 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCount Every Rotation and Every Rotation Counts: Exploring Drone Dynamics via Propeller Sensing
Nov 17, 2025As drone-based applications proliferate, paramount contactless sensing of airborne drones from the ground becomes indispensable. This work demonstrates concentrating on propeller rotational speed will substantially improve drone sensing performance and proposes an event-camera-based solution, \sysname. \sysname features two components: \textit{Count Every Rotation} achieves accurate, real-time propeller speed estimation by mitigating ultra-high sensitivity of event cameras to environmental noise. \textit{Every Rotation Counts} leverages these speeds to infer both internal and external drone dynamics. Extensive evaluations in real-world drone delivery scenarios show that \sysname achieves a sensing latency of 3$ms$ and a rotational speed estimation error of merely 0.23\%. Additionally, \sysname infers drone flight commands with 96.5\% precision and improves drone tracking accuracy by over 22\% when combined with other sensing modalities. \textit{ Demo: {\color{blue}https://eventpro25.github.io/EventPro/.} }
Enabling High-Frequency Cross-Modality Visual Positioning Service for Accurate Drone Landing
Oct 01, 2025After years of growth, drone-based delivery is transforming logistics. At its core, real-time 6-DoF drone pose tracking enables precise flight control and accurate drone landing. With the widespread availability of urban 3D maps, the Visual Positioning Service (VPS), a mobile pose estimation system, has been adapted to enhance drone pose tracking during the landing phase, as conventional systems like GPS are unreliable in urban environments due to signal attenuation and multi-path propagation. However, deploying the current VPS on drones faces limitations in both estimation accuracy and efficiency. In this work, we redesign drone-oriented VPS with the event camera and introduce EV-Pose to enable accurate, high-frequency 6-DoF pose tracking for accurate drone landing. EV-Pose introduces a spatio-temporal feature-instructed pose estimation module that extracts a temporal distance field to enable 3D point map matching for pose estimation; and a motion-aware hierarchical fusion and optimization scheme to enhance the above estimation in accuracy and efficiency, by utilizing drone motion in the \textit{early stage} of event filtering and the \textit{later stage} of pose optimization. Evaluation shows that EV-Pose achieves a rotation accuracy of 1.34$\degree$ and a translation accuracy of 6.9$mm$ with a tracking latency of 10.08$ms$, outperforming baselines by $>$50\%, \tmcrevise{thus enabling accurate drone landings.} Demo: https://ev-pose.github.io/
Reward-Shifted Speculative Sampling Is An Efficient Test-Time Weak-to-Strong Aligner
Aug 20, 2025Aligning large language models (LLMs) with human preferences has become a critical step in their development. Recent research has increasingly focused on test-time alignment, where additional compute is allocated during inference to enhance LLM safety and reasoning capabilities. However, these test-time alignment techniques often incur substantial inference costs, limiting their practical application. We are inspired by the speculative sampling acceleration, which leverages a small draft model to efficiently predict future tokens, to address the efficiency bottleneck of test-time alignment. We introduce the reward-Shifted Speculative Sampling (SSS) algorithm, in which the draft model is aligned with human preferences, while the target model remains unchanged. We theoretically demonstrate that the distributional shift between the aligned draft model and the unaligned target model can be exploited to recover the RLHF optimal solution without actually obtaining it, by modifying the acceptance criterion and bonus token distribution. Our algorithm achieves superior gold reward scores at a significantly reduced inference cost in test-time weak-to-strong alignment experiments, thereby validating both its effectiveness and efficiency.
Stacey: Promoting Stochastic Steepest Descent via Accelerated $\ell_p$-Smooth Nonconvex Optimization
Jun 07, 2025While popular optimization methods such as SGD, AdamW, and Lion depend on steepest descent updates in either $\ell_2$ or $\ell_\infty$ norms, there remains a critical gap in handling the non-Euclidean structure observed in modern deep networks training. In this work, we address this need by introducing a new accelerated $\ell_p$ steepest descent algorithm, called Stacey, which uses interpolated primal-dual iterate sequences to effectively navigate non-Euclidean smooth optimization tasks. In addition to providing novel theoretical guarantees for the foundations of our algorithm, we empirically compare our approach against these popular methods on tasks including image classification and language model (LLM) pretraining, demonstrating both faster convergence and higher final accuracy. We further evaluate different values of $p$ across various models and datasets, underscoring the importance and efficiency of non-Euclidean approaches over standard Euclidean methods. Code can be found at https://github.com/xinyuluo8561/Stacey .
