 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025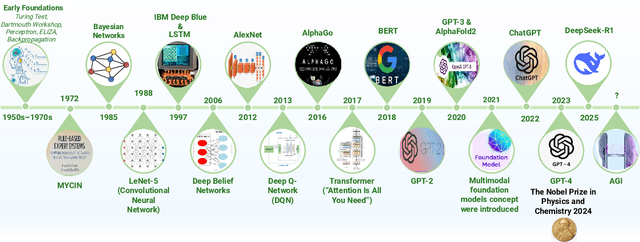
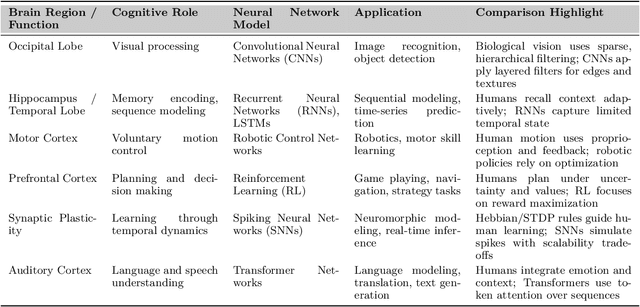
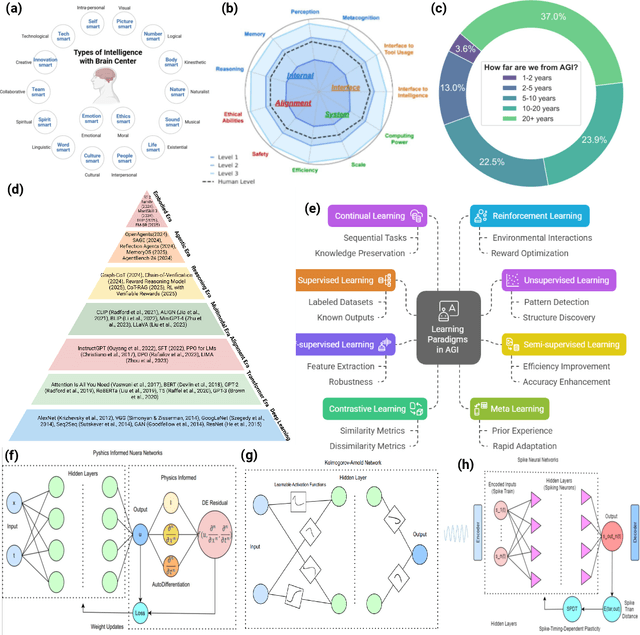
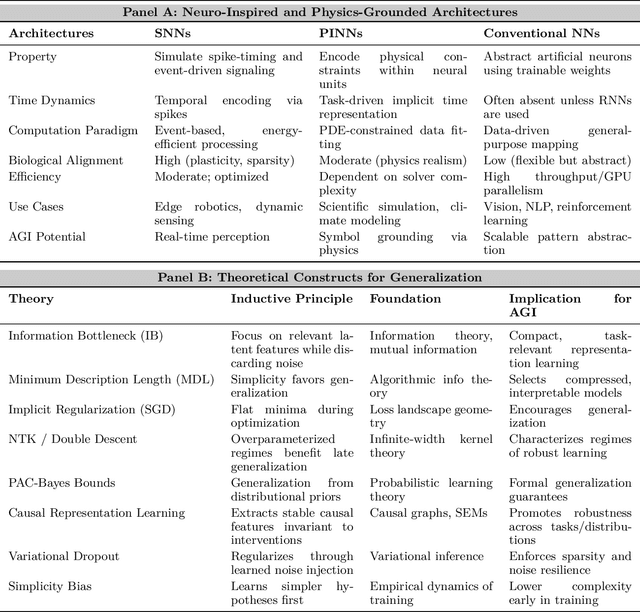
Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
A Layered Self-Supervised Knowledge Distillation Framework for Efficient Multimodal Learning on the Edge
Jun 08, 2025We introduce Layered Self-Supervised Knowledge Distillation (LSSKD) framework for training compact deep learning models. Unlike traditional methods that rely on pre-trained teacher networks, our approach appends auxiliary classifiers to intermediate feature maps, generating diverse self-supervised knowledge and enabling one-to-one transfer across different network stages. Our method achieves an average improvement of 4.54\% over the state-of-the-art PS-KD method and a 1.14% gain over SSKD on CIFAR-100, with a 0.32% improvement on ImageNet compared to HASSKD. Experiments on Tiny ImageNet and CIFAR-100 under few-shot learning scenarios also achieve state-of-the-art results. These findings demonstrate the effectiveness of our approach in enhancing model generalization and performance without the need for large over-parameterized teacher networks. Importantly, at the inference stage, all auxiliary classifiers can be removed, yielding no extra computational cost. This makes our model suitable for deploying small language models on affordable low-computing devices. Owing to its lightweight design and adaptability, our framework is particularly suitable for multimodal sensing and cyber-physical environments that require efficient and responsive inference. LSSKD facilitates the development of intelligent agents capable of learning from limited sensory data under weak supervision.
