 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIVM: Diffusion-Based Prior-Integrated Variation Modeling for Anatomically Precise Abdominal CT Synthesis
Mar 23, 2026Abdominal CT data are limited by high annotation costs and privacy constraints, which hinder the development of robust segmentation and diagnostic models. We present a Prior-Integrated Variation Modeling (PIVM) framework, a diffusion-based method for anatomically accurate CT image synthesis. Instead of generating full images from noise, PIVM predicts voxel-wise intensity variations relative to organ-specific intensity priors derived from segmentation labels. These priors and labels jointly guide the diffusion process, ensuring spatial alignment and realistic organ boundaries. Unlike latent-space diffusion models, our approach operates directly in image space while preserving the full Hounsfield Unit (HU) range, capturing fine anatomical textures without smoothing. Source code is available at https://github.com/BZNR3/PIVM.
Robust and Explainable Framework to Address Data Scarcity in Diagnostic Imaging
Jul 09, 2024Deep learning has significantly advanced automatic medical diagnostics and released the occupation of human resources to reduce clinical pressure, yet the persistent challenge of data scarcity in this area hampers its further improvements and applications. To address this gap, we introduce a novel ensemble framework called `Efficient Transfer and Self-supervised Learning based Ensemble Framework' (ETSEF). ETSEF leverages features from multiple pre-trained deep learning models to efficiently learn powerful representations from a limited number of data samples. To the best of our knowledge, ETSEF is the first strategy that combines two pre-training methodologies (Transfer Learning and Self-supervised Learning) with ensemble learning approaches. Various data enhancement techniques, including data augmentation, feature fusion, feature selection, and decision fusion, have also been deployed to maximise the efficiency and robustness of the ETSEF model. Five independent medical imaging tasks, including endoscopy, breast cancer, monkeypox, brain tumour, and glaucoma detection, were tested to demonstrate ETSEF's effectiveness and robustness. Facing limited sample numbers and challenging medical tasks, ETSEF has proved its effectiveness by improving diagnostics accuracies from 10\% to 13.3\% when compared to strong ensemble baseline models and up to 14.4\% improvements compared with published state-of-the-art methods. Moreover, we emphasise the robustness and trustworthiness of the ETSEF method through various vision-explainable artificial intelligence techniques, including Grad-CAM, SHAP, and t-SNE. Compared to those large-scale deep learning models, ETSEF can be deployed flexibly and maintain superior performance for challenging medical imaging tasks, showing the potential to be applied to more areas that lack training data
An Experimental Comparison of Transfer Learning against Self-supervised Learning
Jul 08, 2024Recently, transfer learning and self-supervised learning have gained significant attention within the medical field due to their ability to mitigate the challenges posed by limited data availability, improve model generalisation, and reduce computational expenses. Transfer learning and self-supervised learning hold immense potential for advancing medical research. However, it is crucial to recognise that transfer learning and self-supervised learning architectures exhibit distinct advantages and limitations, manifesting variations in accuracy, training speed, and robustness. This paper compares the performance and robustness of transfer learning and self-supervised learning in the medical field. Specifically, we pre-trained two models using the same source domain datasets with different pre-training methods and evaluated them on small-sized medical datasets to identify the factors influencing their final performance. We tested data with several common issues in medical domains, such as data imbalance, data scarcity, and domain mismatch, through comparison experiments to understand their impact on specific pre-trained models. Finally, we provide recommendations to help users apply transfer learning and self-supervised learning methods in medical areas, and build more convenient and efficient deployment strategies.