SPACE: SPike-Aware Consistency Enhancement for Test-Time Adaptation in Spiking Neural Networks
Apr 03, 2025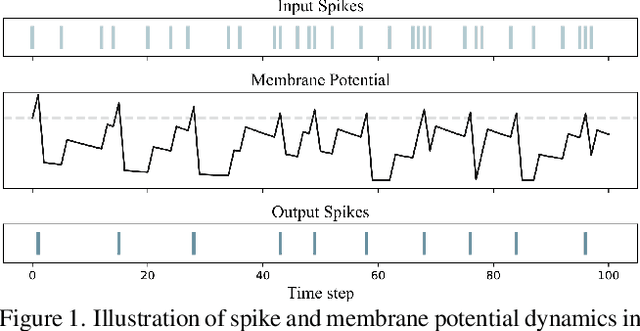

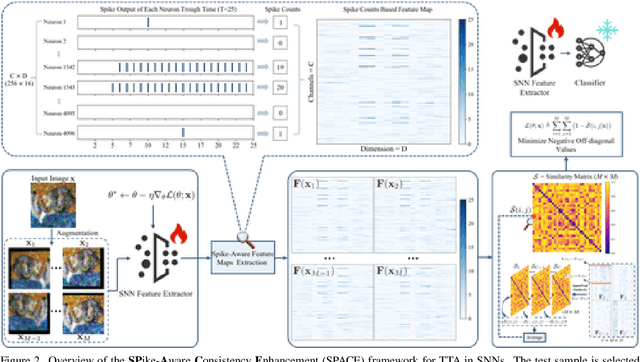

Spiking Neural Networks (SNNs), as a biologically plausible alternative to Artificial Neural Networks (ANNs), have demonstrated advantages in terms of energy efficiency, temporal processing, and biological plausibility. However, SNNs are highly sensitive to distribution shifts, which can significantly degrade their performance in real-world scenarios. Traditional test-time adaptation (TTA) methods designed for ANNs often fail to address the unique computational dynamics of SNNs, such as sparsity and temporal spiking behavior. To address these challenges, we propose $\textbf{SP}$ike-$\textbf{A}$ware $\textbf{C}$onsistency $\textbf{E}$nhancement (SPACE), the first source-free and single-instance TTA method specifically designed for SNNs. SPACE leverages the inherent spike dynamics of SNNs to maximize the consistency of spike-behavior-based local feature maps across augmented versions of a single test sample, enabling robust adaptation without requiring source data. We evaluate SPACE on multiple datasets, including CIFAR-10-C, CIFAR-100-C, Tiny-ImageNet-C and DVS Gesture-C. Furthermore, SPACE demonstrates strong generalization across different model architectures, achieving consistent performance improvements on both VGG9 and ResNet11. Experimental results show that SPACE outperforms state-of-the-art methods, highlighting its effectiveness and robustness in real-world settings.
Test-time Adaptation for Foundation Medical Segmentation Model without Parametric Updates
Apr 02, 2025Foundation medical segmentation models, with MedSAM being the most popular, have achieved promising performance across organs and lesions. However, MedSAM still suffers from compromised performance on specific lesions with intricate structures and appearance, as well as bounding box prompt-induced perturbations. Although current test-time adaptation (TTA) methods for medical image segmentation may tackle this issue, partial (e.g., batch normalization) or whole parametric updates restrict their effectiveness due to limited update signals or catastrophic forgetting in large models. Meanwhile, these approaches ignore the computational complexity during adaptation, which is particularly significant for modern foundation models. To this end, our theoretical analyses reveal that directly refining image embeddings is feasible to approach the same goal as parametric updates under the MedSAM architecture, which enables us to realize high computational efficiency and segmentation performance without the risk of catastrophic forgetting. Under this framework, we propose to encourage maximizing factorized conditional probabilities of the posterior prediction probability using a proposed distribution-approximated latent conditional random field loss combined with an entropy minimization loss. Experiments show that we achieve about 3\% Dice score improvements across three datasets while reducing computational complexity by over 7 times.