Image, Text, and Speech Data Augmentation using Multimodal LLMs for Deep Learning: A Survey
Jan 29, 2025In the past five years, research has shifted from traditional Machine Learning (ML) and Deep Learning (DL) approaches to leveraging Large Language Models (LLMs) , including multimodality, for data augmentation to enhance generalization, and combat overfitting in training deep convolutional neural networks. However, while existing surveys predominantly focus on ML and DL techniques or limited modalities (text or images), a gap remains in addressing the latest advancements and multi-modal applications of LLM-based methods. This survey fills that gap by exploring recent literature utilizing multimodal LLMs to augment image, text, and audio data, offering a comprehensive understanding of these processes. We outlined various methods employed in the LLM-based image, text and speech augmentation, and discussed the limitations identified in current approaches. Additionally, we identified potential solutions to these limitations from the literature to enhance the efficacy of data augmentation practices using multimodal LLMs. This survey serves as a foundation for future research, aiming to refine and expand the use of multimodal LLMs in enhancing dataset quality and diversity for deep learning applications. (Surveyed Paper GitHub Repo: https://github.com/WSUAgRobotics/data-aug-multi-modal-llm. Keywords: LLM data augmentation, LLM text data augmentation, LLM image data augmentation, LLM speech data augmentation, audio augmentation, voice augmentation, chatGPT for data augmentation, DeepSeek R1 text data augmentation, DeepSeek R1 image augmentation, Image Augmentation using LLM, Text Augmentation using LLM, LLM data augmentation for deep learning applications)
Low-Light Image Enhancement Framework for Improved Object Detection in Fisheye Lens Datasets
Apr 15, 2024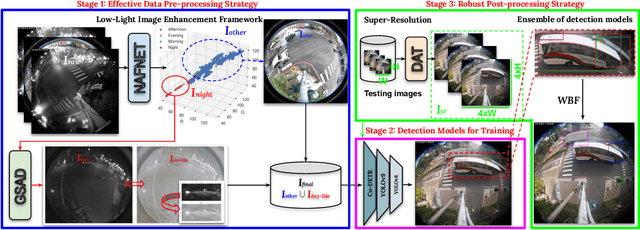
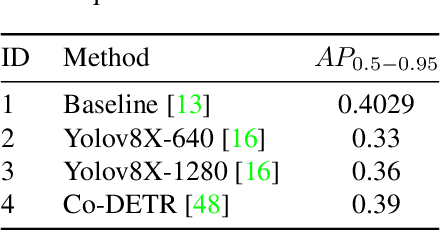


This study addresses the evolving challenges in urban traffic monitoring detection systems based on fisheye lens cameras by proposing a framework that improves the efficacy and accuracy of these systems. In the context of urban infrastructure and transportation management, advanced traffic monitoring systems have become critical for managing the complexities of urbanization and increasing vehicle density. Traditional monitoring methods, which rely on static cameras with narrow fields of view, are ineffective in dynamic urban environments, necessitating the installation of multiple cameras, which raises costs. Fisheye lenses, which were recently introduced, provide wide and omnidirectional coverage in a single frame, making them a transformative solution. However, issues such as distorted views and blurriness arise, preventing accurate object detection on these images. Motivated by these challenges, this study proposes a novel approach that combines a ransformer-based image enhancement framework and ensemble learning technique to address these challenges and improve traffic monitoring accuracy, making significant contributions to the future of intelligent traffic management systems. Our proposed methodological framework won 5th place in the 2024 AI City Challenge, Track 4, with an F1 score of 0.5965 on experimental validation data. The experimental results demonstrate the effectiveness, efficiency, and robustness of the proposed system. Our code is publicly available at https://github.com/daitranskku/AIC2024-TRACK4-TEAM15.
