 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Reasoning Fails to Plan: A Planning-Centric Analysis of Long-Horizon Decision Making in LLM Agents
Jan 29, 2026Large language model (LLM)-based agents exhibit strong step-by-step reasoning capabilities over short horizons, yet often fail to sustain coherent behavior over long planning horizons. We argue that this failure reflects a fundamental mismatch: step-wise reasoning induces a form of step-wise greedy policy that is adequate for short horizons but fails in long-horizon planning, where early actions must account for delayed consequences. From this planning-centric perspective, we study LLM-based agents in deterministic, fully structured environments with explicit state transitions and evaluation signals. Our analysis reveals a core failure mode of reasoning-based policies: locally optimal choices induced by step-wise scoring lead to early myopic commitments that are systematically amplified over time and difficult to recover from. We introduce FLARE (Future-aware Lookahead with Reward Estimation) as a minimal instantiation of future-aware planning to enforce explicit lookahead, value propagation, and limited commitment in a single model, allowing downstream outcomes to influence early decisions. Across multiple benchmarks, agent frameworks, and LLM backbones, FLARE consistently improves task performance and planning-level behavior, frequently allowing LLaMA-8B with FLARE to outperform GPT-4o with standard step-by-step reasoning. These results establish a clear distinction between reasoning and planning.
Reward-Shifted Speculative Sampling Is An Efficient Test-Time Weak-to-Strong Aligner
Aug 20, 2025Aligning large language models (LLMs) with human preferences has become a critical step in their development. Recent research has increasingly focused on test-time alignment, where additional compute is allocated during inference to enhance LLM safety and reasoning capabilities. However, these test-time alignment techniques often incur substantial inference costs, limiting their practical application. We are inspired by the speculative sampling acceleration, which leverages a small draft model to efficiently predict future tokens, to address the efficiency bottleneck of test-time alignment. We introduce the reward-Shifted Speculative Sampling (SSS) algorithm, in which the draft model is aligned with human preferences, while the target model remains unchanged. We theoretically demonstrate that the distributional shift between the aligned draft model and the unaligned target model can be exploited to recover the RLHF optimal solution without actually obtaining it, by modifying the acceptance criterion and bonus token distribution. Our algorithm achieves superior gold reward scores at a significantly reduced inference cost in test-time weak-to-strong alignment experiments, thereby validating both its effectiveness and efficiency.
Stacey: Promoting Stochastic Steepest Descent via Accelerated $\ell_p$-Smooth Nonconvex Optimization
Jun 07, 2025While popular optimization methods such as SGD, AdamW, and Lion depend on steepest descent updates in either $\ell_2$ or $\ell_\infty$ norms, there remains a critical gap in handling the non-Euclidean structure observed in modern deep networks training. In this work, we address this need by introducing a new accelerated $\ell_p$ steepest descent algorithm, called Stacey, which uses interpolated primal-dual iterate sequences to effectively navigate non-Euclidean smooth optimization tasks. In addition to providing novel theoretical guarantees for the foundations of our algorithm, we empirically compare our approach against these popular methods on tasks including image classification and language model (LLM) pretraining, demonstrating both faster convergence and higher final accuracy. We further evaluate different values of $p$ across various models and datasets, underscoring the importance and efficiency of non-Euclidean approaches over standard Euclidean methods. Code can be found at https://github.com/xinyuluo8561/Stacey .
More is Less: The Pitfalls of Multi-Model Synthetic Preference Data in DPO Safety Alignment
Apr 03, 2025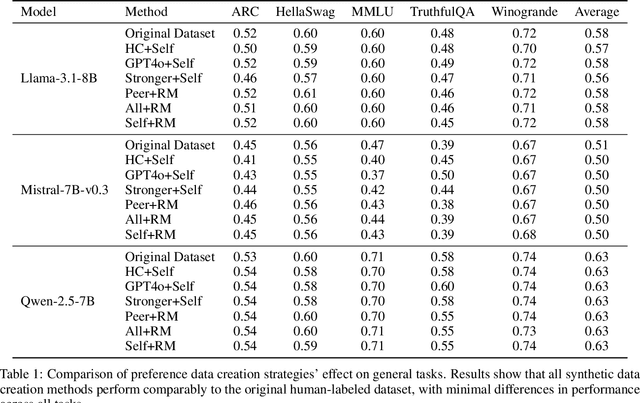
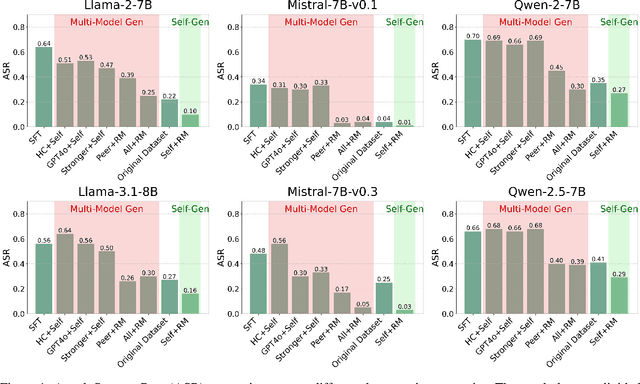
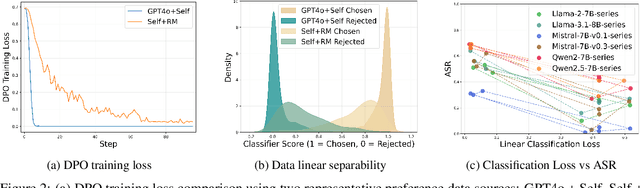