Semi-Supervised Representative Region Texture Extraction of Façade
Dec 05, 2022



Researches of analysis and parsing around fa\c{c}ades to enrich the 3D feature of fa\c{c}ade models by semantic information raised some attention in the community, whose main idea is to generate higher resolution components with similar shapes and textures to increase the overall resolution at the expense of reconstruction accuracy. While this approach works well for components like windows and doors, there is no solution for fa\c{c}ade background at present. In this paper, we introduce the concept of representative region texture, which can be used in the above modeling approach by tiling the representative texture around the fa\c{c}ade region, and propose a semi-supervised way to do representative region texture extraction from a fa\c{c}ade image. Our method does not require any additional labelled data to train as long as the semantic information is given, while a traditional end-to-end model requires plenty of data to increase its performance. Our method can extract texture from any repetitive images, not just fa\c{c}ade, which is not capable in an end-to-end model as it relies on the distribution of training set. Clustering with weighted distance is introduced to further increase the robustness to noise or an imprecise segmentation, and make the extracted texture have a higher resolution and more suitable for tiling. We verify our method on various fa\c{c}ade images, and the result shows our method has a significant performance improvement compared to only a random crop on fa\c{c}ade. We also demonstrate some application scenarios and proposed a fa\c{c}ade modeling workflow with the representative region texture, which has a better visual resolution for a regular fa\c{c}ade.
Multi-scale Network with Attentional Multi-resolution Fusion for Point Cloud Semantic Segmentation
Jun 27, 2022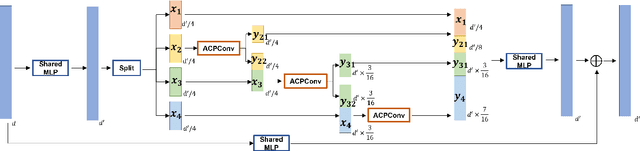
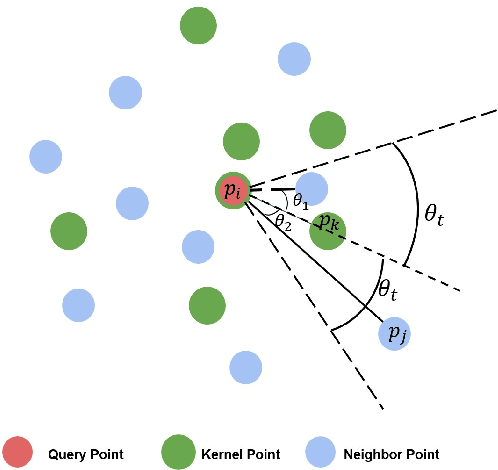
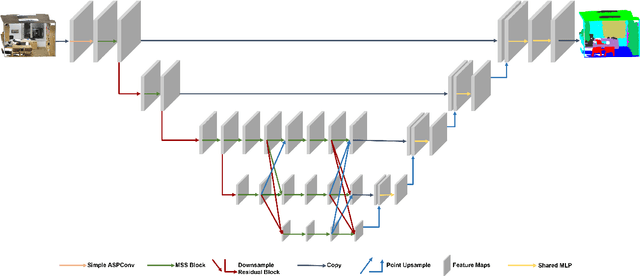
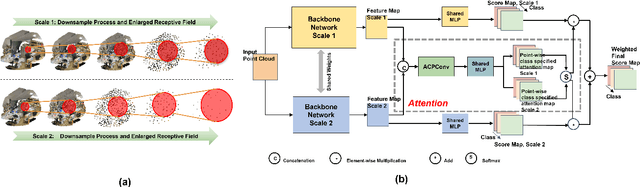
In this paper, we present a comprehensive point cloud semantic segmentation network that aggregates both local and global multi-scale information. First, we propose an Angle Correlation Point Convolution (ACPConv) module to effectively learn the local shapes of points. Second, based upon ACPConv, we introduce a local multi-scale split (MSS) block that hierarchically connects features within one single block and gradually enlarges the receptive field which is beneficial for exploiting the local context. Third, inspired by HRNet which has excellent performance on 2D image vision tasks, we build an HRNet customized for point cloud to learn global multi-scale context. Lastly, we introduce a point-wise attention fusion approach that fuses multi-resolution predictions and further improves point cloud semantic segmentation performance. Our experimental results and ablations on several benchmark datasets show that our proposed method is effective and able to achieve state-of-the-art performances compared to existing methods.