Enhancing Traffic Safety with Parallel Dense Video Captioning for End-to-End Event Analysis
Apr 12, 2024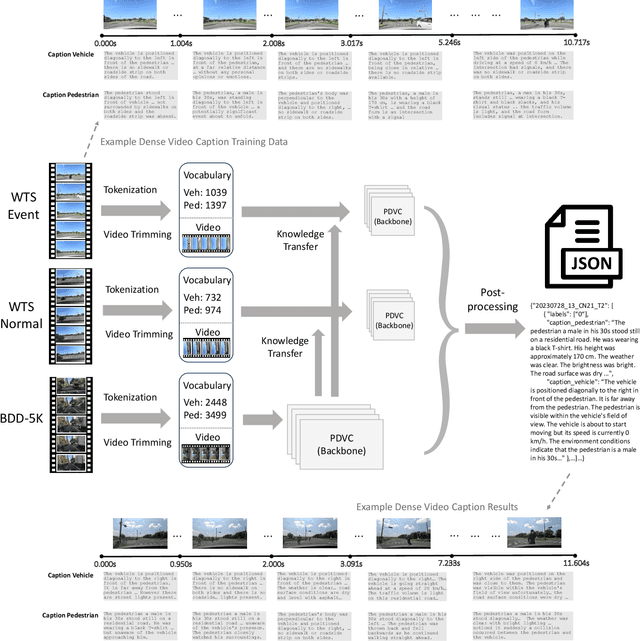


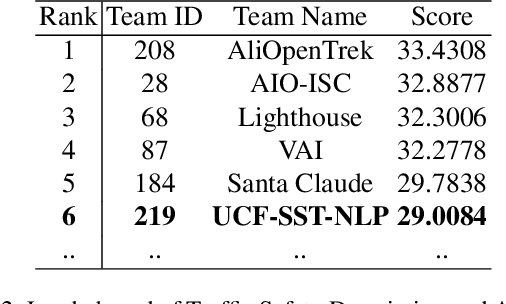
This paper introduces our solution for Track 2 in AI City Challenge 2024. The task aims to solve traffic safety description and analysis with the dataset of Woven Traffic Safety (WTS), a real-world Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding. Our solution mainly focuses on the following points: 1) To solve dense video captioning, we leverage the framework of dense video captioning with parallel decoding (PDVC) to model visual-language sequences and generate dense caption by chapters for video. 2) Our work leverages CLIP to extract visual features to more efficiently perform cross-modality training between visual and textual representations. 3) We conduct domain-specific model adaptation to mitigate domain shift problem that poses recognition challenge in video understanding. 4) Moreover, we leverage BDD-5K captioned videos to conduct knowledge transfer for better understanding WTS videos and more accurate captioning. Our solution has yielded on the test set, achieving 6th place in the competition. The open source code will be available at https://github.com/UCF-SST-Lab/AICity2024CVPRW
Quranic Conversations: Developing a Semantic Search tool for the Quran using Arabic NLP Techniques
Nov 09, 2023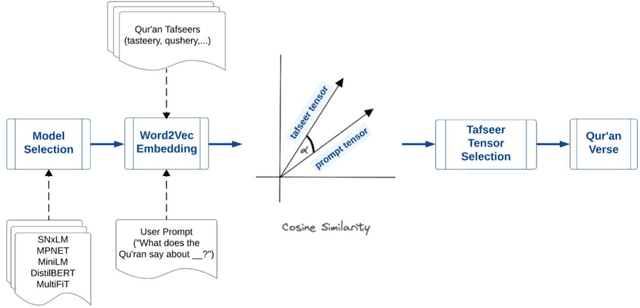



The Holy Book of Quran is believed to be the literal word of God (Allah) as revealed to the Prophet Muhammad (PBUH) over a period of approximately 23 years. It is the book where God provides guidance on how to live a righteous and just life, emphasizing principles like honesty, compassion, charity and justice, as well as providing rules for personal conduct, family matters, business ethics and much more. However, due to constraints related to the language and the Quran organization, it is challenging for Muslims to get all relevant ayahs (verses) pertaining to a matter or inquiry of interest. Hence, we developed a Quran semantic search tool which finds the verses pertaining to the user inquiry or prompt. To achieve this, we trained several models on a large dataset of over 30 tafsirs, where typically each tafsir corresponds to one verse in the Quran and, using cosine similarity, obtained the tafsir tensor which is most similar to the prompt tensor of interest, which was then used to index for the corresponding ayah in the Quran. Using the SNxLM model, we were able to achieve a cosine similarity score as high as 0.97 which corresponds to the abdu tafsir for a verse relating to financial matters.
