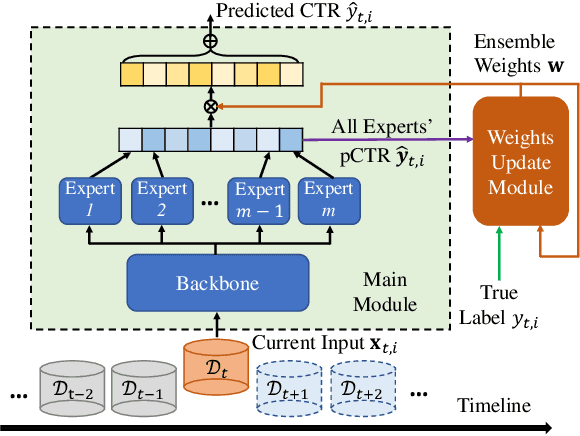
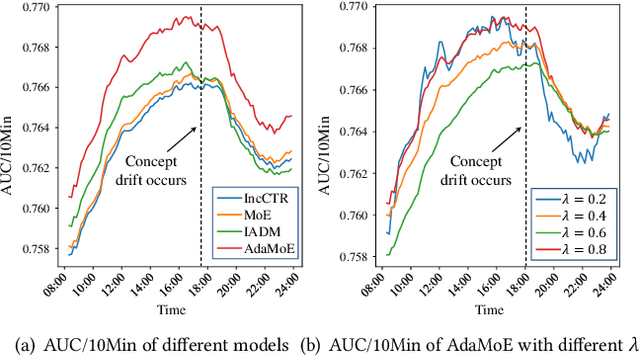
Click-through rate (CTR) prediction is a crucial task in web search, recommender systems, and online advertisement displaying. In practical application, CTR models often serve with high-speed user-generated data streams, whose underlying distribution rapidly changing over time. The concept drift problem inevitably exists in those streaming data, which can lead to performance degradation due to the timeliness issue. To ensure model freshness, incremental learning has been widely adopted in real-world production systems. However, it is hard for the incremental update to achieve the balance of the CTR models between the adaptability to capture the fast-changing trends and generalization ability to retain common knowledge. In this paper, we propose adaptive mixture of experts (AdaMoE), a new framework to alleviate the concept drift problem by adaptive filtering in the data stream of CTR prediction. The extensive experiments on the offline industrial dataset and online A/B tests show that our AdaMoE significantly outperforms all incremental learning frameworks considered.
Dynamic Parameterized Network for CTR Prediction
Nov 09, 2021
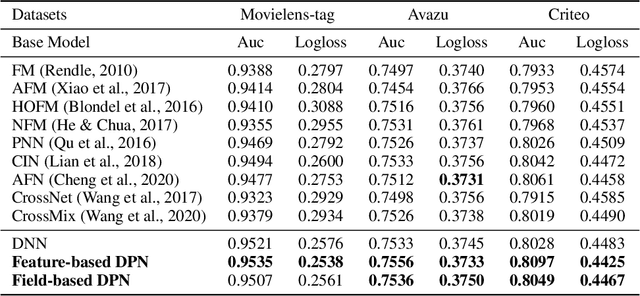
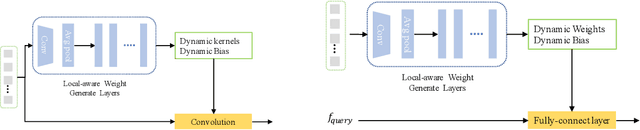

Learning to capture feature relations effectively and efficiently is essential in click-through rate (CTR) prediction of modern recommendation systems. Most existing CTR prediction methods model such relations either through tedious manually-designed low-order interactions or through inflexible and inefficient high-order interactions, which both require extra DNN modules for implicit interaction modeling. In this paper, we proposed a novel plug-in operation, Dynamic Parameterized Operation (DPO), to learn both explicit and implicit interaction instance-wisely. We showed that the introduction of DPO into DNN modules and Attention modules can respectively benefit two main tasks in CTR prediction, enhancing the adaptiveness of feature-based modeling and improving user behavior modeling with the instance-wise locality. Our Dynamic Parameterized Networks significantly outperforms state-of-the-art methods in the offline experiments on the public dataset and real-world production dataset, together with an online A/B test. Furthermore, the proposed Dynamic Parameterized Networks has been deployed in the ranking system of one of the world's largest e-commerce companies, serving the main traffic of hundreds of millions of active users.
Kalman Filtering Attention for User Behavior Modeling in CTR Prediction
Oct 20, 2020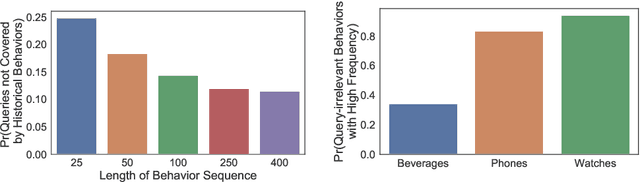


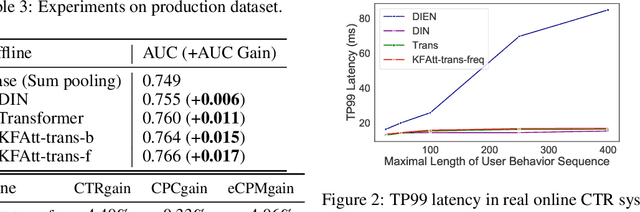
Click-through rate (CTR) prediction is one of the fundamental tasks for e-commerce search engines. As search becomes more personalized, it is necessary to capture the user interest from rich behavior data. Existing user behavior modeling algorithms develop different attention mechanisms to emphasize query-relevant behaviors and suppress irrelevant ones. Despite being extensively studied, these attentions still suffer from two limitations. First, conventional attentions mostly limit the attention field only to a single user's behaviors, which is not suitable in e-commerce where users often hunt for new demands that are irrelevant to any historical behaviors. Second, these attentions are usually biased towards frequent behaviors, which is unreasonable since high frequency does not necessarily indicate great importance. To tackle the two limitations, we propose a novel attention mechanism, termed Kalman Filtering Attention (KFAtt), that considers the weighted pooling in attention as a maximum a posteriori (MAP) estimation. By incorporating a priori, KFAtt resorts to global statistics when few user behaviors are relevant. Moreover, a frequency capping mechanism is incorporated to correct the bias towards frequent behaviors. Offline experiments on both benchmark and a 10 billion scale real production dataset, together with an Online A/B test, show that KFAtt outperforms all compared state-of-the-arts. KFAtt has been deployed in the ranking system of a leading e commerce website, serving the main traffic of hundreds of millions of active users everyday.