 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Large-scale Pre-ranking System: Entire-chain Cross-domain Models
Oct 12, 2023Industrial systems such as recommender systems and online advertising, have been widely equipped with multi-stage architectures, which are divided into several cascaded modules, including matching, pre-ranking, ranking and re-ranking. As a critical bridge between matching and ranking, existing pre-ranking approaches mainly endure sample selection bias (SSB) problem owing to ignoring the entire-chain data dependence, resulting in sub-optimal performances. In this paper, we rethink pre-ranking system from the perspective of the entire sample space, and propose Entire-chain Cross-domain Models (ECM), which leverage samples from the whole cascaded stages to effectively alleviate SSB problem. Besides, we design a fine-grained neural structure named ECMM to further improve the pre-ranking accuracy. Specifically, we propose a cross-domain multi-tower neural network to comprehensively predict for each stage result, and introduce the sub-networking routing strategy with $L0$ regularization to reduce computational costs. Evaluations on real-world large-scale traffic logs demonstrate that our pre-ranking models outperform SOTA methods while time consumption is maintained within an acceptable level, which achieves better trade-off between efficiency and effectiveness.
* 5 pages, 2 figures
Graph Attention Collaborative Similarity Embedding for Recommender System
Feb 05, 2021
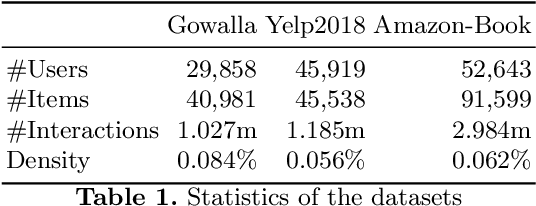

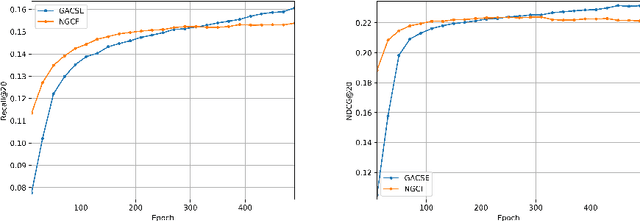
We present Graph Attention Collaborative Similarity Embedding (GACSE), a new recommendation framework that exploits collaborative information in the user-item bipartite graph for representation learning. Our framework consists of two parts: the first part is to learn explicit graph collaborative filtering information such as user-item association through embedding propagation with attention mechanism, and the second part is to learn implicit graph collaborative information such as user-user similarities and item-item similarities through auxiliary loss. We design a new loss function that combines BPR loss with adaptive margin and similarity loss for the similarities learning. Extensive experiments on three benchmarks show that our model is consistently better than the latest state-of-the-art models.