 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Reward Sampling for Efficient Decoding-Time Alignment
Paper and Code
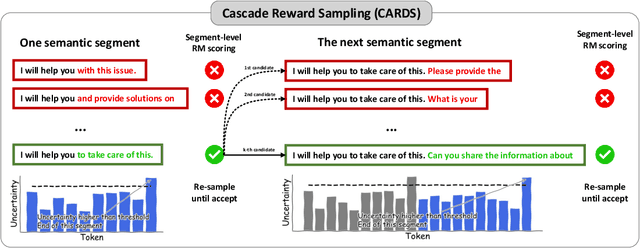

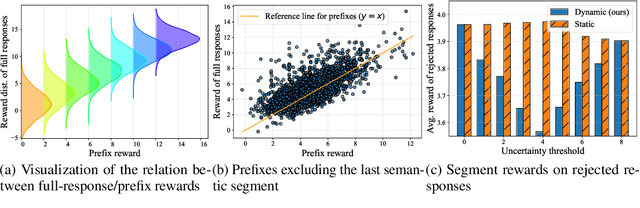
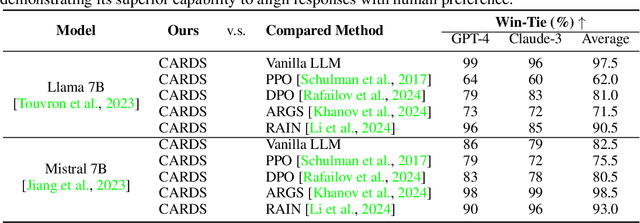
Aligning large language models (LLMs) with human preferences is critical for their deployment. Recently, decoding-time alignment has emerged as an effective plug-and-play technique that requires no fine-tuning of model parameters. However, generating text that achieves both high reward and high likelihood remains a significant challenge. Existing methods often fail to generate high-reward text or incur substantial computational costs. In this paper, we propose Cascade Reward Sampling (CARDS) to address both issues, guaranteeing the generation of high-reward and high-likelihood text with significantly low costs. Based on our analysis of reward models (RMs) on incomplete text and our observation that high-reward prefixes induce high-reward complete text, we use rejection sampling to iteratively generate small semantic segments to form such prefixes. The segment length is dynamically determined by the predictive uncertainty of LLMs. This strategy guarantees desirable prefixes for subsequent generations and significantly reduces wasteful token re-generations and the number of reward model scoring. Our experiments demonstrate substantial gains in both generation efficiency and alignment ratings compared to the baselines, achieving five times faster text generation and 99\% win-ties in GPT-4/Claude-3 helpfulness evaluation.