 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Position Bias Modeling with Knowledge Distillation for CTR Prediction
Paper and Code
Apr 01, 2022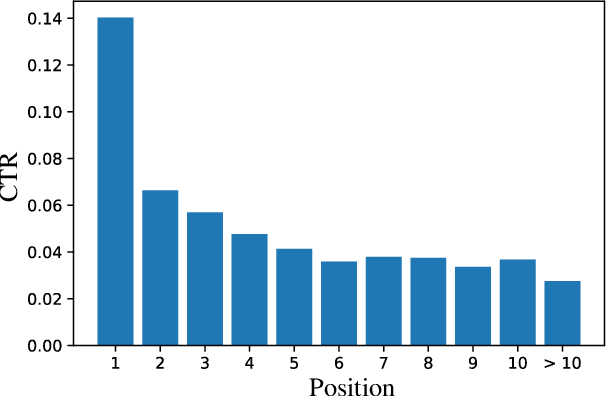
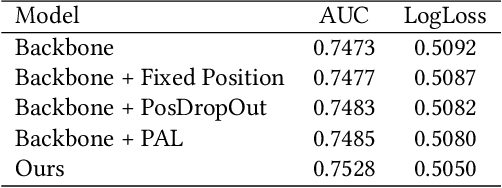
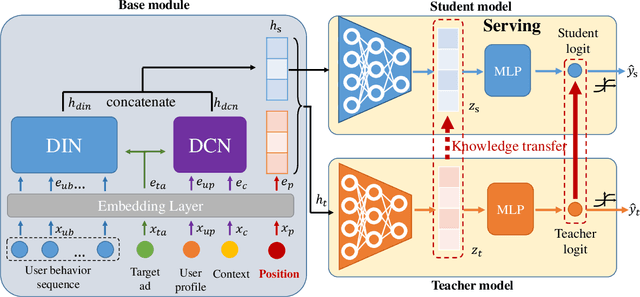
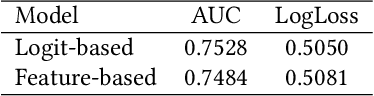
Click-through rate (CTR) Prediction is of great importance in real-world online ads systems. One challenge for the CTR prediction task is to capture the real interest of users from their clicked items, which is inherently biased by presented positions of items, i.e., more front positions tend to obtain higher CTR values. A popular line of existing works focuses on explicitly estimating position bias by result randomization which is expensive and inefficient, or by inverse propensity weighting (IPW) which relies heavily on the quality of the propensity estimation. Another common solution is modeling position as features during offline training and simply adopting fixed value or dropout tricks when serving. However, training-inference inconsistency can lead to sub-optimal performance. Furthermore, post-click information such as position values is informative while less exploited in CTR prediction. This work proposes a simple yet efficient knowledge distillation framework to alleviate the impact of position bias and leverage position information to improve CTR prediction. We demonstrate the performance of our proposed method on a real-world production dataset and online A/B tests, achieving significant improvements over competing baseline models. The proposed method has been deployed in the real world online ads systems, serving main traffic on one of the world's largest e-commercial platforms.