 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Memory for Continual Logistic Regression
Nov 12, 2025Despite recent progress, continual learning still does not match the performance of batch training. To avoid catastrophic forgetting, we need to build compact memory of essential past knowledge, but no clear solution has yet emerged, even for shallow neural networks with just one or two layers. In this paper, we present a new method to build compact memory for logistic regression. Our method is based on a result by Khan and Swaroop [2021] who show the existence of optimal memory for such models. We formulate the search for the optimal memory as Hessian-matching and propose a probabilistic PCA method to estimate them. Our approach can drastically improve accuracy compared to Experience Replay. For instance, on Split-ImageNet, we get 60% accuracy compared to 30% obtained by replay with memory-size equivalent to 0.3% of the data size. Increasing the memory size to 2% further boosts the accuracy to 74%, closing the gap to the batch accuracy of 77.6% on this task. Our work opens a new direction for building compact memory that can also be useful in the future for continual deep learning.
Bayesian Computation in Deep Learning
Feb 26, 2025This review paper is intended for the 2nd edition of the Handbook of Markov chain Monte Carlo. We provide an introduction to approximate inference techniques as Bayesian computation methods applied to deep learning models. We organize the chapter by presenting popular computational methods for Bayesian neural networks and deep generative models, explaining their unique challenges in posterior inference as well as the solutions.
Recurrent Memory for Online Interdomain Gaussian Processes
Feb 12, 2025We propose a novel online Gaussian process (GP) model that is capable of capturing long-term memory in sequential data in an online regression setting. Our model, Online HiPPO Sparse Variational Gaussian Process Regression (OHSGPR), leverages the HiPPO (High-order Polynomial Projection Operators) framework, which is popularized in the RNN domain due to its long-range memory modeling capabilities. We interpret the HiPPO time-varying orthogonal projections as inducing variables with time-dependent orthogonal polynomial basis functions, which allows the SGPR inducing points to memorize the process history. We show that the HiPPO framework fits naturally into the interdomain GP framework and demonstrate that the kernel matrices can also be updated online in a recurrence form based on the ODE evolution of HiPPO. We evaluate our method on time series regression tasks, showing that it outperforms the existing online GP method in terms of predictive performance and computational efficiency
Your Image is Secretly the Last Frame of a Pseudo Video
Oct 26, 2024
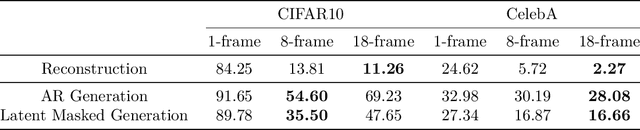


Diffusion models, which can be viewed as a special case of hierarchical variational autoencoders (HVAEs), have shown profound success in generating photo-realistic images. In contrast, standard HVAEs often produce images of inferior quality compared to diffusion models. In this paper, we hypothesize that the success of diffusion models can be partly attributed to the additional self-supervision information for their intermediate latent states provided by corrupted images, which along with the original image form a pseudo video. Based on this hypothesis, we explore the possibility of improving other types of generative models with such pseudo videos. Specifically, we first extend a given image generative model to their video generative model counterpart, and then train the video generative model on pseudo videos constructed by applying data augmentation to the original images. Furthermore, we analyze the potential issues of first-order Markov data augmentation methods, which are typically used in diffusion models, and propose to use more expressive data augmentation to construct more useful information in pseudo videos. Our empirical results on the CIFAR10 and CelebA datasets demonstrate that improved image generation quality can be achieved with additional self-supervised information from pseudo videos.