Towards Mobile Sensing with Event Cameras on High-mobility Resource-constrained Devices: A Survey
Mar 29, 2025With the increasing complexity of mobile device applications, these devices are evolving toward high mobility. This shift imposes new demands on mobile sensing, particularly in terms of achieving high accuracy and low latency. Event-based vision has emerged as a disruptive paradigm, offering high temporal resolution, low latency, and energy efficiency, making it well-suited for high-accuracy and low-latency sensing tasks on high-mobility platforms. However, the presence of substantial noisy events, the lack of inherent semantic information, and the large data volume pose significant challenges for event-based data processing on resource-constrained mobile devices. This paper surveys the literature over the period 2014-2024, provides a comprehensive overview of event-based mobile sensing systems, covering fundamental principles, event abstraction methods, algorithmic advancements, hardware and software acceleration strategies. We also discuss key applications of event cameras in mobile sensing, including visual odometry, object tracking, optical flow estimation, and 3D reconstruction, while highlighting the challenges associated with event data processing, sensor fusion, and real-time deployment. Furthermore, we outline future research directions, such as improving event camera hardware with advanced optics, leveraging neuromorphic computing for efficient processing, and integrating bio-inspired algorithms to enhance perception. To support ongoing research, we provide an open-source \textit{Online Sheet} with curated resources and recent developments. We hope this survey serves as a valuable reference, facilitating the adoption of event-based vision across diverse applications.
Ultra-High-Frequency Harmony: mmWave Radar and Event Camera Orchestrate Accurate Drone Landing
Feb 20, 2025For precise, efficient, and safe drone landings, ground platforms should real-time, accurately locate descending drones and guide them to designated spots. While mmWave sensing combined with cameras improves localization accuracy, the lower sampling frequency of traditional frame cameras compared to mmWave radar creates bottlenecks in system throughput. In this work, we replace the traditional frame camera with event camera, a novel sensor that harmonizes in sampling frequency with mmWave radar within the ground platform setup, and introduce mmE-Loc, a high-precision, low-latency ground localization system designed for drone landings. To fully leverage the \textit{temporal consistency} and \textit{spatial complementarity} between these modalities, we propose two innovative modules, \textit{consistency-instructed collaborative tracking} and \textit{graph-informed adaptive joint optimization}, for accurate drone measurement extraction and efficient sensor fusion. Extensive real-world experiments in landing scenarios from a leading drone delivery company demonstrate that mmE-Loc outperforms state-of-the-art methods in both localization accuracy and latency.
Dimensionality Reduction for General KDE Mode Finding
Jun 01, 2023
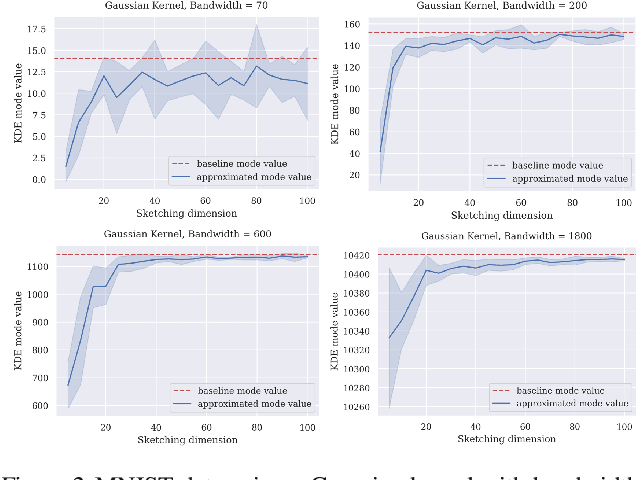