Aligning large language models (LLMs) with human values is an increasingly critical step in post-training. Direct Preference Optimization (DPO) has emerged as a simple, yet effective alternative to reinforcement learning from human feedback (RLHF). Synthetic preference data with its low cost and high quality enable effective alignment through single- or multi-model generated preference data. Our study reveals a striking, safety-specific phenomenon associated with DPO alignment: Although multi-model generated data enhances performance on general tasks (ARC, Hellaswag, MMLU, TruthfulQA, Winogrande) by providing diverse responses, it also tends to facilitate reward hacking during training. This can lead to a high attack success rate (ASR) when models encounter jailbreaking prompts. The issue is particularly pronounced when employing stronger models like GPT-4o or larger models in the same family to generate chosen responses paired with target model self-generated rejected responses, resulting in dramatically poorer safety outcomes. Furthermore, with respect to safety, using solely self-generated responses (single-model generation) for both chosen and rejected pairs significantly outperforms configurations that incorporate responses from stronger models, whether used directly as chosen data or as part of a multi-model response pool. We demonstrate that multi-model preference data exhibits high linear separability between chosen and rejected responses, which allows models to exploit superficial cues rather than internalizing robust safety constraints. Our experiments, conducted on models from the Llama, Mistral, and Qwen families, consistently validate these findings.
Bayesian Computation in Deep Learning
Feb 26, 2025This review paper is intended for the 2nd edition of the Handbook of Markov chain Monte Carlo. We provide an introduction to approximate inference techniques as Bayesian computation methods applied to deep learning models. We organize the chapter by presenting popular computational methods for Bayesian neural networks and deep generative models, explaining their unique challenges in posterior inference as well as the solutions.
Making Reliable and Flexible Decisions in Long-tailed Classification
Jan 23, 2025Long-tailed classification is challenging due to its heavy imbalance in class probabilities. While existing methods often focus on overall accuracy or accuracy for tail classes, they overlook a critical aspect: certain types of errors can carry greater risks than others in real-world long-tailed problems. For example, misclassifying patients (a tail class) as healthy individuals (a head class) entails far more serious consequences than the reverse scenario. To address this critical issue, we introduce Making Reliable and Flexible Decisions in Long-tailed Classification (RF-DLC), a novel framework aimed at reliable predictions in long-tailed problems. Leveraging Bayesian Decision Theory, we introduce an integrated gain to seamlessly combine long-tailed data distributions and the decision-making procedure. We further propose an efficient variational optimization strategy for the decision risk objective. Our method adapts readily to diverse utility matrices, which can be designed for specific tasks, ensuring its flexibility for different problem settings. In empirical evaluation, we design a new metric, False Head Rate, to quantify tail-sensitivity risk, along with comprehensive experiments on multiple real-world tasks, including large-scale image classification and uncertainty quantification, to demonstrate the reliability and flexibility of our method.
ETA: Evaluating Then Aligning Safety of Vision Language Models at Inference Time
Oct 09, 2024Vision Language Models (VLMs) have become essential backbones for multimodal intelligence, yet significant safety challenges limit their real-world application. While textual inputs are often effectively safeguarded, adversarial visual inputs can easily bypass VLM defense mechanisms. Existing defense methods are either resource-intensive, requiring substantial data and compute, or fail to simultaneously ensure safety and usefulness in responses. To address these limitations, we propose a novel two-phase inference-time alignment framework, Evaluating Then Aligning (ETA): 1) Evaluating input visual contents and output responses to establish a robust safety awareness in multimodal settings, and 2) Aligning unsafe behaviors at both shallow and deep levels by conditioning the VLMs' generative distribution with an interference prefix and performing sentence-level best-of-N to search the most harmless and helpful generation paths. Extensive experiments show that ETA outperforms baseline methods in terms of harmlessness, helpfulness, and efficiency, reducing the unsafe rate by 87.5% in cross-modality attacks and achieving 96.6% win-ties in GPT-4 helpfulness evaluation. The code is publicly available at https://github.com/DripNowhy/ETA.