Prototype-based Optimal Transport for Out-of-Distribution Detection
Oct 10, 2024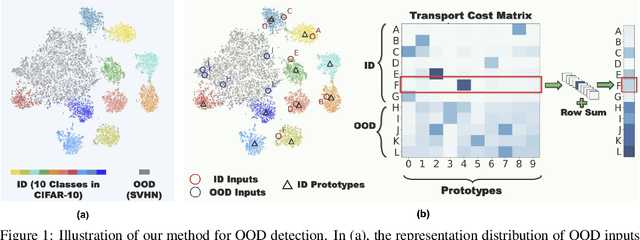
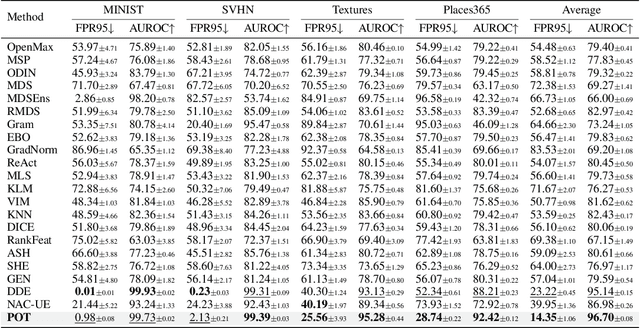

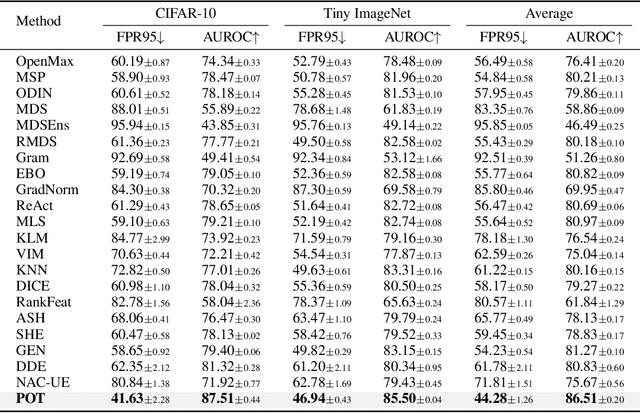
Detecting Out-of-Distribution (OOD) inputs is crucial for improving the reliability of deep neural networks in the real-world deployment. In this paper, inspired by the inherent distribution shift between ID and OOD data, we propose a novel method that leverages optimal transport to measure the distribution discrepancy between test inputs and ID prototypes. The resulting transport costs are used to quantify the individual contribution of each test input to the overall discrepancy, serving as a desirable measure for OOD detection. To address the issue that solely relying on the transport costs to ID prototypes is inadequate for identifying OOD inputs closer to ID data, we generate virtual outliers to approximate the OOD region via linear extrapolation. By combining the transport costs to ID prototypes with the costs to virtual outliers, the detection of OOD data near ID data is emphasized, thereby enhancing the distinction between ID and OOD inputs. Experiments demonstrate the superiority of our method over state-of-the-art methods.
MAO: A Framework for Process Model Generation with Multi-Agent Orchestration
Aug 07, 2024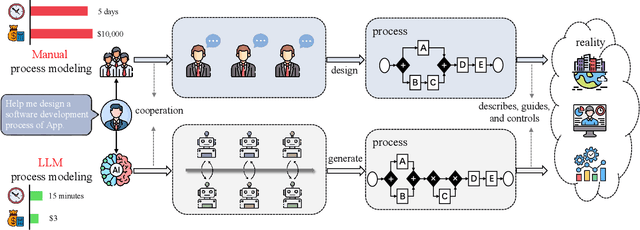
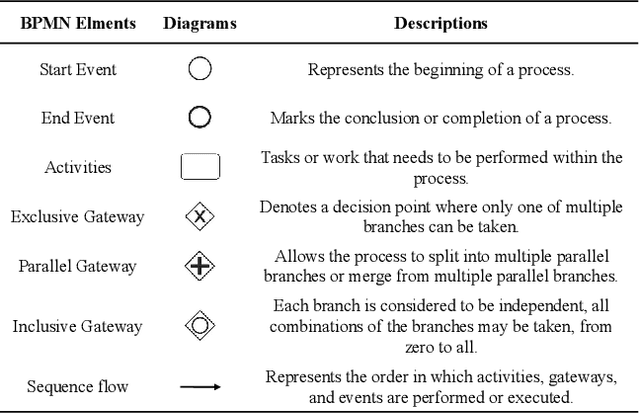
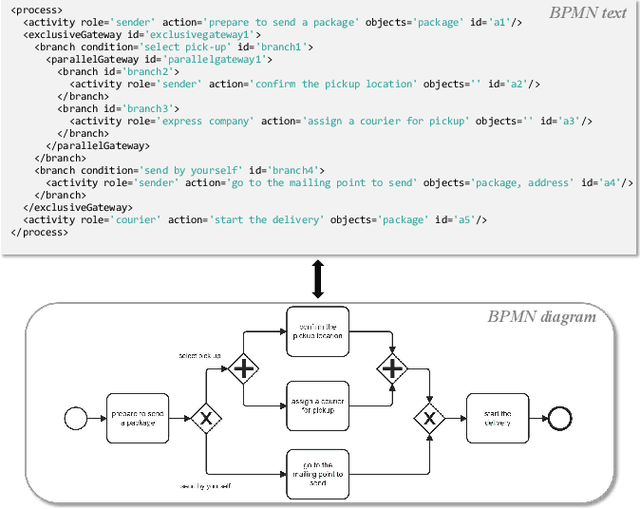
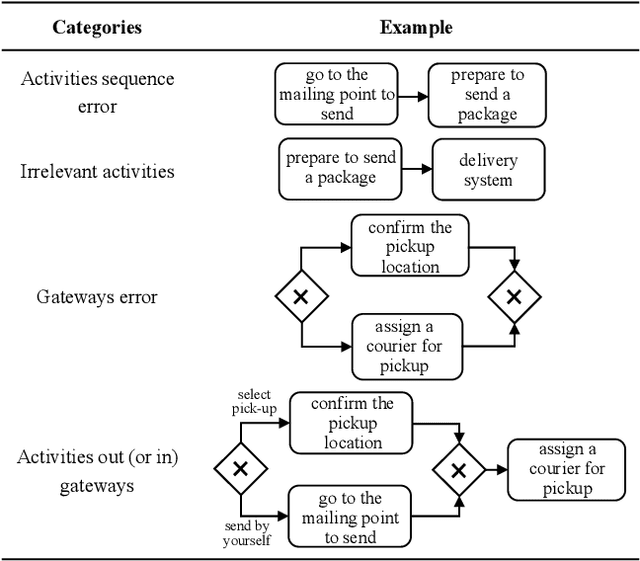
Process models are frequently used in software engineering to describe business requirements, guide software testing and control system improvement. However, traditional process modeling methods often require the participation of numerous experts, which is expensive and time-consuming. Therefore, the exploration of a more efficient and cost-effective automated modeling method has emerged as a focal point in current research. This article explores a framework for automatically generating process models with multi-agent orchestration (MAO), aiming to enhance the efficiency of process modeling and offer valuable insights for domain experts. Our framework MAO leverages large language models as the cornerstone for multi-agent, employing an innovative prompt strategy to ensure efficient collaboration among multi-agent. Specifically, 1) generation. The