A Region-Based Deep Learning Approach to Automated Retail Checkout
Apr 18, 2022
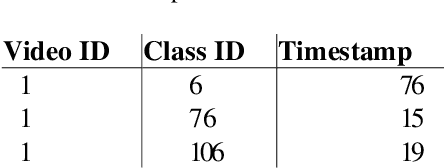
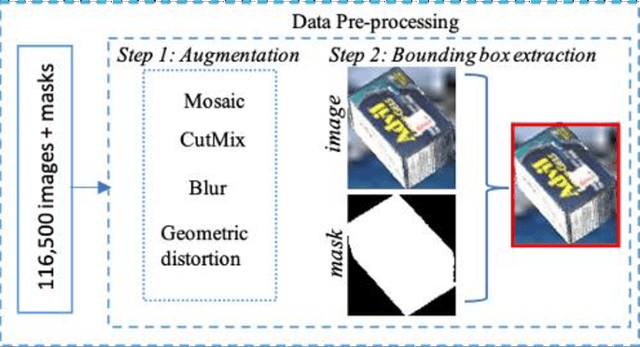
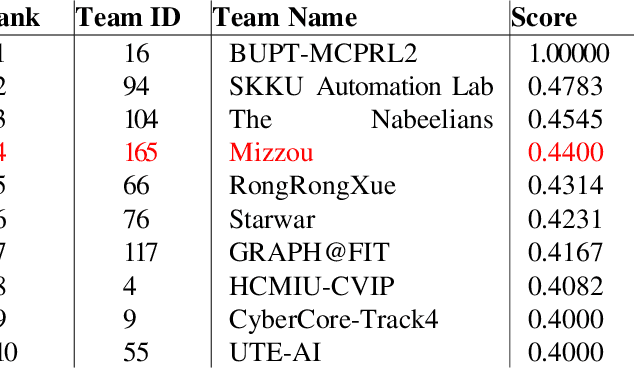
Automating the product checkout process at conventional retail stores is a task poised to have large impacts on society generally speaking. Towards this end, reliable deep learning models that enable automated product counting for fast customer checkout can make this goal a reality. In this work, we propose a novel, region-based deep learning approach to automate product counting using a customized YOLOv5 object detection pipeline and the DeepSORT algorithm. Our results on challenging, real-world test videos demonstrate that our method can generalize its predictions to a sufficient level of accuracy and with a fast enough runtime to warrant deployment to real-world commercial settings. Our proposed method won 4th place in the 2022 AI City Challenge, Track 4, with an F1 score of 0.4400 on experimental validation data.
OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion
Mar 29, 2022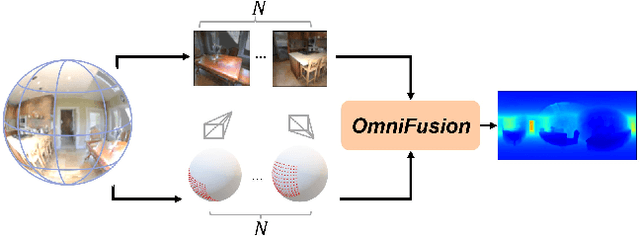
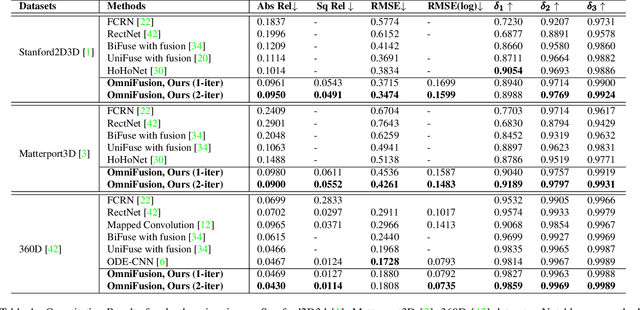
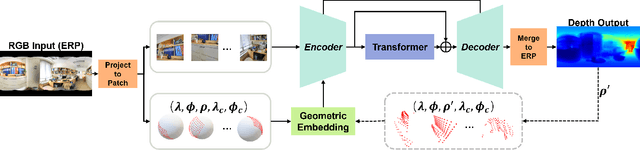

A well-known challenge in applying deep-learning methods to omnidirectional images is spherical distortion. In dense regression tasks such as depth estimation, where structural details are required, using a vanilla CNN layer on the distorted 360 image results in undesired information loss. In this paper, we propose a 360 monocular depth estimation pipeline, OmniFusion, to tackle the spherical distortion issue. Our pipeline transforms a 360 image into less-distorted perspective patches (i.e. tangent images) to obtain patch-wise predictions via CNN, and then merge the patch-wise results for final output. To handle the discrepancy between patch-wise predictions which is a major issue affecting the merging quality, we propose a new framework with the following key components. First, we propose a geometry-aware feature fusion mechanism that combines 3D geometric features with 2D image features to compensate for the patch-wise discrepancy. Second, we employ the self-attention-based transformer architecture to conduct a global aggregation of patch-wise information, which further improves the consistency. Last, we introduce an iterative depth refinement mechanism, to further refine the estimated depth based on the more accurate geometric features. Experiments show that our method greatly mitigates the distortion issue, and achieves state-of-the-art performances on several 360 monocular depth estimation benchmark datasets.
