 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search
May 24, 2024Re-ranking is a process of rearranging ranking list to more effectively meet user demands by accounting for the interrelationships between items. Existing methods predominantly enhance the precision of search results, often at the expense of diversity, leading to outcomes that may not fulfill the varied needs of users. Conversely, methods designed to promote diversity might compromise the precision of the results, failing to satisfy the users' requirements for accuracy. To alleviate the above problems, this paper proposes a Preference-oriented Diversity Model Based on Mutual-information (PODM-MI), which consider both accuracy and diversity in the re-ranking process. Specifically, PODM-MI adopts Multidimensional Gaussian distributions based on variational inference to capture users' diversity preferences with uncertainty. Then we maximize the mutual information between the diversity preferences of the users and the candidate items using the maximum variational inference lower bound to enhance their correlations. Subsequently, we derive a utility matrix based on the correlations, enabling the adaptive ranking of items in line with user preferences and establishing a balance between the aforementioned objectives. Experimental results on real-world online e-commerce systems demonstrate the significant improvements of PODM-MI, and we have successfully deployed PODM-MI on an e-commerce search platform.
PPM : A Pre-trained Plug-in Model for Click-through Rate Prediction
Mar 15, 2024



Click-through rate (CTR) prediction is a core task in recommender systems. Existing methods (IDRec for short) rely on unique identities to represent distinct users and items that have prevailed for decades. On one hand, IDRec often faces significant performance degradation on cold-start problem; on the other hand, IDRec cannot use longer training data due to constraints imposed by iteration efficiency. Most prior studies alleviate the above problems by introducing pre-trained knowledge(e.g. pre-trained user model or multi-modal embeddings). However, the explosive growth of online latency can be attributed to the huge parameters in the pre-trained model. Therefore, most of them cannot employ the unified model of end-to-end training with IDRec in industrial recommender systems, thus limiting the potential of the pre-trained model. To this end, we propose a $\textbf{P}$re-trained $\textbf{P}$lug-in CTR $\textbf{M}$odel, namely PPM. PPM employs multi-modal features as input and utilizes large-scale data for pre-training. Then, PPM is plugged in IDRec model to enhance unified model's performance and iteration efficiency. Upon incorporating IDRec model, certain intermediate results within the network are cached, with only a subset of the parameters participating in training and serving. Hence, our approach can successfully deploy an end-to-end model without causing huge latency increases. Comprehensive offline experiments and online A/B testing at JD E-commerce demonstrate the efficiency and effectiveness of PPM.
Rethinking Large-scale Pre-ranking System: Entire-chain Cross-domain Models
Oct 12, 2023Industrial systems such as recommender systems and online advertising, have been widely equipped with multi-stage architectures, which are divided into several cascaded modules, including matching, pre-ranking, ranking and re-ranking. As a critical bridge between matching and ranking, existing pre-ranking approaches mainly endure sample selection bias (SSB) problem owing to ignoring the entire-chain data dependence, resulting in sub-optimal performances. In this paper, we rethink pre-ranking system from the perspective of the entire sample space, and propose Entire-chain Cross-domain Models (ECM), which leverage samples from the whole cascaded stages to effectively alleviate SSB problem. Besides, we design a fine-grained neural structure named ECMM to further improve the pre-ranking accuracy. Specifically, we propose a cross-domain multi-tower neural network to comprehensively predict for each stage result, and introduce the sub-networking routing strategy with $L0$ regularization to reduce computational costs. Evaluations on real-world large-scale traffic logs demonstrate that our pre-ranking models outperform SOTA methods while time consumption is maintained within an acceptable level, which achieves better trade-off between efficiency and effectiveness.
* 5 pages, 2 figures
Always Strengthen Your Strengths: A Drift-Aware Incremental Learning Framework for CTR Prediction
Apr 17, 2023Click-through rate (CTR) prediction is of great importance in recommendation systems and online advertising platforms. When served in industrial scenarios, the user-generated data observed by the CTR model typically arrives as a stream. Streaming data has the characteristic that the underlying distribution drifts over time and may recur. This can lead to catastrophic forgetting if the model simply adapts to new data distribution all the time. Also, it's inefficient to relearn distribution that has been occurred. Due to memory constraints and diversity of data distributions in large-scale industrial applications, conventional strategies for catastrophic forgetting such as replay, parameter isolation, and knowledge distillation are difficult to be deployed. In this work, we design a novel drift-aware incremental learning framework based on ensemble learning to address catastrophic forgetting in CTR prediction. With explicit error-based drift detection on streaming data, the framework further strengthens well-adapted ensembles and freezes ensembles that do not match the input distribution avoiding catastrophic interference. Both evaluations on offline experiments and A/B test shows that our method outperforms all baselines considered.
