 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison Lift: Bandit-based Experimentation System for Online Advertising
Sep 16, 2020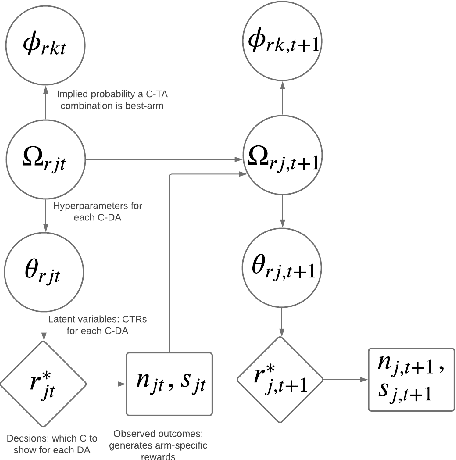
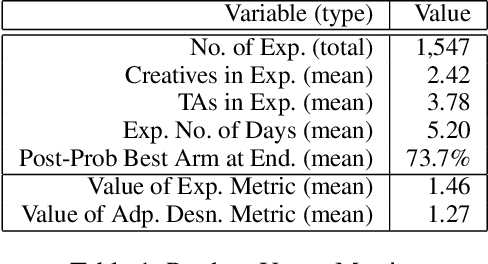
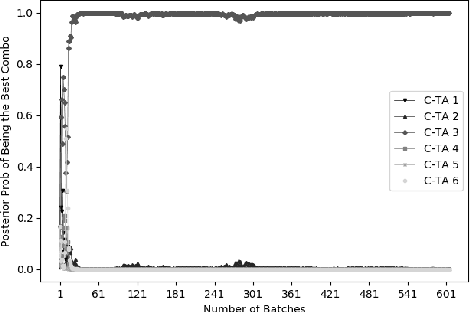
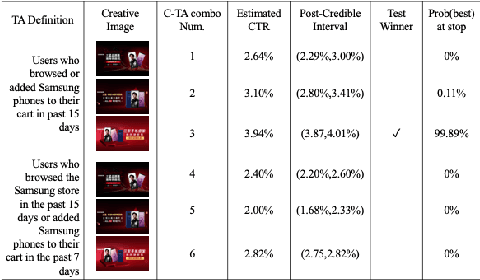
Comparison Lift is an experimentation-as-a-service (EaaS) application for testing online advertising audiences and creatives at JD.com. Unlike many other EaaS tools that focus primarily on fixed sample A/B testing, Comparison Lift deploys a custom bandit-based experimentation algorithm. The advantages of the bandit-based approach are two-fold. First, it aligns the randomization induced in the test with the advertiser's goals from testing. Second, by adapting experimental design to information acquired during the test, it reduces substantially the cost of experimentation to the advertiser. Since launch in May 2019, Comparison Lift has been utilized in over 1,500 experiments. We estimate that utilization of the product has helped increase click-through rates of participating advertising campaigns by 46% on average. We estimate that the adaptive design in the product has generated 27% more clicks on average during testing compared to a fixed sample A/B design. Both suggest significant value generation and cost savings to advertisers from the product.
Multi-agent Reinforcement Learning Embedded Game for the Optimization of Building Energy Control and Power System Planning
Jan 17, 2019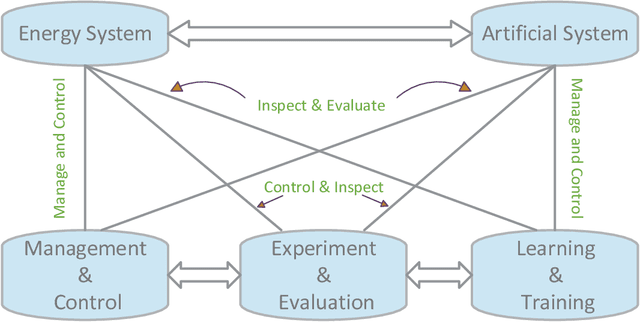
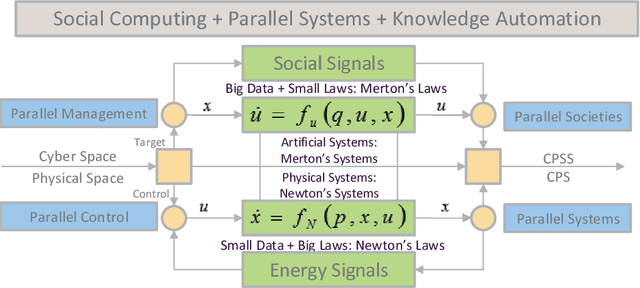
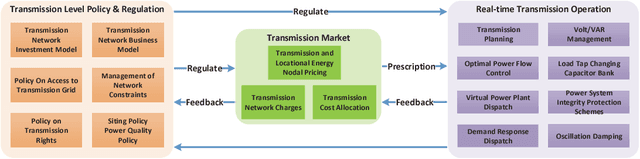
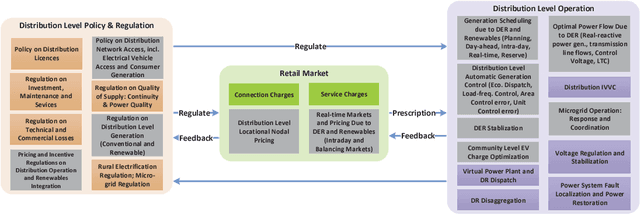
Most of the current game-theoretic demand-side management methods focus primarily on the scheduling of home appliances, and the related numerical experiments are analyzed under various scenarios to achieve the corresponding Nash-equilibrium (NE) and optimal results. However, not much work is conducted for academic or commercial buildings. The methods for optimizing academic-buildings are distinct from the optimal methods for home appliances. In my study, we address a novel methodology to control the operation of heating, ventilation, and air conditioning system (HVAC). With the development of Artificial Intelligence and computer technologies, reinforcement learning (RL) can be implemented in multiple realistic scenarios and help people to solve thousands of real-world problems. Reinforcement Learning, which is considered as the art of future AI, builds the bridge between agents and environments through Markov Decision Chain or Neural Network and has seldom been used in power system. The art of RL is that once the simulator for a specific environment is built, the algorithm can keep learning from the environment. Therefore, RL is capable of dealing with constantly changing simulator inputs such as power demand, the condition of power system and outdoor temperature, etc. Compared with the existing distribution power system planning mechanisms and the related game theoretical methodologies, our proposed algorithm can plan and optimize the hourly energy usage, and have the ability to corporate with even shorter time window if needed.