first phase of MAO is to generate a slightly rough process model from the text description; 2) refinement. The agents would continuously refine the initial process model through multiple rounds of dialogue; 3) reviewing. Large language models are prone to hallucination phenomena among multi-turn dialogues, so the agents need to review and repair semantic hallucinations in process models; 4) testing. The representation of process models is diverse. Consequently, the agents utilize external tools to test whether the generated process model contains format errors, namely format hallucinations, and then adjust the process model to conform to the output paradigm. The experiments demonstrate that the process models generated by our framework outperform existing methods and surpass manual modeling by 89%, 61%, 52%, and 75% on four different datasets, respectively.
Detecting Out-of-Distribution Samples via Conditional Distribution Entropy with Optimal Transport
Jan 22, 2024When deploying a trained machine learning model in the real world, it is inevitable to receive inputs from out-of-distribution (OOD) sources. For instance, in continual learning settings, it is common to encounter OOD samples due to the non-stationarity of a domain. More generally, when we have access to a set of test inputs, the existing rich line of OOD detection solutions, especially the recent promise of distance-based methods, falls short in effectively utilizing the distribution information from training samples and test inputs. In this paper, we argue that empirical probability distributions that incorporate geometric information from both training samples and test inputs can be highly beneficial for OOD detection in the presence of test inputs available. To address this, we propose to model OOD detection as a discrete optimal transport problem. Within the framework of optimal transport, we propose a novel score function known as the \emph{conditional distribution entropy} to quantify the uncertainty of a test input being an OOD sample. Our proposal inherits the merits of certain distance-based methods while eliminating the reliance on distribution assumptions, a-prior knowledge, and specific training mechanisms. Extensive experiments conducted on benchmark datasets demonstrate that our method outperforms its competitors in OOD detection.