CBNet: A Plug-and-Play Network for Segmentation-based Scene Text Detection
Dec 19, 2022Recently, segmentation-based methods are quite popular in scene text detection, which mainly contain two steps: text kernel segmentation and expansion. However, the segmentation process only considers each pixel independently, and the expansion process is difficult to achieve a favorable accuracy-speed trade-off. In this paper, we propose a Context-aware and Boundary-guided Network (CBN) to tackle these problems. In CBN, a basic text detector is firstly used to predict initial segmentation results. Then, we propose a context-aware module to enhance text kernel feature representations, which considers both global and local contexts. Finally, we introduce a boundary-guided module to expand enhanced text kernels adaptively with only the pixels on the contours, which not only obtains accurate text boundaries but also keeps high speed, especially on high-resolution output maps. In particular, with a lightweight backbone, the basic detector equipped with our proposed CBN achieves state-of-the-art results on several popular benchmarks, and our proposed CBN can be plugged into several segmentation-based methods. Code will be available on https://github.com/XiiZhao/cbn.pytorch.
LADDER: A Human-Level Bidding Agent for Large-Scale Real-Time Online Auctions
Sep 01, 2017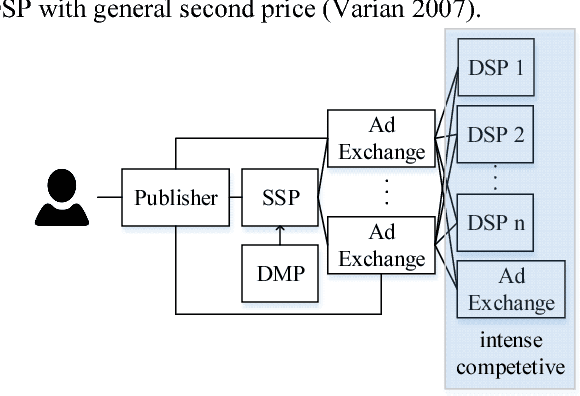
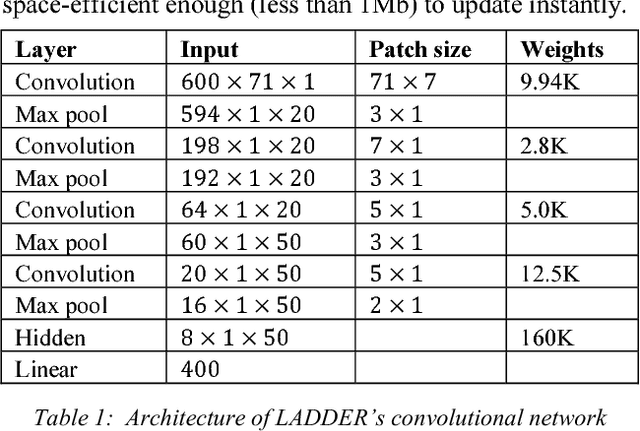
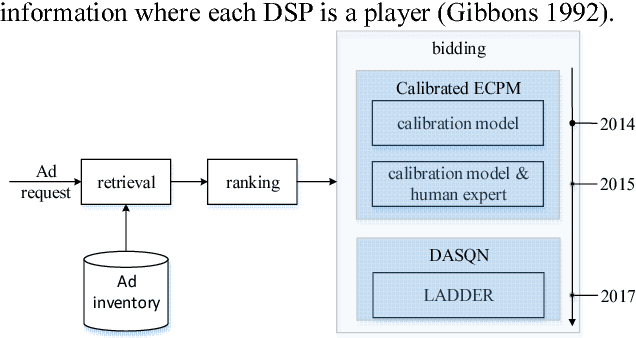
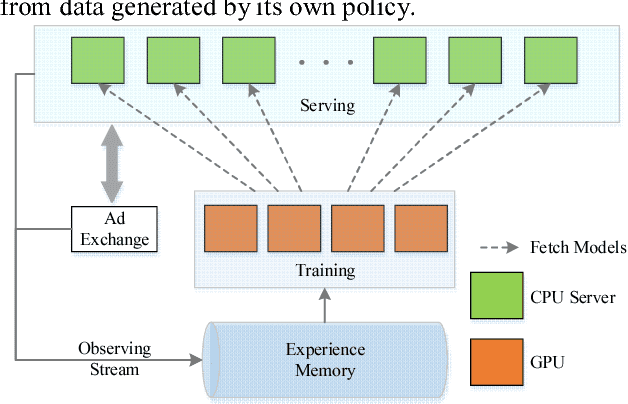
We present LADDER, the first deep reinforcement learning agent that can successfully learn control policies for large-scale real-world problems directly from raw inputs composed of high-level semantic information. The agent is based on an asynchronous stochastic variant of DQN (Deep Q Network) named DASQN. The inputs of the agent are plain-text descriptions of states of a game of incomplete information, i.e. real-time large scale online auctions, and the rewards are auction