 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Safety Guardrails Are Necessary for Foundation-Model-Enabled Robots in the Real World
Feb 03, 2026The integration of foundation models (FMs) into robotics has accelerated real-world deployment, while introducing new safety challenges arising from open-ended semantic reasoning and embodied physical action. These challenges require safety notions beyond physical constraint satisfaction. In this paper, we characterize FM-enabled robot safety along three dimensions: action safety (physical feasibility and constraint compliance), decision safety (semantic and contextual appropriateness), and human-centered safety (conformance to human intent, norms, and expectations). We argue that existing approaches, including static verification, monolithic controllers, and end-to-end learned policies, are insufficient in settings where tasks, environments, and human expectations are open-ended, long-tailed, and subject to adaptation over time. To address this gap, we propose modular safety guardrails, consisting of monitoring (evaluation) and intervention layers, as an architectural foundation for comprehensive safety across the autonomy stack. Beyond modularity, we highlight possible cross-layer co-design opportunities through representation alignment and conservatism allocation to enable faster, less conservative, and more effective safety enforcement. We call on the community to explore richer guardrail modules and principled co-design strategies to advance safe real-world physical AI deployment.
CANDI: Hybrid Discrete-Continuous Diffusion Models
Oct 26, 2025While continuous diffusion has shown remarkable success in continuous domains such as image generation, its direct application to discrete data has underperformed compared to purely discrete formulations. This gap is counterintuitive, given that continuous diffusion learns score functions that enable joint evolution across multiple positions. To understand this gap, we introduce token identifiability as an analytical framework for understanding how Gaussian noise corrupts discrete data through two mechanisms: discrete identity corruption and continuous rank degradation. We reveal that these mechanisms scale differently with vocabulary size, creating a temporal dissonance: at noise levels where discrete corruption preserves enough structure for conditional learning, continuous denoising is trivial; at noise levels where continuous denoising is meaningful, discrete corruption destroys nearly all conditional structure. To solve this, we propose CANDI (Continuous ANd DIscrete diffusion), a hybrid framework that decouples discrete and continuous corruption, enabling simultaneous learning of both conditional structure and continuous geometry. We empirically validate the temporal dissonance phenomenon and demonstrate that CANDI successfully avoids it. This unlocks the benefits of continuous diffusion for discrete spaces: on controlled generation, CANDI enables classifier-based guidance with off-the-shelf classifiers through simple gradient addition; on text generation, CANDI outperforms masked diffusion at low NFE, demonstrating the value of learning continuous gradients for discrete spaces.
Reward-Shifted Speculative Sampling Is An Efficient Test-Time Weak-to-Strong Aligner
Aug 20, 2025Aligning large language models (LLMs) with human preferences has become a critical step in their development. Recent research has increasingly focused on test-time alignment, where additional compute is allocated during inference to enhance LLM safety and reasoning capabilities. However, these test-time alignment techniques often incur substantial inference costs, limiting their practical application. We are inspired by the speculative sampling acceleration, which leverages a small draft model to efficiently predict future tokens, to address the efficiency bottleneck of test-time alignment. We introduce the reward-Shifted Speculative Sampling (SSS) algorithm, in which the draft model is aligned with human preferences, while the target model remains unchanged. We theoretically demonstrate that the distributional shift between the aligned draft model and the unaligned target model can be exploited to recover the RLHF optimal solution without actually obtaining it, by modifying the acceptance criterion and bonus token distribution. Our algorithm achieves superior gold reward scores at a significantly reduced inference cost in test-time weak-to-strong alignment experiments, thereby validating both its effectiveness and efficiency.
ViLaD: A Large Vision Language Diffusion Framework for End-to-End Autonomous Driving
Aug 18, 2025End-to-end autonomous driving systems built on Vision Language Models (VLMs) have shown significant promise, yet their reliance on autoregressive architectures introduces some limitations for real-world applications. The sequential, token-by-token generation process of these models results in high inference latency and cannot perform bidirectional reasoning, making them unsuitable for dynamic, safety-critical environments. To overcome these challenges, we introduce ViLaD, a novel Large Vision Language Diffusion (LVLD) framework for end-to-end autonomous driving that represents a paradigm shift. ViLaD leverages a masked diffusion model that enables parallel generation of entire driving decision sequences, significantly reducing computational latency. Moreover, its architecture supports bidirectional reasoning, allowing the model to consider both past and future simultaneously, and supports progressive easy-first generation to iteratively improve decision quality. We conduct comprehensive experiments on the nuScenes dataset, where ViLaD outperforms state-of-the-art autoregressive VLM baselines in both planning accuracy and inference speed, while achieving a near-zero failure rate. Furthermore, we demonstrate the framework's practical viability through a real-world deployment on an autonomous vehicle for an interactive parking task, confirming its effectiveness and soundness for practical applications.