LADDER: A Human-Level Bidding Agent for Large-Scale Real-Time Online Auctions
Sep 01, 2017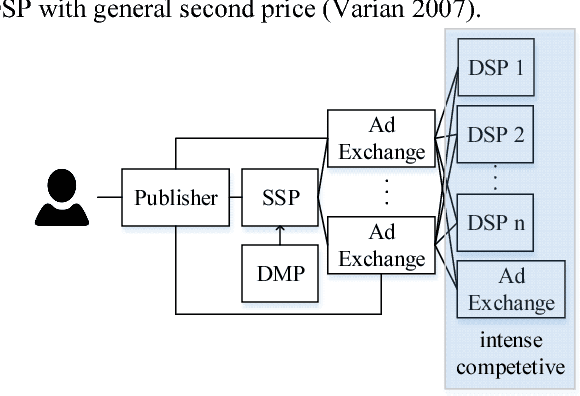
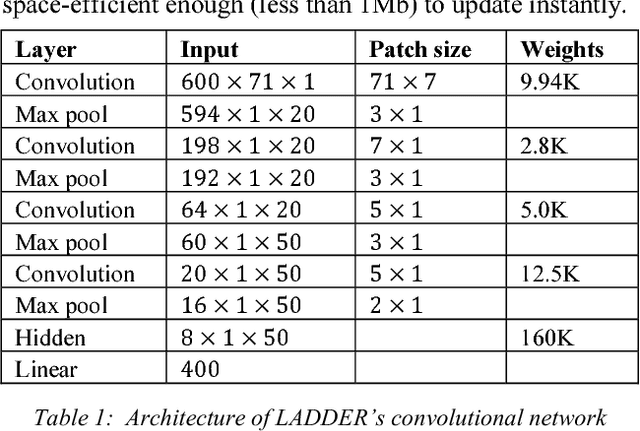
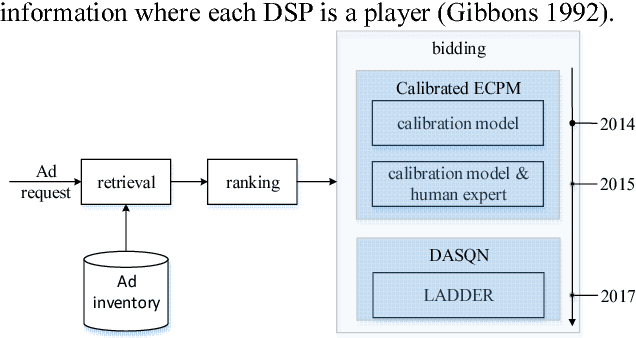
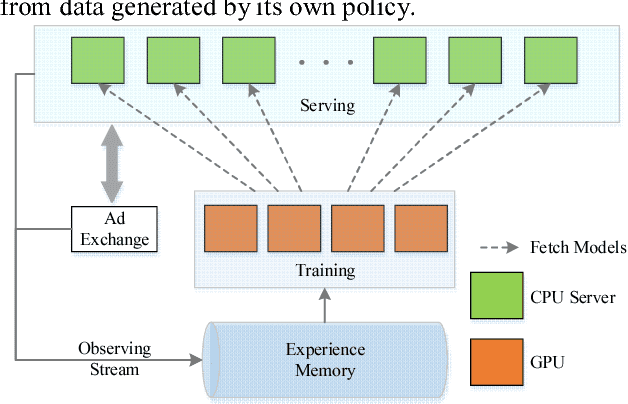
We present LADDER, the first deep reinforcement learning agent that can successfully learn control policies for large-scale real-world problems directly from raw inputs composed of high-level semantic information. The agent is based on an asynchronous stochastic variant of DQN (Deep Q Network) named DASQN. The inputs of the agent are plain-text descriptions of states of a game of incomplete information, i.e. real-time large scale online auctions, and the rewards are auction profits of very large scale. We apply the agent to an essential portion of JD's online RTB (real-time bidding) advertising business and find that it easily beats the former state-of-the-art bidding policy that had been carefully engineered and calibrated by human experts: during JD.com's June 18th anniversary sale, the agent increased the company's ads revenue from the portion by more than 50%, while the advertisers' ROI (return on investment) also improved significantly.