 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Incremental Update Framework for Online Recommenders with Data-Driven Prior
Dec 26, 2023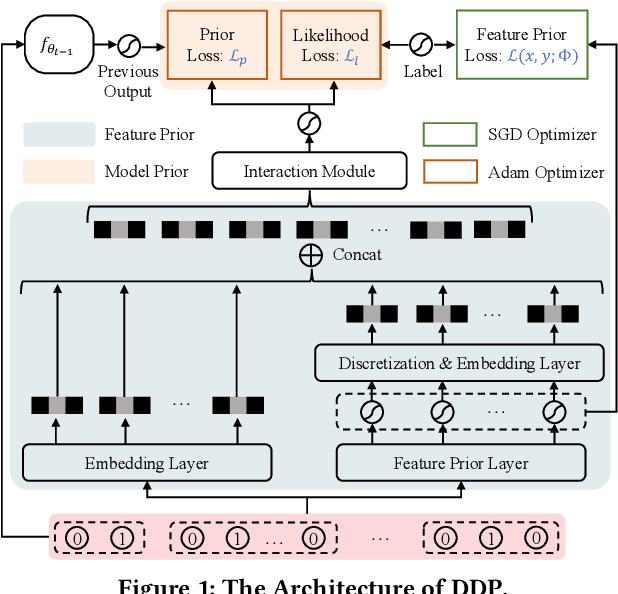
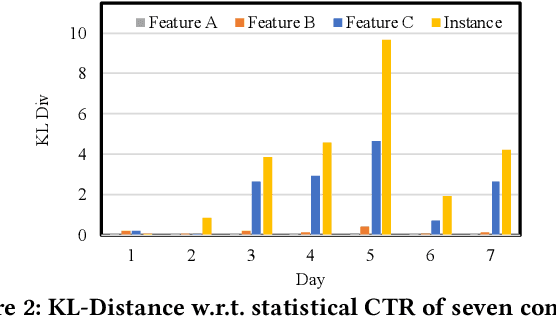
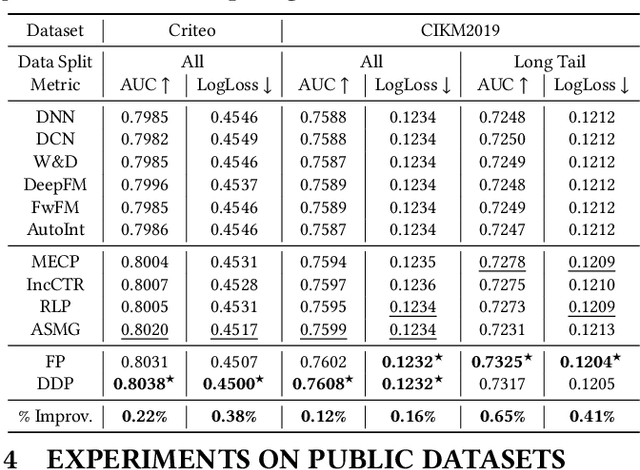
Online recommenders have attained growing interest and created great revenue for businesses. Given numerous users and items, incremental update becomes a mainstream paradigm for learning large-scale models in industrial scenarios, where only newly arrived data within a sliding window is fed into the model, meeting the strict requirements of quick response. However, this strategy would be prone to overfitting to newly arrived data. When there exists a significant drift of data distribution, the long-term information would be discarded, which harms the recommendation performance. Conventional methods address this issue through native model-based continual learning methods, without analyzing the data characteristics for online recommenders. To address the aforementioned issue, we propose an incremental update framework for online recommenders with Data-Driven Prior (DDP), which is composed of Feature Prior (FP) and Model Prior (MP). The FP performs the click estimation for each specific value to enhance the stability of the training process. The MP incorporates previous model output into the current update while strictly following the Bayes rules, resulting in a theoretically provable prior for the robust update. In this way, both the FP and MP are well integrated into the unified framework, which is model-agnostic and can accommodate various advanced interaction models. Extensive experiments on two publicly available datasets as well as an industrial dataset demonstrate the superior performance of the proposed framework.