Stacey: Promoting Stochastic Steepest Descent via Accelerated $\ell_p$-Smooth Nonconvex Optimization
Jun 07, 2025While popular optimization methods such as SGD, AdamW, and Lion depend on steepest descent updates in either $\ell_2$ or $\ell_\infty$ norms, there remains a critical gap in handling the non-Euclidean structure observed in modern deep networks training. In this work, we address this need by introducing a new accelerated $\ell_p$ steepest descent algorithm, called Stacey, which uses interpolated primal-dual iterate sequences to effectively navigate non-Euclidean smooth optimization tasks. In addition to providing novel theoretical guarantees for the foundations of our algorithm, we empirically compare our approach against these popular methods on tasks including image classification and language model (LLM) pretraining, demonstrating both faster convergence and higher final accuracy. We further evaluate different values of $p$ across various models and datasets, underscoring the importance and efficiency of non-Euclidean approaches over standard Euclidean methods. Code can be found at https://github.com/xinyuluo8561/Stacey .
Inference Acceleration of Autoregressive Normalizing Flows by Selective Jacobi Decoding
May 30, 2025Normalizing flows are promising generative models with advantages such as theoretical rigor, analytical log-likelihood computation, and end-to-end training. However, the architectural constraints to ensure invertibility and tractable Jacobian computation limit their expressive power and practical usability. Recent advancements utilize autoregressive modeling, significantly enhancing expressive power and generation quality. However, such sequential modeling inherently restricts parallel computation during inference, leading to slow generation that impedes practical deployment. In this paper, we first identify that strict sequential dependency in inference is unnecessary to generate high-quality samples. We observe that patches in sequential modeling can also be approximated without strictly conditioning on all preceding patches. Moreover, the models tend to exhibit low dependency redundancy in the initial layer and higher redundancy in subsequent layers. Leveraging these observations, we propose a selective Jacobi decoding (SeJD) strategy that accelerates autoregressive inference through parallel iterative optimization. Theoretical analyses demonstrate the method's superlinear convergence rate and guarantee that the number of iterations required is no greater than the original sequential approach. Empirical evaluations across multiple datasets validate the generality and effectiveness of our acceleration technique. Experiments demonstrate substantial speed improvements up to 4.7 times faster inference while keeping the generation quality and fidelity.
Sherlock: Self-Correcting Reasoning in Vision-Language Models
May 28, 2025Reasoning Vision-Language Models (VLMs) have shown promising performance on complex multimodal tasks. However, they still face significant challenges: they are highly sensitive to reasoning errors, require large volumes of annotated data or accurate verifiers, and struggle to generalize beyond specific domains. To address these limitations, we explore self-correction as a strategy to enhance reasoning VLMs. We first conduct an in-depth analysis of reasoning VLMs' self-correction abilities and identify key gaps. Based on our findings, we introduce Sherlock, a self-correction and self-improvement training framework. Sherlock introduces a trajectory-level self-correction objective, a preference data construction method based on visual perturbation, and a dynamic $\beta$ for preference tuning. Once the model acquires self-correction capabilities using only 20k randomly sampled annotated data, it continues to self-improve without external supervision. Built on the Llama3.2-Vision-11B model, Sherlock achieves remarkable results across eight benchmarks, reaching an average accuracy of 64.1 with direct generation and 65.4 after self-correction. It outperforms LLaVA-CoT (63.2), Mulberry (63.9), and LlamaV-o1 (63.4) while using less than 20% of the annotated data.
Entropy-Guided Sampling of Flat Modes in Discrete Spaces
May 05, 2025



Sampling from flat modes in discrete spaces is a crucial yet underexplored problem. Flat modes represent robust solutions and have broad applications in combinatorial optimization and discrete generative modeling. However, existing sampling algorithms often overlook the mode volume and struggle to capture flat modes effectively. To address this limitation, we propose \emph{Entropic Discrete Langevin Proposal} (EDLP), which incorporates local entropy into the sampling process through a continuous auxiliary variable under a joint distribution. The local entropy term guides the discrete sampler toward flat modes with a small overhead. We provide non-asymptotic convergence guarantees for EDLP in locally log-concave discrete distributions. Empirically, our method consistently outperforms traditional approaches across tasks that require sampling from flat basins, including Bernoulli distribution, restricted Boltzmann machines, combinatorial optimization, and binary neural networks.