An Incremental Update Framework for Online Recommenders with Data-Driven Prior
Dec 26, 2023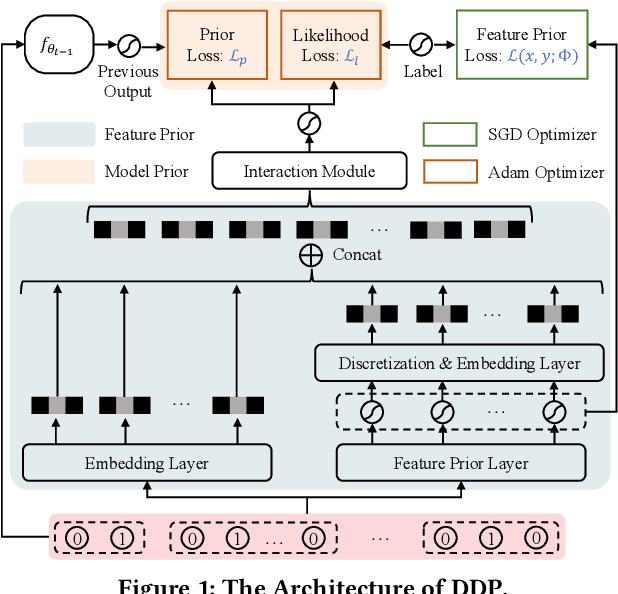
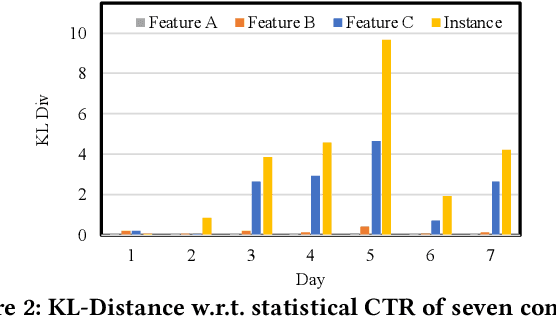
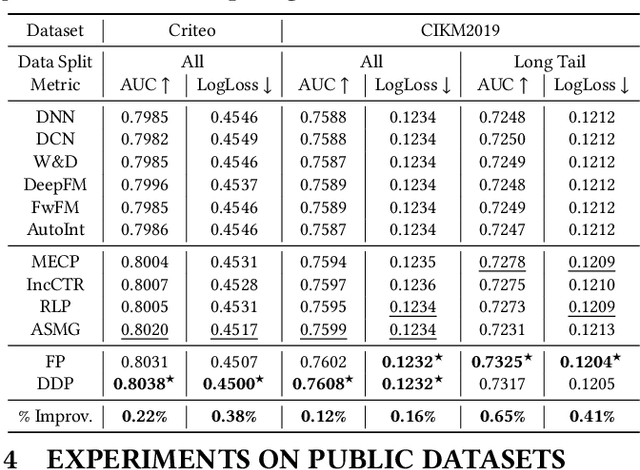
Online recommenders have attained growing interest and created great revenue for businesses. Given numerous users and items, incremental update becomes a mainstream paradigm for learning large-scale models in industrial scenarios, where only newly arrived data within a sliding window is fed into the model, meeting the strict requirements of quick response. However, this strategy would be prone to overfitting to newly arrived data. When there exists a significant drift of data distribution, the long-term information would be discarded, which harms the recommendation performance. Conventional methods address this issue through native model-based continual learning methods, without analyzing the data characteristics for online recommenders. To address the aforementioned issue, we propose an incremental update framework for online recommenders with Data-Driven Prior (DDP), which is composed of Feature Prior (FP) and Model Prior (MP). The FP performs the click estimation for each specific value to enhance the stability of the training process. The MP incorporates previous model output into the current update while strictly following the Bayes rules, resulting in a theoretically provable prior for the robust update. In this way, both the FP and MP are well integrated into the unified framework, which is model-agnostic and can accommodate various advanced interaction models. Extensive experiments on two publicly available datasets as well as an industrial dataset demonstrate the superior performance of the proposed framework.