Rethinking Large-scale Pre-ranking System: Entire-chain Cross-domain Models
Oct 12, 2023Industrial systems such as recommender systems and online advertising, have been widely equipped with multi-stage architectures, which are divided into several cascaded modules, including matching, pre-ranking, ranking and re-ranking. As a critical bridge between matching and ranking, existing pre-ranking approaches mainly endure sample selection bias (SSB) problem owing to ignoring the entire-chain data dependence, resulting in sub-optimal performances. In this paper, we rethink pre-ranking system from the perspective of the entire sample space, and propose Entire-chain Cross-domain Models (ECM), which leverage samples from the whole cascaded stages to effectively alleviate SSB problem. Besides, we design a fine-grained neural structure named ECMM to further improve the pre-ranking accuracy. Specifically, we propose a cross-domain multi-tower neural network to comprehensively predict for each stage result, and introduce the sub-networking routing strategy with $L0$ regularization to reduce computational costs. Evaluations on real-world large-scale traffic logs demonstrate that our pre-ranking models outperform SOTA methods while time consumption is maintained within an acceptable level, which achieves better trade-off between efficiency and effectiveness.
* 5 pages, 2 figures
Alleviating Cold-start Problem in CTR Prediction with A Variational Embedding Learning Framework
Jan 17, 2022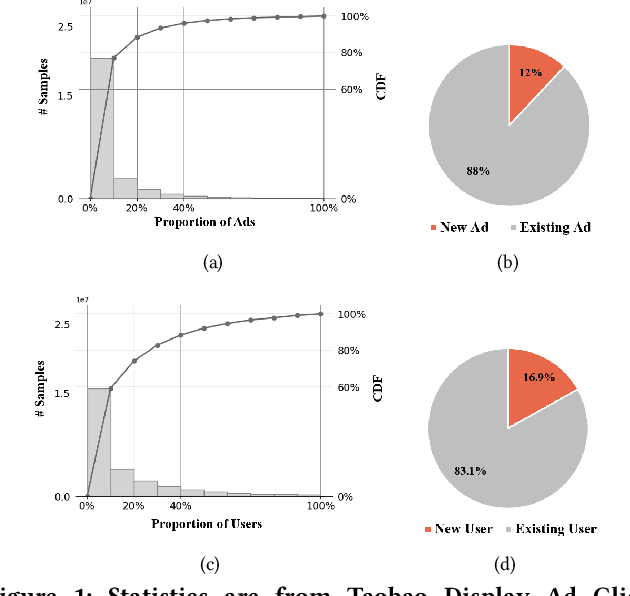

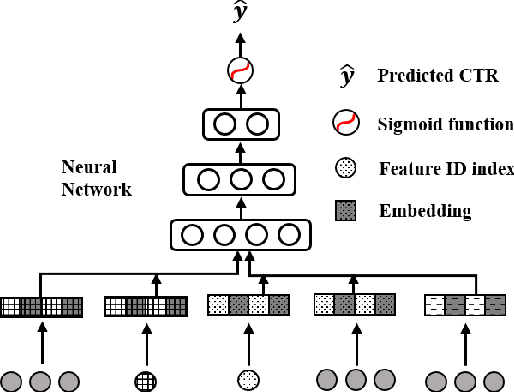
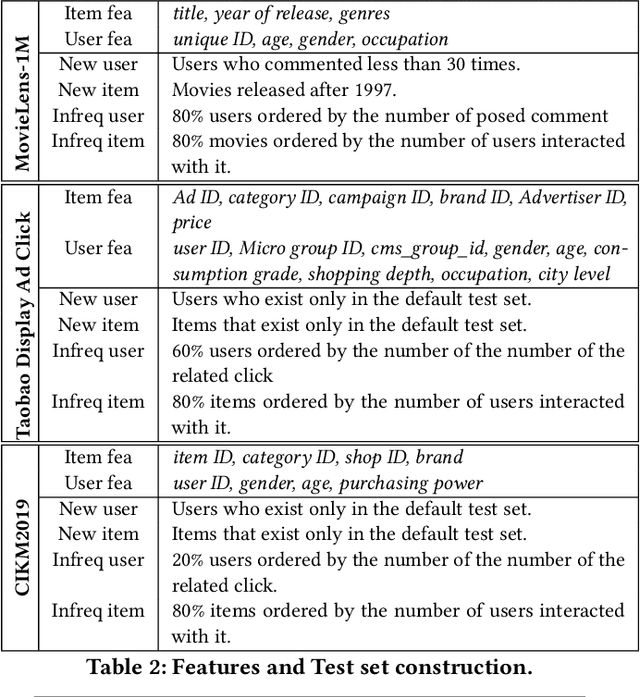
We propose a general Variational Embedding Learning Framework (VELF) for alleviating the severe cold-start problem in CTR prediction. VELF addresses the cold start problem via alleviating over-fits caused by data-sparsity in two ways: learning probabilistic embedding, and incorporating trainable and regularized priors which utilize the rich side information of cold start users and advertisements (Ads). The two techniques are naturally integrated into a variational inference framework, forming an end-to-end training process. Abundant empirical tests on benchmark datasets well demonstrate the advantages of our proposed VELF. Besides, extended experiments confirmed that our parameterized and regularized priors provide more generalization capability than traditional fixed priors.