Energy-Based Reward Models for Robust Language Model Alignment
Apr 17, 2025Reward models (RMs) are essential for aligning Large Language Models (LLMs) with human preferences. However, they often struggle with capturing complex human preferences and generalizing to unseen data. To address these challenges, we introduce Energy-Based Reward Model (EBRM), a lightweight post-hoc refinement framework that enhances RM robustness and generalization. EBRM models the reward distribution explicitly, capturing uncertainty in human preferences and mitigating the impact of noisy or misaligned annotations. It achieves this through conflict-aware data filtering, label-noise-aware contrastive training, and hybrid initialization. Notably, EBRM enhances RMs without retraining, making it computationally efficient and adaptable across different models and tasks. Empirical evaluations on RM benchmarks demonstrate significant improvements in both robustness and generalization, achieving up to a 5.97% improvement in safety-critical alignment tasks compared to standard RMs. Furthermore, reinforcement learning experiments confirm that our refined rewards enhance alignment quality, effectively delaying reward hacking. These results demonstrate our approach as a scalable and effective enhancement for existing RMs and alignment pipelines. The code is available at EBRM.
More is Less: The Pitfalls of Multi-Model Synthetic Preference Data in DPO Safety Alignment
Apr 03, 2025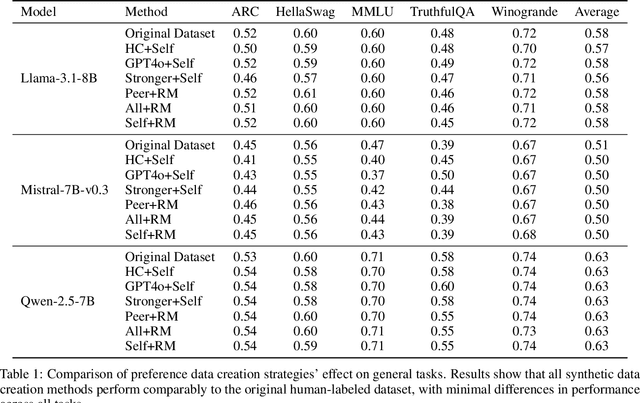
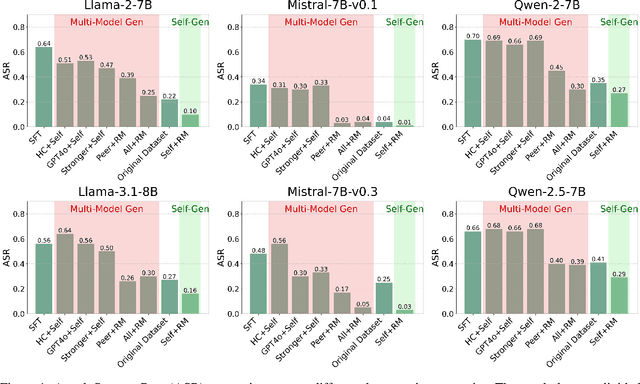
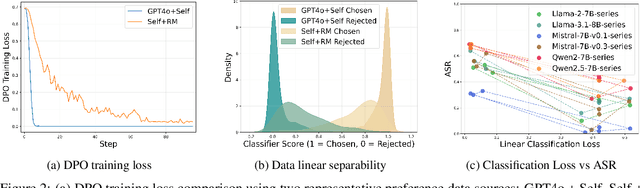

Aligning large language models (LLMs) with human values is an increasingly critical step in post-training. Direct Preference Optimization (DPO) has emerged as a simple, yet effective alternative to reinforcement learning from human feedback (RLHF). Synthetic preference data with its low cost and high quality enable effective alignment through single- or multi-model generated preference data. Our study reveals a striking, safety-specific phenomenon associated with DPO alignment: Although multi-model generated data enhances performance on general tasks (ARC, Hellaswag, MMLU, TruthfulQA, Winogrande) by providing diverse responses, it also tends to facilitate reward hacking during training. This can lead to a high attack success rate (ASR) when models encounter jailbreaking prompts. The issue is particularly pronounced when employing stronger models like GPT-4o or larger models in the same family to generate chosen responses paired with target model self-generated rejected responses, resulting in dramatically poorer safety outcomes. Furthermore, with respect to safety, using solely self-generated responses (single-model generation) for both chosen and rejected pairs significantly outperforms configurations that incorporate responses from stronger models, whether used directly as chosen data or as part of a multi-model response pool. We demonstrate that multi-model preference data exhibits high linear separability between chosen and rejected responses, which allows models to exploit superficial cues rather than internalizing robust safety constraints. Our experiments, conducted on models from the Llama, Mistral, and Qwen families, consistently validate these findings.