 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReDiStory: Region-Disentangled Diffusion for Consistent Visual Story Generation
Feb 01, 2026Generating coherent visual stories requires maintaining subject identity across multiple images while preserving frame-specific semantics. Recent training-free methods concatenate identity and frame prompts into a unified representation, but this often introduces inter-frame semantic interference that weakens identity preservation in complex stories. We propose ReDiStory, a training-free framework that improves multi-frame story generation via inference-time prompt embedding reorganization. ReDiStory explicitly decomposes text embeddings into identity-related and frame-specific components, then decorrelates frame embeddings by suppressing shared directions across frames. This reduces cross-frame interference without modifying diffusion parameters or requiring additional supervision. Under identical diffusion backbones and inference settings, ReDiStory improves identity consistency while maintaining prompt fidelity. Experiments on the ConsiStory+ benchmark show consistent gains over 1Prompt1Story on multiple identity consistency metrics. Code is available at: https://github.com/YuZhenyuLindy/ReDiStory
StoryState: Agent-Based State Control for Consistent and Editable Storybooks
Feb 01, 2026Large multimodal models have enabled one-click storybook generation, where users provide a short description and receive a multi-page illustrated story. However, the underlying story state, such as characters, world settings, and page-level objects, remains implicit, making edits coarse-grained and often breaking visual consistency. We present StoryState, an agent-based orchestration layer that introduces an explicit and editable story state on top of training-free text-to-image generation. StoryState represents each story as a structured object composed of a character sheet, global settings, and per-page scene constraints, and employs a small set of LLM agents to maintain this state and derive 1Prompt1Story-style prompts for generation and editing. Operating purely through prompts, StoryState is model-agnostic and compatible with diverse generation backends. System-level experiments on multi-page editing tasks show that StoryState enables localized page edits, improves cross-page consistency, and reduces unintended changes, interaction turns, and editing time compared to 1Prompt1Story, while approaching the one-shot consistency of Gemini Storybook. Code is available at https://github.com/YuZhenyuLindy/StoryState
DeCorStory: Gram-Schmidt Prompt Embedding Decorrelation for Consistent Storytelling
Feb 01, 2026Maintaining visual and semantic consistency across frames is a key challenge in text-to-image storytelling. Existing training-free methods, such as One-Prompt-One-Story, concatenate all prompts into a single sequence, which often induces strong embedding correlation and leads to color leakage, background blending, and identity drift. We propose DeCorStory, a training-free inference-time framework that explicitly reduces inter-frame semantic interference. DeCorStory applies Gram-Schmidt prompt embedding decorrelation to orthogonalize frame-level semantics, followed by singular value reweighting to strengthen prompt-specific information and identity-preserving cross-attention to stabilize character identity during diffusion. The method requires no model modification or fine-tuning and can be seamlessly integrated into existing diffusion pipelines. Experiments demonstrate consistent improvements in prompt-image alignment, identity consistency, and visual diversity, achieving state-of-the-art performance among training-free baselines. Code is available at: https://github.com/YuZhenyuLindy/DeCorStory
Adaptive Detector-Verifier Framework for Zero-Shot Polyp Detection in Open-World Settings
Dec 16, 2025Polyp detectors trained on clean datasets often underperform in real-world endoscopy, where illumination changes, motion blur, and occlusions degrade image quality. Existing approaches struggle with the domain gap between controlled laboratory conditions and clinical practice, where adverse imaging conditions are prevalent. In this work, we propose AdaptiveDetector, a novel two-stage detector-verifier framework comprising a YOLOv11 detector with a vision-language model (VLM) verifier. The detector adaptively adjusts per-frame confidence thresholds under VLM guidance, while the verifier is fine-tuned with Group Relative Policy Optimization (GRPO) using an asymmetric, cost-sensitive reward function specifically designed to discourage missed detections -- a critical clinical requirement. To enable realistic assessment under challenging conditions, we construct a comprehensive synthetic testbed by systematically degrading clean datasets with adverse conditions commonly encountered in clinical practice, providing a rigorous benchmark for zero-shot evaluation. Extensive zero-shot evaluation on synthetically degraded CVC-ClinicDB and Kvasir-SEG images demonstrates that our approach improves recall by 14 to 22 percentage points over YOLO alone, while precision remains within 0.7 points below to 1.7 points above the baseline. This combination of adaptive thresholding and cost-sensitive reinforcement learning achieves clinically aligned, open-world polyp detection with substantially fewer false negatives, thereby reducing the risk of missed precancerous polyps and improving patient outcomes.