profits of very large scale. We apply the agent to an essential portion of JD's online RTB (real-time bidding) advertising business and find that it easily beats the former state-of-the-art bidding policy that had been carefully engineered and calibrated by human experts: during JD.com's June 18th anniversary sale, the agent increased the company's ads revenue from the portion by more than 50%, while the advertisers' ROI (return on investment) also improved significantly.
Optimizing Gross Merchandise Volume via DNN-MAB Dynamic Ranking Paradigm
Aug 14, 2017
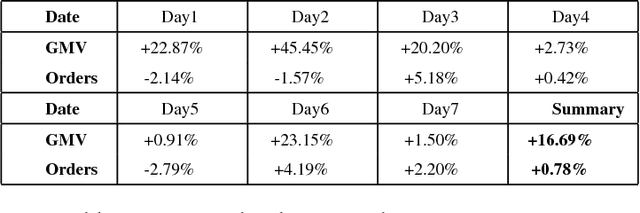
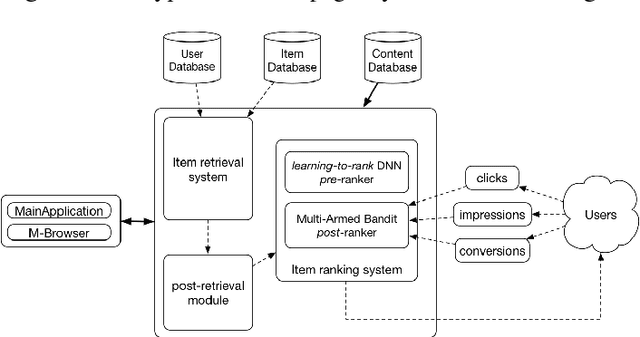
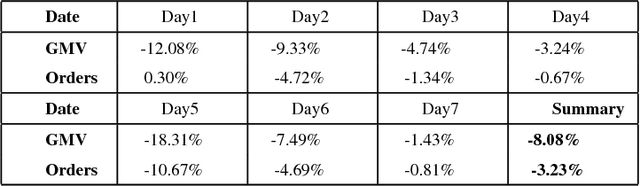
With the transition from people's traditional `brick-and-mortar' shopping to online mobile shopping patterns in web 2.0 $\mathit{era}$, the recommender system plays a critical role in E-Commerce and E-Retails. This is especially true when designing this system for more than $\mathbf{236~million}$ daily active users. Ranking strategy, the key module of the recommender system, needs to be precise, accurate, and responsive for estimating customers' intents. We propose a dynamic ranking paradigm, named as DNN-MAB, that is composed of a pairwise deep neural network (DNN) $\mathit{pre}$-ranker connecting a revised multi-armed bandit (MAB) dynamic $\mathit{post}$-ranker. By taking into account of explicit and implicit user feedbacks such as impressions, clicks, conversions, etc. DNN-MAB is able to adjust DNN $\mathit{pre}$-ranking scores to assist customers locating items they are interested in most so that they can converge quickly and frequently. To the best of our knowledge, frameworks like DNN-MAB have not been discussed in the previous literature to either E-Commerce or machine learning audiences. In practice, DNN-MAB has been deployed to production and it easily outperforms against other state-of-the-art models by significantly lifting the gross merchandise volume (GMV) which is the objective metrics at JD.