 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHinge Regression Trees and HRT-Boost: Newton-Optimized Oblique Learning for Compact Tabular Models
May 22, 2026Learning high-quality oblique decision trees remains a significant challenge due to the discrete and non-convex nature of split optimization. We present the Hinge Regression Tree (HRT) framework, which reframes each oblique split as a nonlinear least-squares problem over two linear predictors whose max/min envelope induces ReLU-like representation capacity. We show that the resulting node-level optimization can be interpreted as a damped Newton method, and we establish the monotonic decrease of the node objective for its backtracking line-search variant. We establish, theoretically, that HRT is a universal approximator with an explicit $O(δ^2)$ approximation rate. Building upon this base learner, we propose HRT-Boost, a mathematically synergistic ensemble extension that couples node-level Newton updates with stage-wise functional gradient descent. We show that this ensemble construction admits a stage-wise empirical risk reduction guarantee under the squared loss. Empirical evaluations on synthetic and real-world benchmarks show that HRT is highly competitive with established single-tree baselines, and HRT-Boost compares favorably with strong ensemble baselines and often yields substantially more compact models. The code is publicly available at https://github.com/Hongyi-Li-sz/HRT-Boost.
Code as Agent Harness
May 18, 2026Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
Agentic Recommender System with Hierarchical Belief-State Memory
May 14, 2026Memory-augmented LLM agents have advanced personalized recommendation, yet existing approaches universally adopt flat memory representations that conflate ephemeral signals with stable preferences, and none provides a complete lifecycle governing how memory should evolve. We propose MARS (Memory-Augmented Agentic Recommender System), a framework that treats recommendation as a partially observable problem and maintains a structured belief state that progressively abstracts noisy behavioral observations into a compact estimate of user preferences. MARS organizes this belief state into three tiers: event memory buffers raw signals, preference memory maintains fine-grained mutable chunks with explicit strength and evidence tracking, and profile memory distills all preferences into a coherent natural language narrative. A complete lifecycle of six operations -- extraction, reinforcement, weakening, consolidation, forgetting, and resynthesis -- is adaptively scheduled by an LLM-based planner rather than fixed-interval heuristics. Experiments on four InstructRec benchmark domains show that \ours achieves state-of-the-art performance with average improvements of 26.4% in HR@1 and 10.3% in NDCG@10 over the strongest baselines with further gains from agentic scheduling in evolving settings.
BFLA: Block-Filtered Long-Context Attention Mechanism
May 12, 2026This paper proposes Block-Filtered Long-Context Attention (BFLA), a training-free sparse prefill attention mechanism for long-context inference. BFLA adopts a two-stage design. In Stage 1, query and key sequences are compressed into coarse blocks, and lightweight block-level softmax mass estimation is performed to construct an input-dependent block importance mask. In Stage 2, the coarse mask is expanded to the Triton attention-tile grid. Several tile-level rescue strategies are applied to reduce information loss, where a fused sparse prefill kernel skips unimportant KV tiles while preserving exact token-level attention inside every retained tile. BFLA requires no retraining, calibration, preprocessing, or model modification and can be plugged into existing vLLM-style paged-attention workloads. Experiments on Gemma 4, Llama 3.1, Qwen 3.5, and Qwen 3.6 series models show that BFLA substantially accelerates long-context prefilling with minimal accuracy degradation compared to dense Triton FlashAttention. Project website: https://github.com/Alicewithrabbit/BFLA.
Synthetic Sandbox for Training Machine Learning Engineering Agents
Apr 06, 2026As large language model agents advance beyond software engineering (SWE) tasks toward machine learning engineering (MLE), verifying agent behavior becomes orders of magnitude more expensive: while SWE tasks can be verified via fast-executing unit tests, MLE verification requires running full ML pipelines -- data preprocessing, model training, and metric evaluation -- on large datasets at each rollout step, rendering trajectory-wise on-policy reinforcement learning (RL) prohibitively slow. Existing approaches retreat to supervised fine-tuning (SFT) or offline proxy rewards, sacrificing the exploration and generalization benefits of on-policy RL. We observe that sandbox data size is the primary source of this bottleneck. Based on this insight, we introduce SandMLE, a multi-agent framework that generates diverse, verifiable synthetic MLE environments from a small number of seed tasks, preserving the structural and technical complexity of real-world problems while constraining datasets to micro-scale (each task is paired with only 50-200 training samples). Through extensive experiments, we show that SandMLE reduces execution time by over 13 times, enabling large-scale, on-policy trajectory-wise RL for the first time in the MLE domain. On MLE-bench-lite, SandMLE yields significant gains over SFT baselines across Qwen3-8B, 14B, and 30B-A3B, with relative medal rate improvements ranging from 20.3% to 66.9%. Furthermore, the trained policy generalizes across unseen agentic scaffolds, achieving up to 32.4% better HumanRank score on MLE-Dojo.
