 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Semantic Segmentation of Accident Scenes via Multi-Source Mixed Sampling and Meta-Learning
Paper and Code

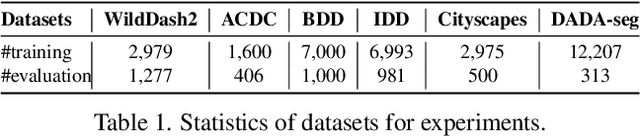
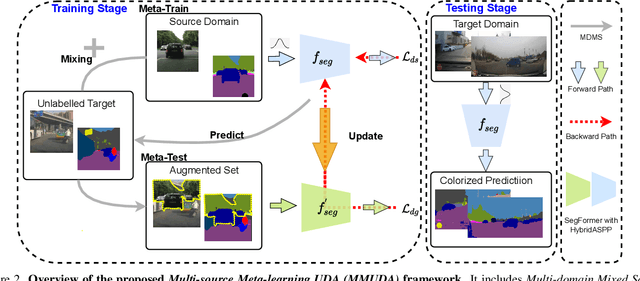
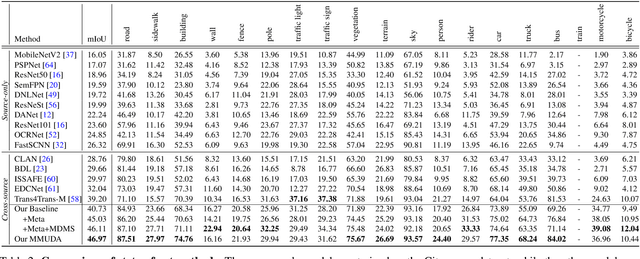
Autonomous vehicles utilize urban scene segmentation to understand the real world like a human and react accordingly. Semantic segmentation of normal scenes has experienced a remarkable rise in accuracy on conventional benchmarks. However, a significant portion of real-life accidents features abnormal scenes, such as those with object deformations, overturns, and unexpected traffic behaviors. Since even small mis-segmentation of driving scenes can lead to serious threats to human lives, the robustness of such models in accident scenarios is an extremely important factor in ensuring safety of intelligent transportation systems. In this paper, we propose a Multi-source Meta-learning Unsupervised Domain Adaptation (MMUDA) framework, to improve the generalization of segmentation transformers to extreme accident scenes. In MMUDA, we make use of Multi-Domain Mixed Sampling to augment the images of multiple-source domains (normal scenes) with the target data appearances (abnormal scenes). To train our model, we intertwine and study a meta-learning strategy in the multi-source setting for robustifying the segmentation results. We further enhance the segmentation backbone (SegFormer) with a HybridASPP decoder design, featuring large window attention spatial pyramid pooling and strip pooling, to efficiently aggregate long-range contextual dependencies. Our approach achieves a mIoU score of 46.97% on the DADA-seg benchmark, surpassing the previous state-of-the-art model by more than 7.50%. Code will be made publicly available at https://github.com/xinyu-laura/MMUDA.