PanoDepth: A Two-Stage Approach for Monocular Omnidirectional Depth Estimation
Feb 02, 2022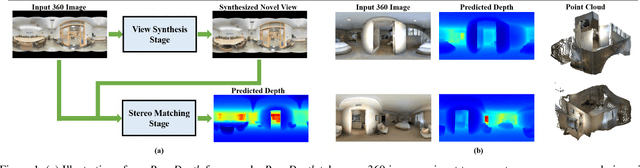
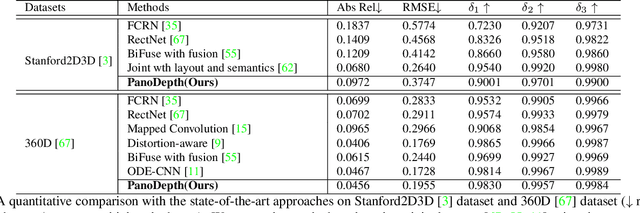
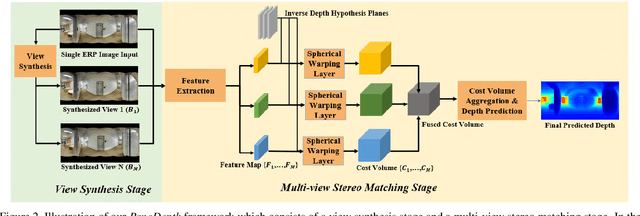

Omnidirectional 3D information is essential for a wide range of applications such as Virtual Reality, Autonomous Driving, Robotics, etc. In this paper, we propose a novel, model-agnostic, two-stage pipeline for omnidirectional monocular depth estimation. Our proposed framework PanoDepth takes one 360 image as input, produces one or more synthesized views in the first stage, and feeds the original image and the synthesized images into the subsequent stereo matching stage. In the second stage, we propose a differentiable Spherical Warping Layer to handle omnidirectional stereo geometry efficiently and effectively. By utilizing the explicit stereo-based geometric constraints in the stereo matching stage, PanoDepth can generate dense high-quality depth. We conducted extensive experiments and ablation studies to evaluate PanoDepth with both the full pipeline as well as the individual modules in each stage. Our results show that PanoDepth outperforms the state-of-the-art approaches by a large margin for 360 monocular depth estimation.
MedNet: Pre-trained Convolutional Neural Network Model for the Medical Imaging Tasks
Oct 13, 2021
Deep Learning (DL) requires a large amount of training data to provide quality outcomes. However, the field of medical imaging suffers from the lack of sufficient data for properly training DL models because medical images require manual labelling carried out by clinical experts thus the process is time-consuming, expensive, and error-prone. Recently, transfer learning (TL) was introduced to reduce the need for the annotation procedure by means of transferring the knowledge performed by a previous task and then fine-tuning the result using a relatively small dataset. Nowadays, multiple classification methods from medical imaging make use of TL from general-purpose pre-trained models, e.g., ImageNet, which has been proven to be ineffective due to the mismatch between the features learned from natural images (ImageNet) and those more specific from medical images especially medical gray images such as X-rays. ImageNet does not have grayscale images such as MRI, CT, and X-ray. In this paper, we propose a novel DL model to be used for addressing classification tasks of medical imaging, called MedNet. To do so, we aim to issue two versions of MedNet. The first one is Gray-MedNet which will be trained on 3M publicly available gray-scale medical images including MRI, CT, X-ray, ultrasound, and PET. The second version is Color-MedNet which will be trained on 3M publicly available color medical images including histopathology, taken images, and many others. To validate the effectiveness MedNet, both versions will be fine-tuned to train on the target tasks of a more reduced set of medical images. MedNet performs as the pre-trained model to tackle any real-world application from medical imaging and achieve the level of generalization needed for dealing with medical imaging tasks, e.g. classification. MedNet would serve the research community as a baseline for future research.