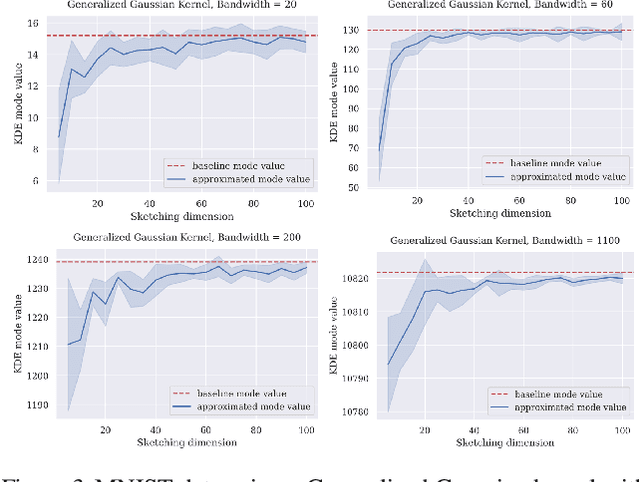
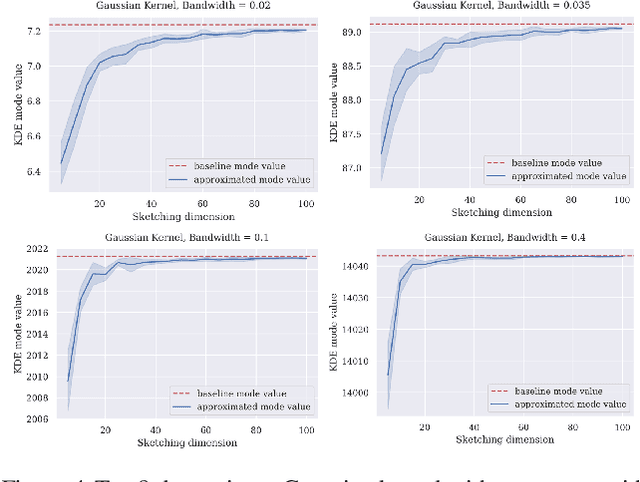
Finding the mode of a high dimensional probability distribution $D$ is a fundamental algorithmic problem in statistics and data analysis. There has been particular interest in efficient methods for solving the problem when $D$ is represented as a mixture model or kernel density estimate, although few algorithmic results with worst-case approximation and runtime guarantees are known. In this work, we significantly generalize a result of (LeeLiMusco:2021) on mode approximation for Gaussian mixture models. We develop randomized dimensionality reduction methods for mixtures involving a broader class of kernels, including the popular logistic, sigmoid, and generalized Gaussian kernels. As in Lee et al.'s work, our dimensionality reduction results yield quasi-polynomial algorithms for mode finding with multiplicative accuracy $(1-\epsilon)$ for any $\epsilon > 0$. Moreover, when combined with gradient descent, they yield efficient practical heuristics for the problem. In addition to our positive results, we prove a hardness result for box kernels, showing that there is no polynomial time algorithm for finding the mode of a kernel density estimate, unless $\mathit{P} = \mathit{NP}$. Obtaining similar hardness results for kernels used in practice (like Gaussian or logistic kernels) is an interesting future direction.
Towards Robust Semantic Segmentation of Accident Scenes via Multi-Source Mixed Sampling and Meta-Learning
Mar 19, 2022
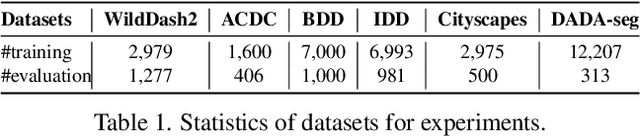
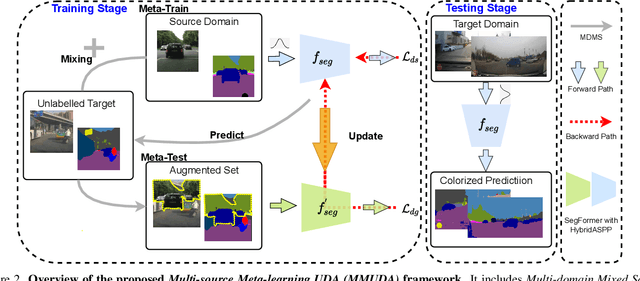
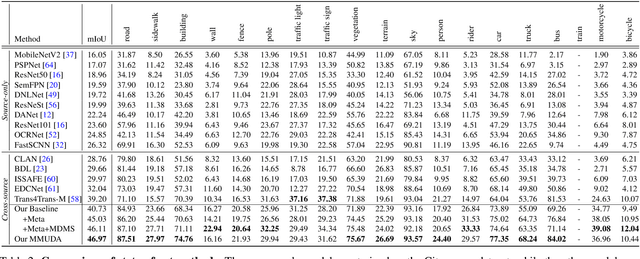
Autonomous vehicles utilize urban scene segmentation to understand the real world like a human and react accordingly. Semantic segmentation of normal scenes has experienced a remarkable rise in accuracy on conventional benchmarks. However, a significant portion of real-life accidents features abnormal scenes, such as those with object deformations, overturns, and unexpected traffic behaviors. Since even small mis-segmentation of driving scenes can lead to serious threats to human lives, the robustness of such models in accident scenarios is an extremely important factor in ensuring safety of intelligent transportation systems. In this paper, we propose a Multi-source Meta-learning Unsupervised Domain Adaptation (MMUDA) framework, to improve the generalization of segmentation transformers to extreme accident scenes. In MMUDA, we make use of Multi-Domain Mixed Sampling to augment the images of multiple-source domains (normal scenes) with the target data appearances (abnormal scenes). To train our model, we intertwine and study a meta-learning strategy in the multi-source setting for robustifying the segmentation results. We further enhance the segmentation backbone (SegFormer) with a HybridASPP decoder design, featuring large window attention spatial pyramid pooling and strip pooling, to efficiently aggregate long-range contextual dependencies. Our approach achieves a mIoU score of 46.97% on the DADA-seg benchmark, surpassing the previous state-of-the-art model by more than 7.50%. Code will be made publicly available at https://github.com/xinyu-laura/MMUDA.