A Layered Self-Supervised Knowledge Distillation Framework for Efficient Multimodal Learning on the Edge
Jun 08, 2025We introduce Layered Self-Supervised Knowledge Distillation (LSSKD) framework for training compact deep learning models. Unlike traditional methods that rely on pre-trained teacher networks, our approach appends auxiliary classifiers to intermediate feature maps, generating diverse self-supervised knowledge and enabling one-to-one transfer across different network stages. Our method achieves an average improvement of 4.54\% over the state-of-the-art PS-KD method and a 1.14% gain over SSKD on CIFAR-100, with a 0.32% improvement on ImageNet compared to HASSKD. Experiments on Tiny ImageNet and CIFAR-100 under few-shot learning scenarios also achieve state-of-the-art results. These findings demonstrate the effectiveness of our approach in enhancing model generalization and performance without the need for large over-parameterized teacher networks. Importantly, at the inference stage, all auxiliary classifiers can be removed, yielding no extra computational cost. This makes our model suitable for deploying small language models on affordable low-computing devices. Owing to its lightweight design and adaptability, our framework is particularly suitable for multimodal sensing and cyber-physical environments that require efficient and responsive inference. LSSKD facilitates the development of intelligent agents capable of learning from limited sensory data under weak supervision.
SatelliteFormula: Multi-Modal Symbolic Regression from Remote Sensing Imagery for Physics Discovery
Jun 06, 2025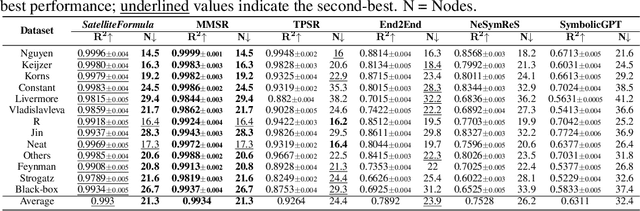
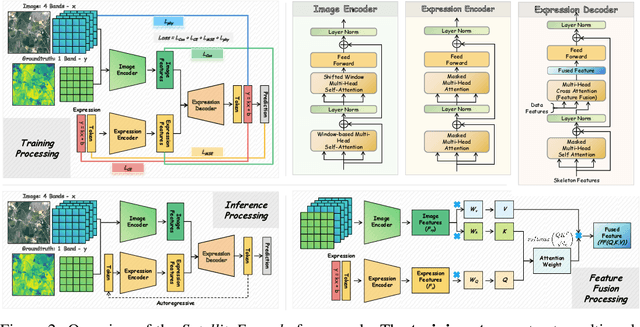
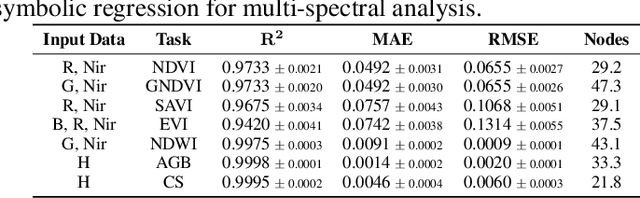
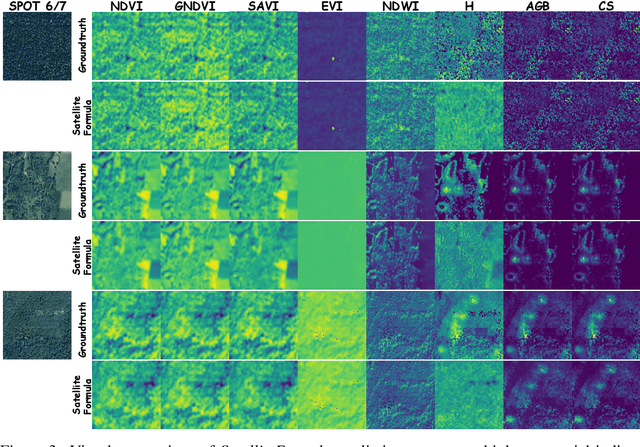
We propose SatelliteFormula, a novel symbolic regression framework that derives physically interpretable expressions directly from multi-spectral remote sensing imagery. Unlike traditional empirical indices or black-box learning models, SatelliteFormula combines a Vision Transformer-based encoder for spatial-spectral feature extraction with physics-guided constraints to ensure consistency and interpretability. Existing symbolic regression methods struggle with the high-dimensional complexity of multi-spectral data; our method addresses this by integrating transformer representations into a symbolic optimizer that balances accuracy and physical plausibility. Extensive experiments on benchmark datasets and remote sensing tasks demonstrate superior performance, stability, and generalization compared to state-of-the-art baselines. SatelliteFormula enables interpretable modeling of complex environmental variables, bridging the gap between data-driven learning and physical understanding.
