 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatelliteFormula: Multi-Modal Symbolic Regression from Remote Sensing Imagery for Physics Discovery
Jun 06, 2025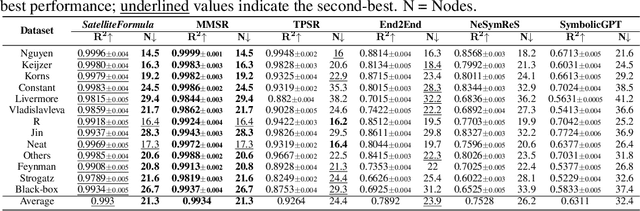
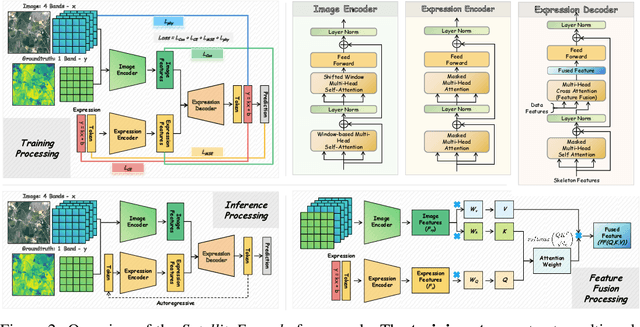
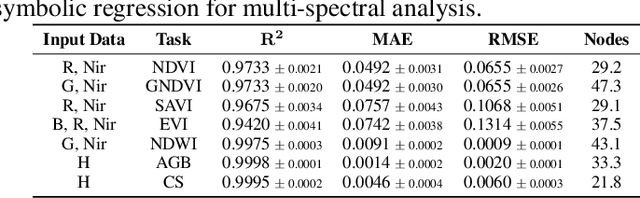
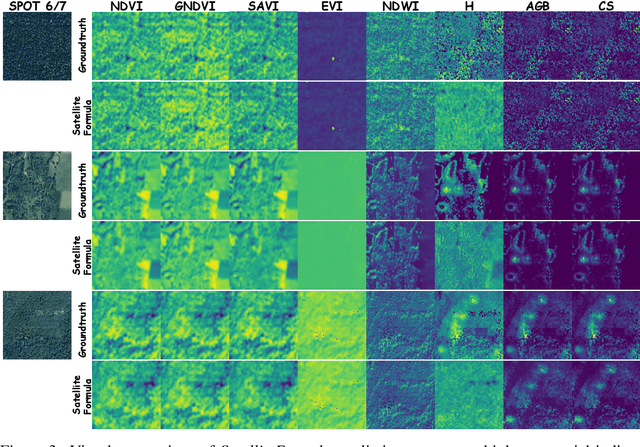
We propose SatelliteFormula, a novel symbolic regression framework that derives physically interpretable expressions directly from multi-spectral remote sensing imagery. Unlike traditional empirical indices or black-box learning models, SatelliteFormula combines a Vision Transformer-based encoder for spatial-spectral feature extraction with physics-guided constraints to ensure consistency and interpretability. Existing symbolic regression methods struggle with the high-dimensional complexity of multi-spectral data; our method addresses this by integrating transformer representations into a symbolic optimizer that balances accuracy and physical plausibility. Extensive experiments on benchmark datasets and remote sensing tasks demonstrate superior performance, stability, and generalization compared to state-of-the-art baselines. SatelliteFormula enables interpretable modeling of complex environmental variables, bridging the gap between data-driven learning and physical understanding.
Point-Driven Interactive Text and Image Layer Editing Using Diffusion Models
Apr 18, 2025We present DanceText, a training-free framework for multilingual text editing in images, designed to support complex geometric transformations and achieve seamless foreground-background integration. While diffusion-based generative models have shown promise in text-guided image synthesis, they often lack controllability and fail to preserve layout consistency under non-trivial manipulations such as rotation, translation, scaling, and warping. To address these limitations, DanceText introduces a layered editing strategy that separates text from the background, allowing geometric transformations to be performed in a modular and controllable manner. A depth-aware module is further proposed to align appearance and perspective between the transformed text and the reconstructed background, enhancing photorealism and spatial consistency. Importantly, DanceText adopts a fully training-free design by integrating pretrained modules, allowing flexible deployment without task-specific fine-tuning. Extensive experiments on the AnyWord-3M benchmark demonstrate that our method achieves superior performance in visual quality, especially under large-scale and complex transformation scenarios.
Two-stage Progressive Residual Dense Attention Network for Image Denoising
Jan 05, 2024Deep convolutional neural networks (CNNs) for image denoising can effectively exploit rich hierarchical features and have achieved great success. However, many deep CNN-based denoising models equally utilize the hierarchical features of noisy images without paying attention to the more important and useful features, leading to relatively low performance. To address the issue, we design a new Two-stage Progressive Residual Dense Attention Network (TSP-RDANet) for image denoising, which divides the whole process of denoising into two sub-tasks to remove noise progressively. Two different attention mechanism-based denoising networks are designed for the two sequential sub-tasks: the residual dense attention module (RDAM) is designed for the first stage, and the hybrid dilated residual dense attention module (HDRDAM) is proposed for the second stage. The proposed attention modules are able to learn appropriate local features through dense connection between different convolutional layers, and the irrelevant features can also be suppressed. The two sub-networks are then connected by a long skip connection to retain the shallow feature to enhance the denoising performance. The experiments on seven benchmark datasets have verified that compared with many state-of-the-art methods, the proposed TSP-RDANet can obtain favorable results both on synthetic and real noisy image denoising. The code of our TSP-RDANet is available at https://github.com/WenCongWu/TSP-RDANet.
DCANet: Dual Convolutional Neural Network with Attention for Image Blind Denoising
Apr 04, 2023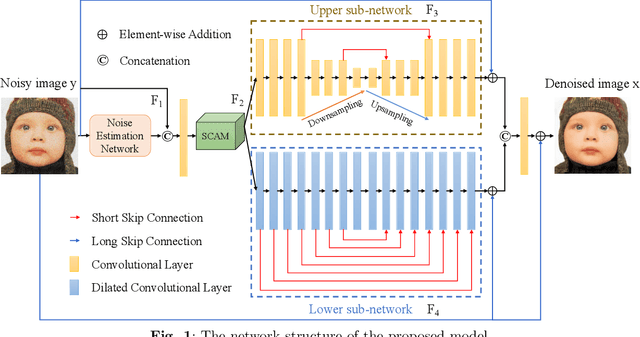


Noise removal of images is an essential preprocessing procedure for many computer vision tasks. Currently, many denoising models based on deep neural networks can perform well in removing the noise with known distributions (i.e. the additive Gaussian white noise). However eliminating real noise is still a very challenging task, since real-world noise often does not simply follow one single type of distribution, and the noise may spatially vary. In this paper, we present a new dual convolutional neural network (CNN) with attention for image blind denoising, named as the DCANet. To the best of our knowledge, the proposed DCANet is the first work that integrates both the dual CNN and attention mechanism for image denoising. The DCANet is composed of a noise estimation network, a spatial and channel attention module (SCAM), and a CNN with a dual structure. The noise estimation network is utilized to estimate the spatial distribution and the noise level in an image. The noisy image and its estimated noise are combined as the input of the SCAM, and a dual CNN contains two different branches is designed to learn the complementary features to obtain the denoised image. The experimental results have verified that the proposed DCANet can suppress both synthetic and real noise effectively. The code of DCANet is available at https://github.com/WenCongWu/DCANet.