Principled Synthetic Data Enables the First Scaling Laws for LLMs in Recommendation
Feb 07, 2026Large Language Models (LLMs) represent a promising frontier for recommender systems, yet their development has been impeded by the absence of predictable scaling laws, which are crucial for guiding research and optimizing resource allocation. We hypothesize that this may be attributed to the inherent noise, bias, and incompleteness of raw user interaction data in prior continual pre-training (CPT) efforts. This paper introduces a novel, layered framework for generating high-quality synthetic data that circumvents such issues by creating a curated, pedagogical curriculum for the LLM. We provide powerful, direct evidence for the utility of our curriculum by showing that standard sequential models trained on our principled synthetic data significantly outperform ($+130\%$ on recall@100 for SasRec) models trained on real data in downstream ranking tasks, demonstrating its superiority for learning generalizable user preference patterns. Building on this, we empirically demonstrate, for the first time, robust power-law scaling for an LLM that is continually pre-trained on our high-quality, recommendation-specific data. Our experiments reveal consistent and predictable perplexity reduction across multiple synthetic data modalities. These findings establish a foundational methodology for reliable scaling LLM capabilities in the recommendation domain, thereby shifting the research focus from mitigating data deficiencies to leveraging high-quality, structured information.
Partial Domain Adaptation via Importance Sampling-based Shift Correction
Jul 27, 2025Partial domain adaptation (PDA) is a challenging task in real-world machine learning scenarios. It aims to transfer knowledge from a labeled source domain to a related unlabeled target domain, where the support set of the source label distribution subsumes the target one. Previous PDA works managed to correct the label distribution shift by weighting samples in the source domain. However, the simple reweighing technique cannot explore the latent structure and sufficiently use the labeled data, and then models are prone to over-fitting on the source domain. In this work, we propose a novel importance sampling-based shift correction (IS$^2$C) method, where new labeled data are sampled from a built sampling domain, whose label distribution is supposed to be the same as the target domain, to characterize the latent structure and enhance the generalization ability of the model. We provide theoretical guarantees for IS$^2$C by proving that the generalization error can be sufficiently dominated by IS$^2$C. In particular, by implementing sampling with the mixture distribution, the extent of shift between source and sampling domains can be connected to generalization error, which provides an interpretable way to build IS$^2$C. To improve knowledge transfer, an optimal transport-based independence criterion is proposed for conditional distribution alignment, where the computation of the criterion can be adjusted to reduce the complexity from $\mathcal{O}(n^3)$ to $\mathcal{O}(n^2)$ in realistic PDA scenarios. Extensive experiments on PDA benchmarks validate the theoretical results and demonstrate the effectiveness of our IS$^2$C over existing methods.
Thinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025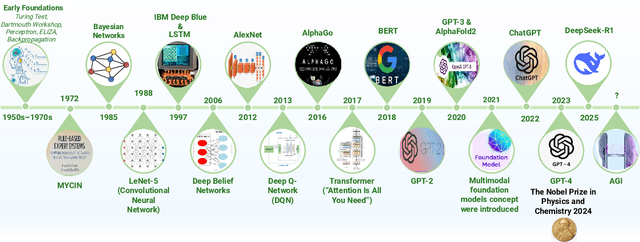
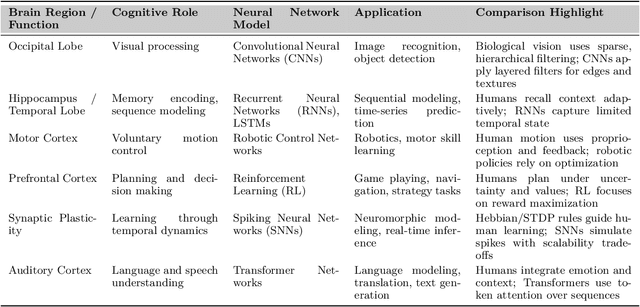
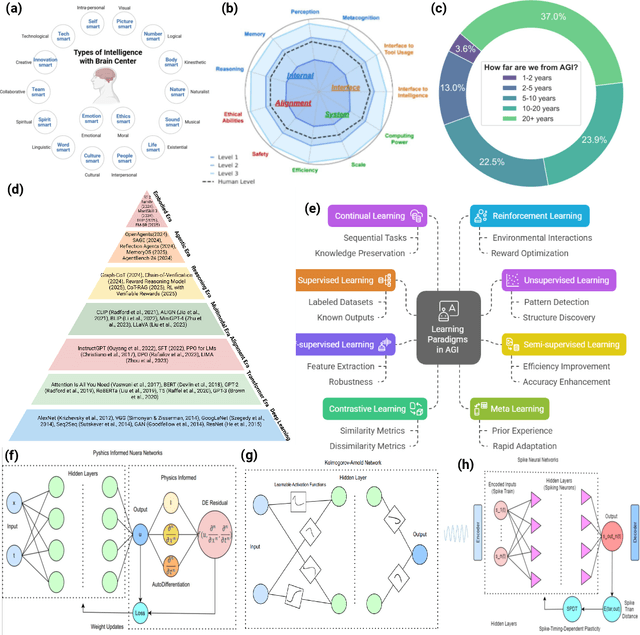
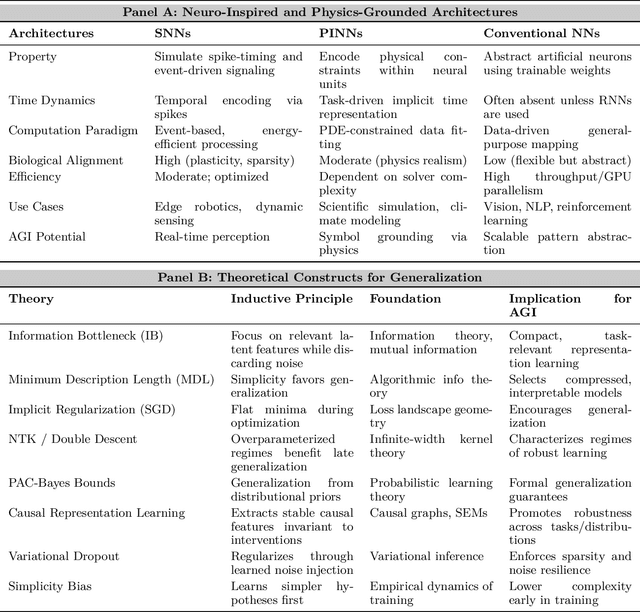
Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
An Interpretable Two-Stage Feature Decomposition Method for Deep Learning-based SAR ATR
Jun 11, 2025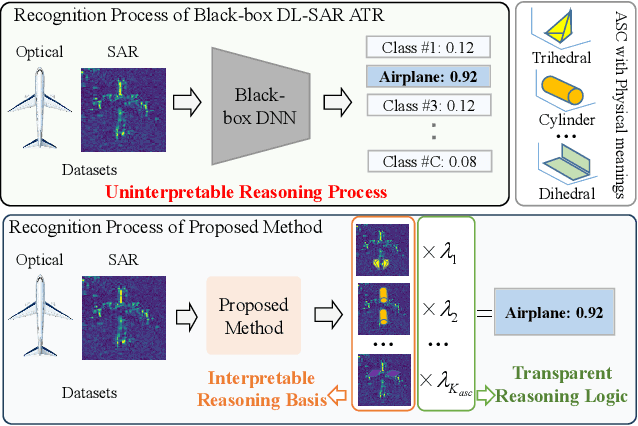
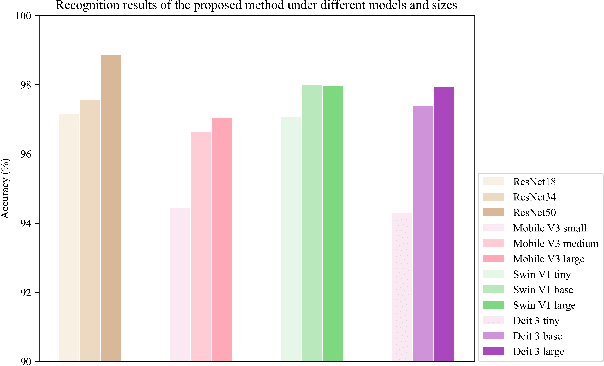
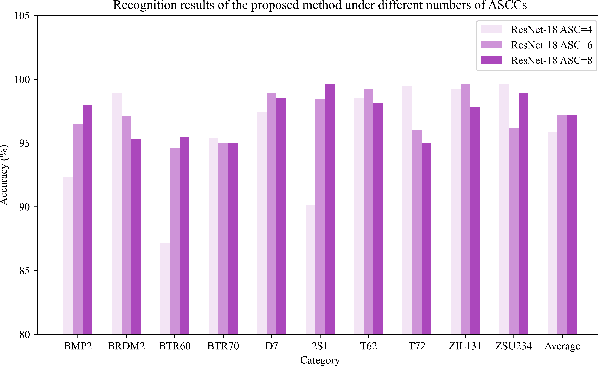
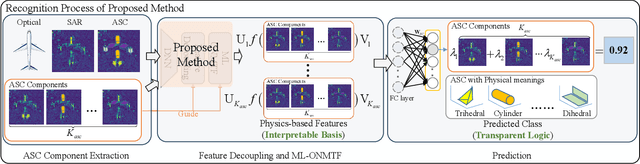
Synthetic aperture radar automatic target recognition (SAR ATR) has seen significant performance improvements with deep learning. However, the black-box nature of deep SAR ATR introduces low confidence and high risks in decision-critical SAR applications, hindering practical deployment. To address this issue, deep SAR ATR should provide an interpretable reasoning basis $r_b$ and logic $\lambda_w$, forming the reasoning logic $\sum_{i} {{r_b^i} \times {\lambda_w^i}} =pred$ behind the decisions. Therefore, this paper proposes a physics-based two-stage feature decomposition method for interpretable deep SAR ATR, which transforms uninterpretable deep features into attribute scattering center components (ASCC) with clear physical meanings. First, ASCCs are obtained through a clustering algorithm. To extract independent physical components from deep features, we propose a two-stage decomposition method. In the first stage, a feature decoupling and discrimination module separates deep features into approximate ASCCs with global discriminability. In the second stage, a multilayer orthogonal non-negative matrix tri-factorization (MLO-NMTF) further decomposes the ASCCs into independent components with distinct physical meanings. The MLO-NMTF elegantly