 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Explainable Framework to Address Data Scarcity in Diagnostic Imaging
Jul 09, 2024Deep learning has significantly advanced automatic medical diagnostics and released the occupation of human resources to reduce clinical pressure, yet the persistent challenge of data scarcity in this area hampers its further improvements and applications. To address this gap, we introduce a novel ensemble framework called `Efficient Transfer and Self-supervised Learning based Ensemble Framework' (ETSEF). ETSEF leverages features from multiple pre-trained deep learning models to efficiently learn powerful representations from a limited number of data samples. To the best of our knowledge, ETSEF is the first strategy that combines two pre-training methodologies (Transfer Learning and Self-supervised Learning) with ensemble learning approaches. Various data enhancement techniques, including data augmentation, feature fusion, feature selection, and decision fusion, have also been deployed to maximise the efficiency and robustness of the ETSEF model. Five independent medical imaging tasks, including endoscopy, breast cancer, monkeypox, brain tumour, and glaucoma detection, were tested to demonstrate ETSEF's effectiveness and robustness. Facing limited sample numbers and challenging medical tasks, ETSEF has proved its effectiveness by improving diagnostics accuracies from 10\% to 13.3\% when compared to strong ensemble baseline models and up to 14.4\% improvements compared with published state-of-the-art methods. Moreover, we emphasise the robustness and trustworthiness of the ETSEF method through various vision-explainable artificial intelligence techniques, including Grad-CAM, SHAP, and t-SNE. Compared to those large-scale deep learning models, ETSEF can be deployed flexibly and maintain superior performance for challenging medical imaging tasks, showing the potential to be applied to more areas that lack training data
An Experimental Comparison of Transfer Learning against Self-supervised Learning
Jul 08, 2024Recently, transfer learning and self-supervised learning have gained significant attention within the medical field due to their ability to mitigate the challenges posed by limited data availability, improve model generalisation, and reduce computational expenses. Transfer learning and self-supervised learning hold immense potential for advancing medical research. However, it is crucial to recognise that transfer learning and self-supervised learning architectures exhibit distinct advantages and limitations, manifesting variations in accuracy, training speed, and robustness. This paper compares the performance and robustness of transfer learning and self-supervised learning in the medical field. Specifically, we pre-trained two models using the same source domain datasets with different pre-training methods and evaluated them on small-sized medical datasets to identify the factors influencing their final performance. We tested data with several common issues in medical domains, such as data imbalance, data scarcity, and domain mismatch, through comparison experiments to understand their impact on specific pre-trained models. Finally, we provide recommendations to help users apply transfer learning and self-supervised learning methods in medical areas, and build more convenient and efficient deployment strategies.