LT4REC:A Lottery Ticket Hypothesis Based Multi-task Practice for Video Recommendation System
Aug 22, 2020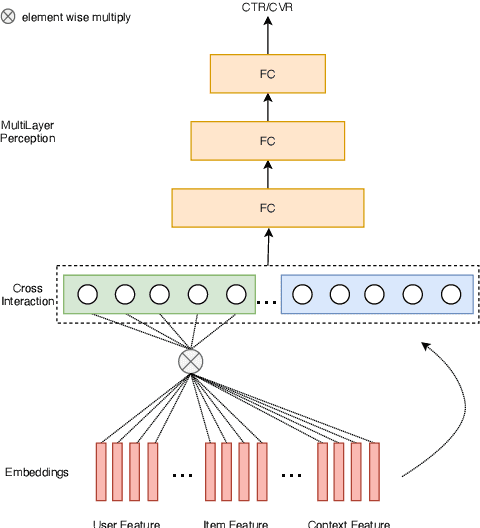

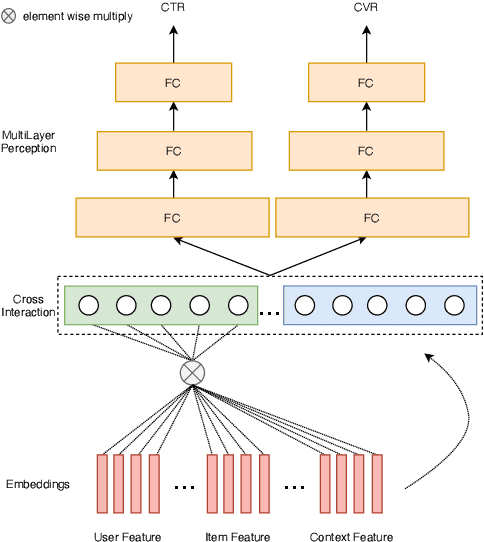
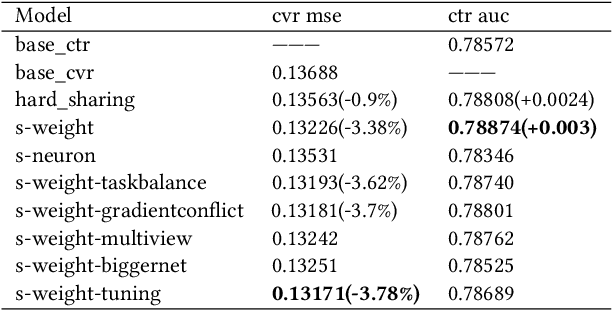
Click-through rate prediction (CTR) and post-click conversion rate prediction (CVR) play key roles across all industrial ranking systems, such as recommendation systems, online advertising, and search engines. Different from the extensive research on CTR, there is much less research on CVR estimation, whose main challenge is extreme data sparsity with one or two orders of magnitude reduction in the number of samples than CTR. People try to solve this problem with the paradigm of multi-task learning with the sufficient samples of CTR, but the typical hard sharing method can't effectively solve this problem, because it is difficult to analyze which parts of network components can be shared and which parts are in conflict, i.e., there is a large inaccuracy with artificially designed neurons sharing. In this paper, we model CVR in a brand-new method by adopting the lottery-ticket-hypothesis-based sparse sharing multi-task learning, which can automatically and flexibly learn which neuron weights to be shared without artificial experience. Experiments on the dataset gathered from traffic logs of Tencent video's recommendation system demonstrate that sparse sharing in the CVR model significantly outperforms competitive methods. Due to the nature of weight sparsity in sparse sharing, it can also significantly reduce computational complexity and memory usage which are very important in the industrial recommendation system.