GC-GRU-N for Traffic Prediction using Loop Detector Data
Nov 13, 2022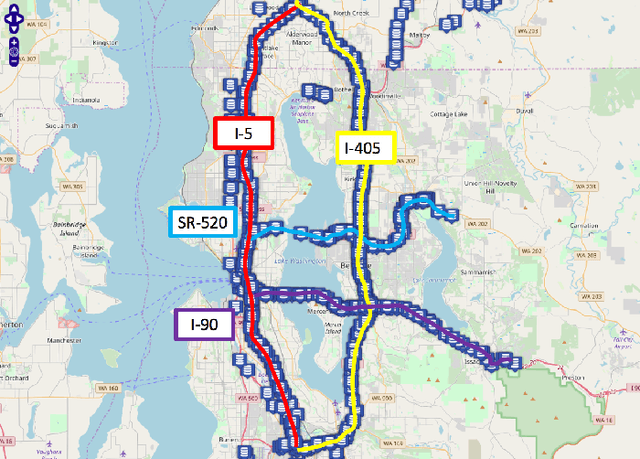

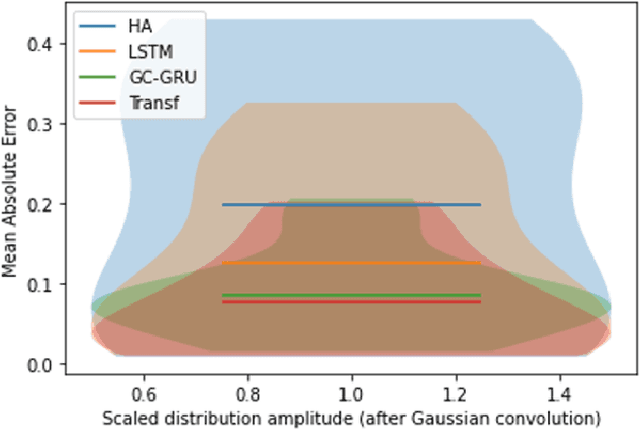
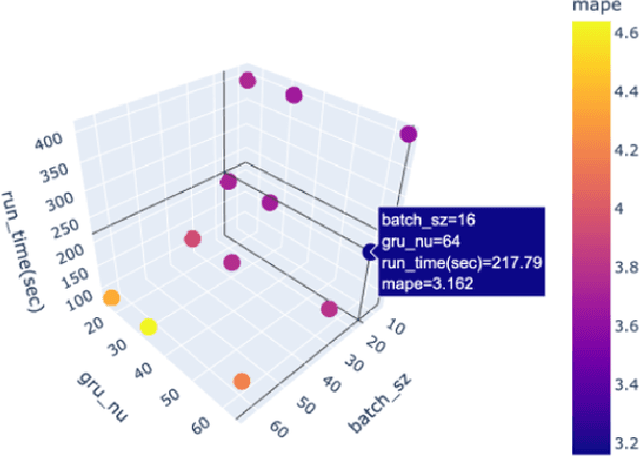
Because traffic characteristics display stochastic nonlinear spatiotemporal dependencies, traffic prediction is a challenging task. In this paper develop a graph convolution gated recurrent unit (GC GRU N) network to extract the essential Spatio temporal features. we use Seattle loop detector data aggregated over 15 minutes and reframe the problem through space and time. The model performance is compared o benchmark models; Historical Average, Long Short Term Memory (LSTM), and Transformers. The proposed model ranked second with the fastest inference time and a very close performance to first place (Transformers). Our model also achieves a running time that is six times faster than transformers. Finally, we present a comparative study of our model and the available benchmarks using metrics such as training time, inference time, MAPE, MAE and RMSE. Spatial and temporal aspects are also analyzed for each of the trained models.