aligns with the clustering algorithms to obtain ASCCs. Finally, this method ensures both an interpretable reasoning process and accurate recognition results. Extensive experiments on four benchmark datasets confirm its effectiveness, showcasing the method's interpretability, robust recognition performance, and strong generalization capability.
sparseGeoHOPCA: A Geometric Solution to Sparse Higher-Order PCA Without Covariance Estimation
Jun 10, 2025We propose sparseGeoHOPCA, a novel framework for sparse higher-order principal component analysis (SHOPCA) that introduces a geometric perspective to high-dimensional tensor decomposition. By unfolding the input tensor along each mode and reformulating the resulting subproblems as structured binary linear optimization problems, our method transforms the original nonconvex sparse objective into a tractable geometric form. This eliminates the need for explicit covariance estimation and iterative deflation, enabling significant gains in both computational efficiency and interpretability, particularly in high-dimensional and unbalanced data scenarios. We theoretically establish the equivalence between the geometric subproblems and the original SHOPCA formulation, and derive worst-case approximation error bounds based on classical PCA residuals, providing data-dependent performance guarantees. The proposed algorithm achieves a total computational complexity of $O\left(\sum_{n=1}^{N} (k_n^3 + J_n k_n^2)\right)$, which scales linearly with tensor size. Extensive experiments demonstrate that sparseGeoHOPCA accurately recovers sparse supports in synthetic settings, preserves classification performance under 10$\times$ compression, and achieves high-quality image reconstruction on ImageNet, highlighting its robustness and versatility.