 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Explainable Framework to Address Data Scarcity in Diagnostic Imaging
Jul 09, 2024Deep learning has significantly advanced automatic medical diagnostics and released the occupation of human resources to reduce clinical pressure, yet the persistent challenge of data scarcity in this area hampers its further improvements and applications. To address this gap, we introduce a novel ensemble framework called `Efficient Transfer and Self-supervised Learning based Ensemble Framework' (ETSEF). ETSEF leverages features from multiple pre-trained deep learning models to efficiently learn powerful representations from a limited number of data samples. To the best of our knowledge, ETSEF is the first strategy that combines two pre-training methodologies (Transfer Learning and Self-supervised Learning) with ensemble learning approaches. Various data enhancement techniques, including data augmentation, feature fusion, feature selection, and decision fusion, have also been deployed to maximise the efficiency and robustness of the ETSEF model. Five independent medical imaging tasks, including endoscopy, breast cancer, monkeypox, brain tumour, and glaucoma detection, were tested to demonstrate ETSEF's effectiveness and robustness. Facing limited sample numbers and challenging medical tasks, ETSEF has proved its effectiveness by improving diagnostics accuracies from 10\% to 13.3\% when compared to strong ensemble baseline models and up to 14.4\% improvements compared with published state-of-the-art methods. Moreover, we emphasise the robustness and trustworthiness of the ETSEF method through various vision-explainable artificial intelligence techniques, including Grad-CAM, SHAP, and t-SNE. Compared to those large-scale deep learning models, ETSEF can be deployed flexibly and maintain superior performance for challenging medical imaging tasks, showing the potential to be applied to more areas that lack training data
An Experimental Comparison of Transfer Learning against Self-supervised Learning
Jul 08, 2024Recently, transfer learning and self-supervised learning have gained significant attention within the medical field due to their ability to mitigate the challenges posed by limited data availability, improve model generalisation, and reduce computational expenses. Transfer learning and self-supervised learning hold immense potential for advancing medical research. However, it is crucial to recognise that transfer learning and self-supervised learning architectures exhibit distinct advantages and limitations, manifesting variations in accuracy, training speed, and robustness. This paper compares the performance and robustness of transfer learning and self-supervised learning in the medical field. Specifically, we pre-trained two models using the same source domain datasets with different pre-training methods and evaluated them on small-sized medical datasets to identify the factors influencing their final performance. We tested data with several common issues in medical domains, such as data imbalance, data scarcity, and domain mismatch, through comparison experiments to understand their impact on specific pre-trained models. Finally, we provide recommendations to help users apply transfer learning and self-supervised learning methods in medical areas, and build more convenient and efficient deployment strategies.
Physics-guided deep learning for data scarcity
Nov 24, 2022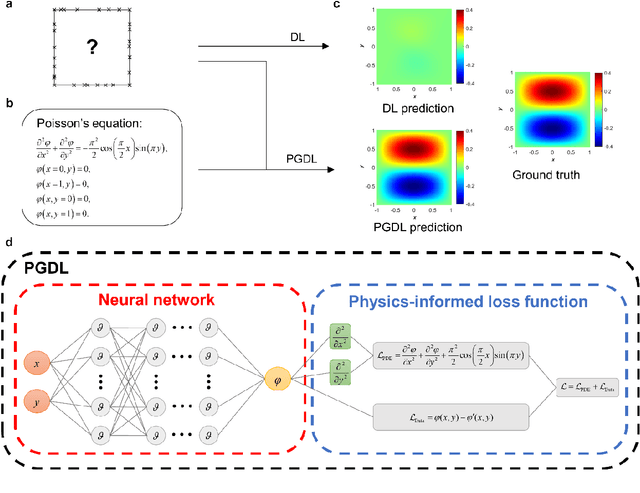
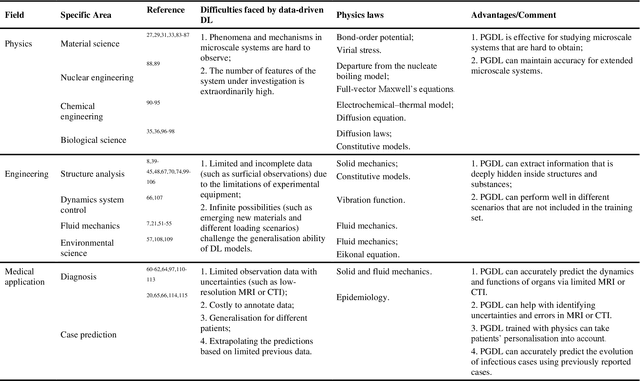
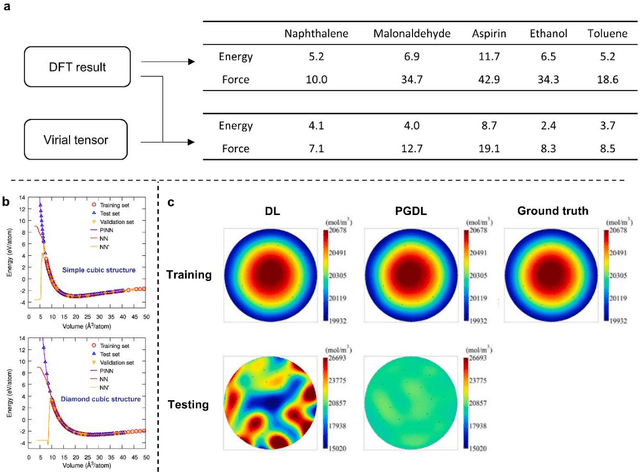
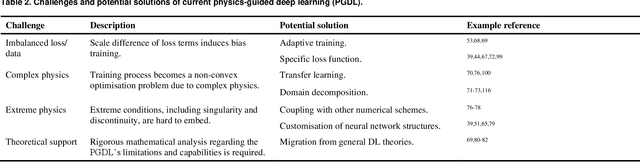
Data are the core of deep learning (DL), and the quality of data significantly affects the performance of DL models. However, high-quality and well-annotated databases are hard or even impossible to acquire for use in many applications, such as structural risk estimation and medical diagnosis, which is an essential barrier that blocks the applications of DL in real life. Physics-guided deep learning (PGDL) is a novel type of DL that can integrate physics laws to train neural networks. It can be used for any systems that are controlled or governed by physics laws, such as mechanics, finance and medical applications. It has been shown that, with the additional information provided by physics laws, PGDL achieves great accuracy and generalisation when facing data scarcity. In this review, the details of PGDL are elucidated, and a structured overview of PGDL with respect to data scarcity in various applications is presented, including physics, engineering and medical applications. Moreover, the limitations and opportunities for current PGDL in terms of data scarcity are identified, and the future outlook for PGDL is discussed in depth.