A Region-Based Deep Learning Approach to Automated Retail Checkout
Apr 18, 2022
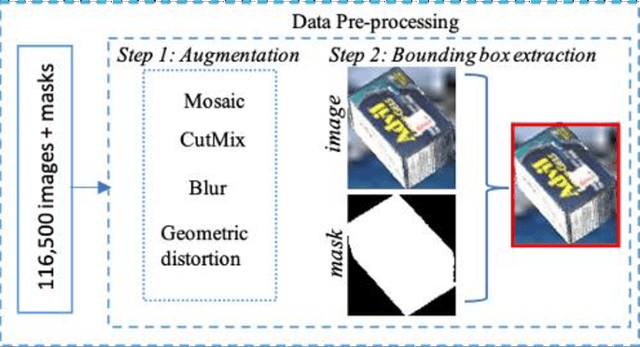
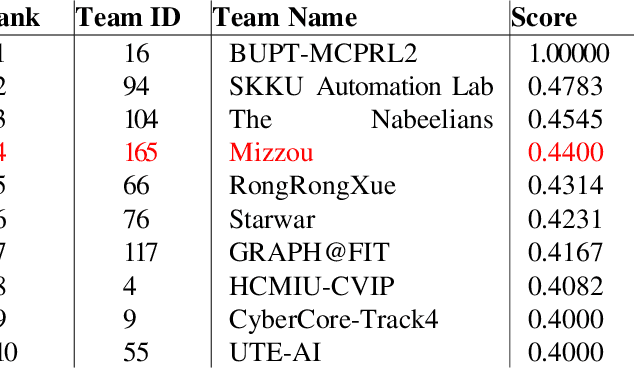
Automating the product checkout process at conventional retail stores is a task poised to have large impacts on society generally speaking. Towards this end, reliable deep learning models that enable automated product counting for fast customer checkout can make this goal a reality. In this work, we propose a novel, region-based deep learning approach to automate product counting using a customized YOLOv5 object detection pipeline and the DeepSORT algorithm. Our results on challenging, real-world test videos demonstrate that our method can generalize its predictions to a sufficient level of accuracy and with a fast enough runtime to warrant deployment to real-world commercial settings. Our proposed method won 4th place in the 2022 AI City Challenge, Track 4, with an F1 score of 0.4400 on experimental validation data.
A Vision-based System for Traffic Anomaly Detection using Deep Learning and Decision Trees
Apr 14, 2021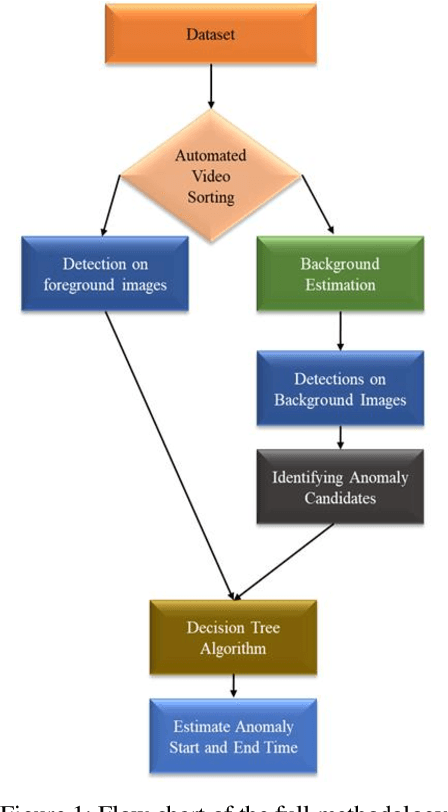

Any intelligent traffic monitoring system must be able to detect anomalies such as traffic accidents in real time. In this paper, we propose a Decision-Tree - enabled approach powered by Deep Learning for extracting anomalies from traffic cameras while accurately estimating the start and end time of the anomalous event. Our approach included creating a detection model, followed by anomaly detection and analysis. YOLOv5 served as the foundation for our detection model. The anomaly detection and analysis step entail traffic scene background estimation, road mask extraction, and adaptive thresholding. Candidate anomalies were passed through a decision tree to detect and analyze final anomalies. The proposed approach yielded an F1 score of 0.8571, and an S4 score of 0.5686, per the experimental validation.