Parallel Ranking of Ads and Creatives in Real-Time Advertising Systems
Dec 20, 2023
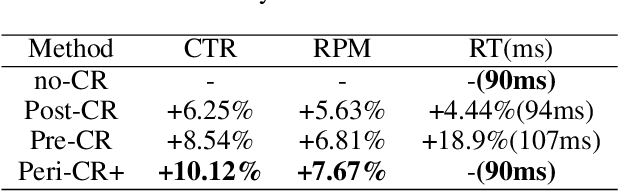
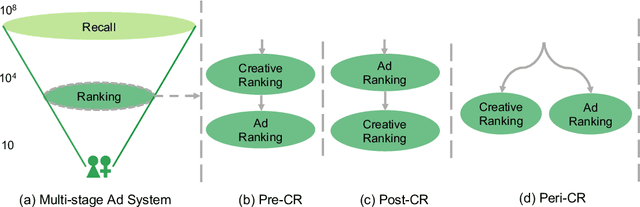
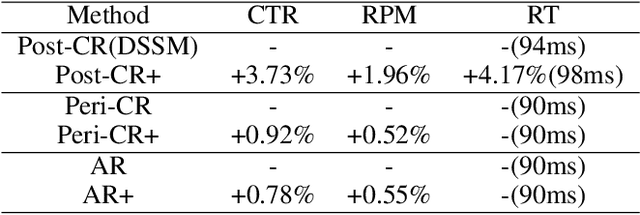
"Creativity is the heart and soul of advertising services". Effective creatives can create a win-win scenario: advertisers can reach target users and achieve marketing objectives more effectively, users can more quickly find products of interest, and platforms can generate more advertising revenue. With the advent of AI-Generated Content, advertisers now can produce vast amounts of creative content at a minimal cost. The current challenge lies in how advertising systems can select the most pertinent creative in real-time for each user personally. Existing methods typically perform serial ranking of ads or creatives, limiting the creative module in terms of both effectiveness and efficiency. In this paper, we propose for the first time a novel architecture for online parallel estimation of ads and creatives ranking, as well as the corresponding offline joint optimization model. The online architecture enables sophisticated personalized creative modeling while reducing overall latency. The offline joint model for CTR estimation allows mutual awareness and collaborative optimization between ads and creatives. Additionally, we optimize the offline evaluation metrics for the implicit feedback sorting task involved in ad creative ranking. We conduct extensive experiments to compare ours with two state-of-the-art approaches. The results demonstrate the effectiveness of our approach in both offline evaluations and real-world advertising platforms online in terms of response time, CTR, and CPM.
Post-hoc Bias Scoring Is Optimal For Fair Classification
Oct 09, 2023
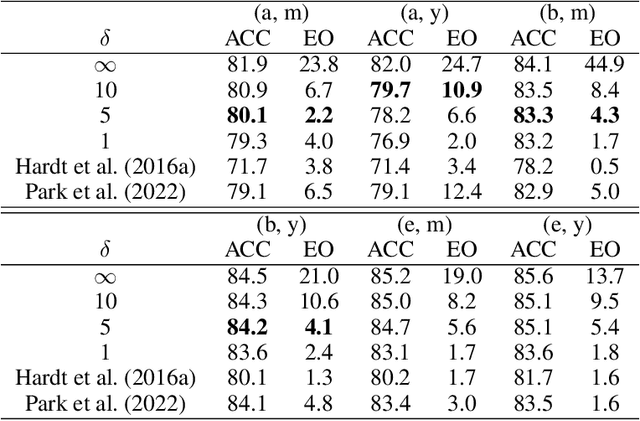

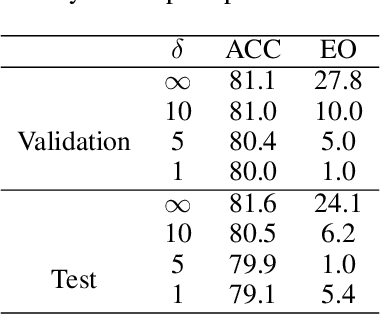
We consider a binary classification problem under group fairness constraints, which can be one of Demographic Parity (DP), Equalized Opportunity (EOp), or Equalized Odds (EO). We propose an explicit characterization of Bayes optimal classifier under the fairness constraints, which turns out to be a simple modification rule of the unconstrained classifier. Namely, we introduce a novel instance-level measure of bias, which we call bias score, and the modification rule is a simple linear rule on top of the finite amount of bias scores. Based on this characterization, we develop a post-hoc approach that allows us to adapt to fairness constraints while maintaining high accuracy. In the case of DP and EOp constraints, the modification rule is thresholding a single bias score, while in the case of EO constraints we are required to fit a linear modification rule with 2 parameters. The method can also be applied for composite group-fairness criteria, such as ones involving several sensitive attributes. We achieve competitive or better performance compared to both in-processing and post-processing methods across three datasets: Adult, COMPAS, and CelebA. Unlike most post-processing methods, we do not require access to sensitive attributes during the inference time.