 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInv: A Novel Self-supervised Learning Approach for Fast and Accurate Diffusion Inversion
Jan 04, 2026Diffusion inversion is a task of recovering the noise of an image in a diffusion model, which is vital for controllable diffusion image editing. At present, diffusion inversion still remains a challenging task due to the lack of viable supervision signals. Thus, most existing methods resort to approximation-based solutions, which however are often at the cost of performance or efficiency. To remedy these shortcomings, we propose a novel self-supervised diffusion inversion approach in this paper, termed Deep Inversion (DeepInv). Instead of requiring ground-truth noise annotations, we introduce a self-supervised objective as well as a data augmentation strategy to generate high-quality pseudo noises from real images without manual intervention. Based on these two innovative designs, DeepInv is also equipped with an iterative and multi-scale training regime to train a parameterized inversion solver, thereby achieving the fast and accurate image-to-noise mapping. To the best of our knowledge, this is the first attempt of presenting a trainable solver to predict inversion noise step by step. The extensive experiments show that our DeepInv can achieve much better performance and inference speed than the compared methods, e.g., +40.435% SSIM than EasyInv and +9887.5% speed than ReNoise on COCO dataset. Moreover, our careful designs of trainable solvers can also provide insights to the community. Codes and model parameters will be released in https://github.com/potato-kitty/DeepInv.
Graph Attention Collaborative Similarity Embedding for Recommender System
Feb 05, 2021

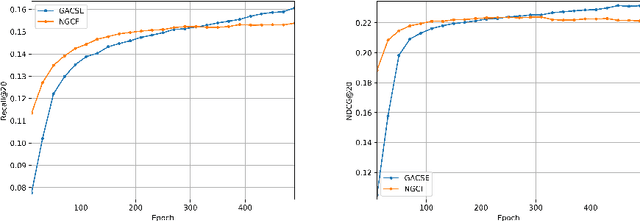
We present Graph Attention Collaborative Similarity Embedding (GACSE), a new recommendation framework that exploits collaborative information in the user-item bipartite graph for representation learning. Our framework consists of two parts: the first part is to learn explicit graph collaborative filtering information such as user-item association through embedding propagation with attention mechanism, and the second part is to learn implicit graph collaborative information such as user-user similarities and item-item similarities through auxiliary loss. We design a new loss function that combines BPR loss with adaptive margin and similarity loss for the similarities learning. Extensive experiments on three benchmarks show that our model is consistently better than the latest state-of-the-art models.