Fast Point Voxel Convolution Neural Network with Selective Feature Fusion for Point Cloud Semantic Segmentation
Sep 23, 2021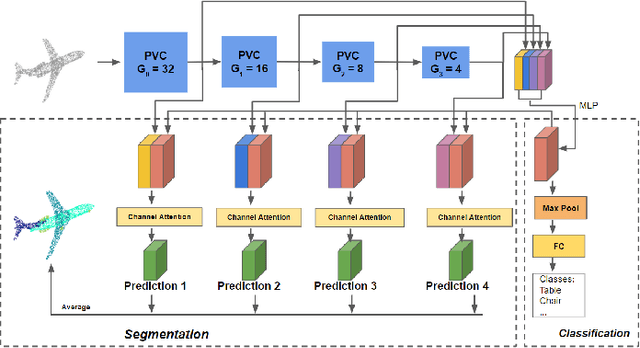
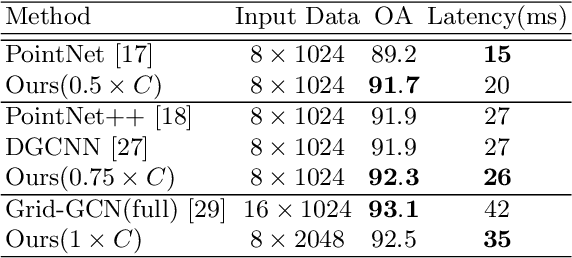
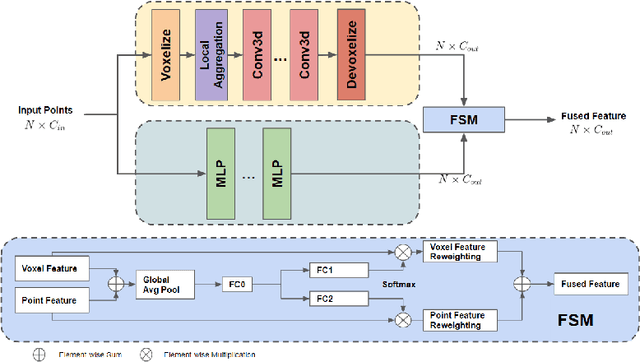
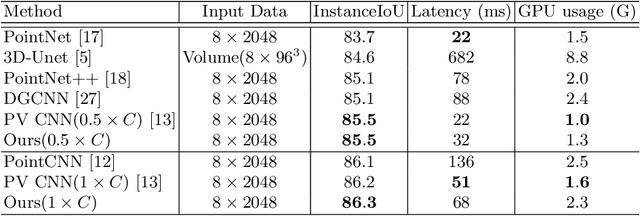
We present a novel lightweight convolutional neural network for point cloud analysis. In contrast to many current CNNs which increase receptive field by downsampling point cloud, our method directly operates on the entire point sets without sampling and achieves good performances efficiently. Our network consists of point voxel convolution (PVC) layer as building block. Each layer has two parallel branches, namely the voxel branch and the point branch. For the voxel branch specifically, we aggregate local features on non-empty voxel centers to reduce geometric information loss caused by voxelization, then apply volumetric convolutions to enhance local neighborhood geometry encoding. For the point branch, we use Multi-Layer Perceptron (MLP) to extract fine-detailed point-wise features. Outputs from these two branches are adaptively fused via a feature selection module. Moreover, we supervise the output from every PVC layer to learn different levels of semantic information. The final prediction is made by averaging all intermediate predictions. We demonstrate empirically that our method is able to achieve comparable results while being fast and memory efficient. We evaluate our method on popular point cloud datasets for object classification and semantic segmentation tasks.