Cascade Reward Sampling for Efficient Decoding-Time Alignment
Jun 24, 2024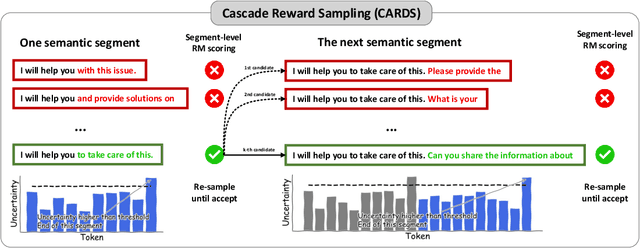

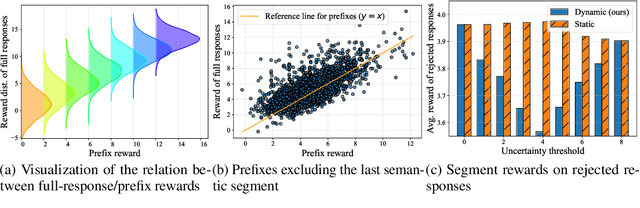
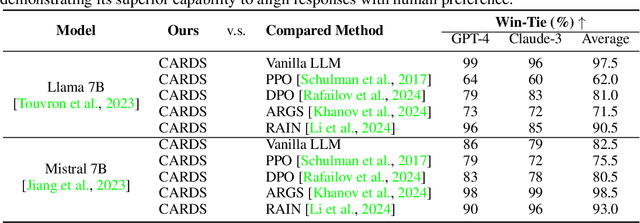
Aligning large language models (LLMs) with human preferences is critical for their deployment. Recently, decoding-time alignment has emerged as an effective plug-and-play technique that requires no fine-tuning of model parameters. However, generating text that achieves both high reward and high likelihood remains a significant challenge. Existing methods often fail to generate high-reward text or incur substantial computational costs. In this paper, we propose Cascade Reward Sampling (CARDS) to address both issues, guaranteeing the generation of high-reward and high-likelihood text with significantly low costs. Based on our analysis of reward models (RMs) on incomplete text and our observation that high-reward prefixes induce high-reward complete text, we use rejection sampling to iteratively generate small semantic segments to form such prefixes. The segment length is dynamically determined by the predictive uncertainty of LLMs. This strategy guarantees desirable prefixes for subsequent generations and significantly reduces wasteful token re-generations and the number of reward model scoring. Our experiments demonstrate substantial gains in both generation efficiency and alignment ratings compared to the baselines, achieving five times faster text generation and 99\% win-ties in GPT-4/Claude-3 helpfulness evaluation.
Entropy-MCMC: Sampling from Flat Basins with Ease
Oct 09, 2023Bayesian deep learning counts on the quality of posterior distribution estimation. However, the posterior of deep neural networks is highly multi-modal in nature, with local modes exhibiting varying generalization performance. Given a practical budget, sampling from the original posterior can lead to suboptimal performance, as some samples may become trapped in "bad" modes and suffer from overfitting. Leveraging the observation that "good" modes with low generalization error often reside in flat basins of the energy landscape, we propose to bias sampling on the posterior toward these flat regions. Specifically, we introduce an auxiliary guiding variable, the stationary distribution of which resembles a smoothed posterior free from sharp modes, to lead the MCMC sampler to flat basins. By integrating this guiding variable with the model parameter, we create a simple joint distribution that enables efficient sampling with minimal computational overhead. We prove the convergence of our method and further show that it converges faster than several existing flatness-aware methods in the strongly convex setting. Empirical results demonstrate that our method can successfully sample from flat basins of the posterior, and outperforms all compared baselines on multiple benchmarks including classification, calibration, and out-of-distribution detection.
Long-tailed Classification from a Bayesian-decision-theory Perspective
Mar 21, 2023Long-tailed classification poses a challenge due to its heavy imbalance in class probabilities and tail-sensitivity risks with asymmetric misprediction costs. Recent attempts have used re-balancing loss and ensemble methods, but they are largely heuristic and depend heavily on empirical results, lacking theoretical explanation. Furthermore, existing methods overlook the decision loss, which characterizes different costs associated with tailed classes. This paper presents a general and principled framework from a Bayesian-decision-theory perspective, which unifies existing techniques including re-balancing and ensemble methods, and provides theoretical justifications for their effectiveness. From this perspective, we derive a novel objective based on the integrated risk and a Bayesian deep-ensemble approach to improve the accuracy of all classes, especially the "tail". Besides, our framework allows for task-adaptive decision loss which provides provably optimal decisions in varying task scenarios, along with the capability to quantify uncertainty. Finally, We conduct comprehensive experiments, including standard classification, tail-sensitive classification with a new False Head Rate metric, calibration, and ablation studies. Our framework significantly improves the current SOTA even on large-scale real-world datasets like ImageNet.