MedNet: Pre-trained Convolutional Neural Network Model for the Medical Imaging Tasks
Oct 13, 2021
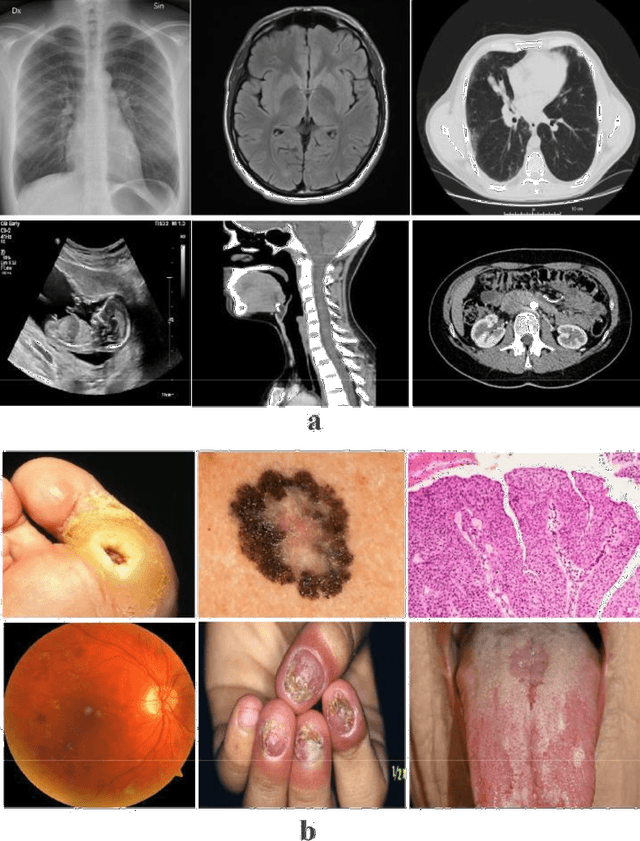
Deep Learning (DL) requires a large amount of training data to provide quality outcomes. However, the field of medical imaging suffers from the lack of sufficient data for properly training DL models because medical images require manual labelling carried out by clinical experts thus the process is time-consuming, expensive, and error-prone. Recently, transfer learning (TL) was introduced to reduce the need for the annotation procedure by means of transferring the knowledge performed by a previous task and then fine-tuning the result using a relatively small dataset. Nowadays, multiple classification methods from medical imaging make use of TL from general-purpose pre-trained models, e.g., ImageNet, which has been proven to be ineffective due to the mismatch between the features learned from natural images (ImageNet) and those more specific from medical images especially medical gray images such as X-rays. ImageNet does not have grayscale images such as MRI, CT, and X-ray. In this paper, we propose a novel DL model to be used for addressing classification tasks of medical imaging, called MedNet. To do so, we aim to issue two versions of MedNet. The first one is Gray-MedNet which will be trained on 3M publicly available gray-scale medical images including MRI, CT, X-ray, ultrasound, and PET. The second version is Color-MedNet which will be trained on 3M publicly available color medical images including histopathology, taken images, and many others. To validate the effectiveness MedNet, both versions will be fine-tuned to train on the target tasks of a more reduced set of medical images. MedNet performs as the pre-trained model to tackle any real-world application from medical imaging and achieve the level of generalization needed for dealing with medical imaging tasks, e.g. classification. MedNet would serve the research community as a baseline for future research.
Aspect-Based Opinion Extraction from Customer reviews
Apr 08, 2014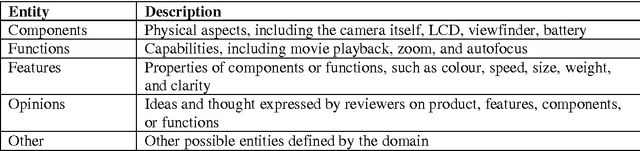
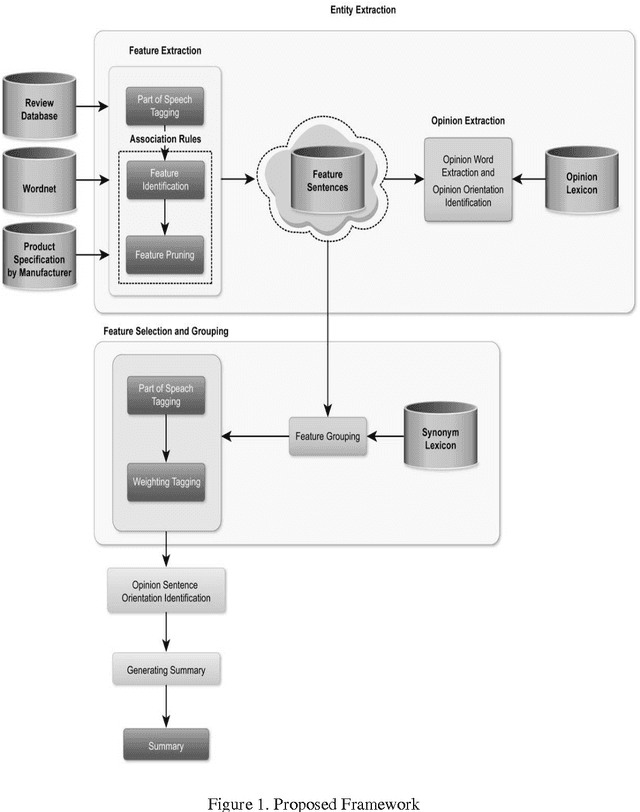

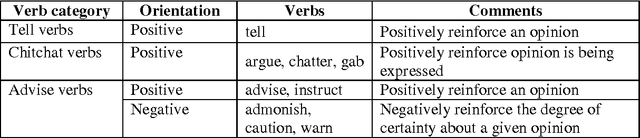
Text is the main method of communicating information in the digital age. Messages, blogs, news articles, reviews, and opinionated information abound on the Internet. People commonly purchase products online and post their opinions about purchased items. This feedback is displayed publicly to assist others with their purchasing decisions, creating the need for a mechanism with which to extract and summarize useful information for enhancing the decision-making process. Our contribution is to improve the accuracy of extraction by combining different techniques from three major areas, named Data Mining, Natural Language Processing techniques and Ontologies. The proposed framework sequentially mines products aspects and users opinions, groups representative aspects by similarity, and generates an output summary. This paper focuses on the task of extracting product aspects and users opinions by extracting all possible aspects and opinions from reviews using natural language, ontology, and frequent (tag) sets. The proposed framework, when compared with an existing baseline model, yielded promising results.