When Cloud Removal Meets Diffusion Model in Remote Sensing
Apr 21, 2025Cloud occlusion significantly hinders remote sensing applications by obstructing surface information and complicating analysis. To address this, we propose DC4CR (Diffusion Control for Cloud Removal), a novel multimodal diffusion-based framework for cloud removal in remote sensing imagery. Our method introduces prompt-driven control, allowing selective removal of thin and thick clouds without relying on pre-generated cloud masks, thereby enhancing preprocessing efficiency and model adaptability. Additionally, we integrate low-rank adaptation for computational efficiency, subject-driven generation for improved generalization, and grouped learning to enhance performance on small datasets. Designed as a plug-and-play module, DC4CR seamlessly integrates into existing cloud removal models, providing a scalable and robust solution. Extensive experiments on the RICE and CUHK-CR datasets demonstrate state-of-the-art performance, achieving superior cloud removal across diverse conditions. This work presents a practical and efficient approach for remote sensing image processing with broad real-world applications.
SatelliteCalculator: A Multi-Task Vision Foundation Model for Quantitative Remote Sensing Inversion
Apr 18, 2025



Quantitative remote sensing inversion plays a critical role in environmental monitoring, enabling the estimation of key ecological variables such as vegetation indices, canopy structure, and carbon stock. Although vision foundation models have achieved remarkable progress in classification and segmentation tasks, their application to physically interpretable regression remains largely unexplored. Furthermore, the multi-spectral nature and geospatial heterogeneity of remote sensing data pose significant challenges for generalization and transferability. To address these issues, we introduce SatelliteCalculator, the first vision foundation model tailored for quantitative remote sensing inversion. By leveraging physically defined index formulas, we automatically construct a large-scale dataset of over one million paired samples across eight core ecological indicators. The model integrates a frozen Swin Transformer backbone with a prompt-guided architecture, featuring cross-attentive adapters and lightweight task-specific MLP decoders. Experiments on the Open-Canopy benchmark demonstrate that SatelliteCalculator achieves competitive accuracy across all tasks while significantly reducing inference cost. Our results validate the feasibility of applying foundation models to quantitative inversion, and provide a scalable framework for task-adaptive remote sensing estimation.
Point-Driven Interactive Text and Image Layer Editing Using Diffusion Models
Apr 18, 2025We present DanceText, a training-free framework for multilingual text editing in images, designed to support complex geometric transformations and achieve seamless foreground-background integration. While diffusion-based generative models have shown promise in text-guided image synthesis, they often lack controllability and fail to preserve layout consistency under non-trivial manipulations such as rotation, translation, scaling, and warping. To address these limitations, DanceText introduces a layered editing strategy that separates text from the background, allowing geometric transformations to be performed in a modular and controllable manner. A depth-aware module is further proposed to align appearance and perspective between the transformed text and the reconstructed background, enhancing photorealism and spatial consistency. Importantly, DanceText adopts a fully training-free design by integrating pretrained modules, allowing flexible deployment without task-specific fine-tuning. Extensive experiments on the AnyWord-3M benchmark demonstrate that our method achieves superior performance in visual quality, especially under large-scale and complex transformation scenarios.
Prompt-Driven and Training-Free Forgetting Approach and Dataset for Large Language Models
Apr 17, 2025The widespread adoption of diffusion models in image generation has increased the demand for privacy-compliant unlearning. However, due to the high-dimensional nature and complex feature representations of diffusion models, achieving selective unlearning remains challenging, as existing methods struggle to remove sensitive information while preserving the consistency of non-sensitive regions. To address this, we propose an Automatic Dataset Creation Framework based on prompt-based layered editing and training-free local feature removal, constructing the ForgetMe dataset and introducing the Entangled evaluation metric. The Entangled metric quantifies unlearning effectiveness by assessing the similarity and consistency between the target and background regions and supports both paired (Entangled-D) and unpaired (Entangled-S) image data, enabling unsupervised evaluation. The ForgetMe dataset encompasses a diverse set of real and synthetic scenarios, including CUB-200-2011 (Birds), Stanford-Dogs, ImageNet, and a synthetic cat dataset. We apply LoRA fine-tuning on Stable Diffusion to achieve selective unlearning on this dataset and validate the effectiveness of both the ForgetMe dataset and the Entangled metric, establishing them as benchmarks for selective unlearning. Our work provides a scalable and adaptable solution for advancing privacy-preserving generative AI.