 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaveSAM Segment Anything for Pavement Distress
Sep 11, 2024
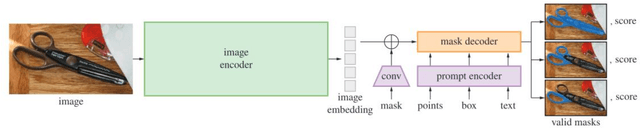

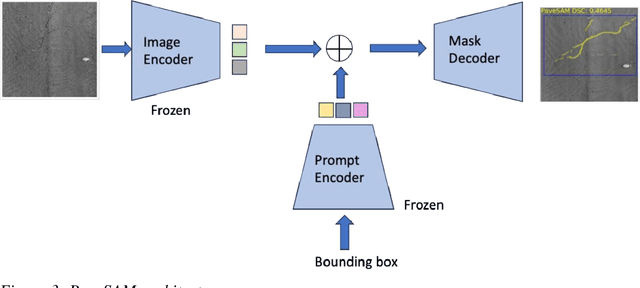
Automated pavement monitoring using computer vision can analyze pavement conditions more efficiently and accurately than manual methods. Accurate segmentation is essential for quantifying the severity and extent of pavement defects and consequently, the overall condition index used for prioritizing rehabilitation and maintenance activities. Deep learning-based segmentation models are however, often supervised and require pixel-level annotations, which can be costly and time-consuming. While the recent evolution of zero-shot segmentation models can generate pixel-wise labels for unseen classes without any training data, they struggle with irregularities of cracks and textured pavement backgrounds. This research proposes a zero-shot segmentation model, PaveSAM, that can segment pavement distresses using bounding box prompts. By retraining SAM's mask decoder with just 180 images, pavement distress segmentation is revolutionized, enabling efficient distress segmentation using bounding box prompts, a capability not found in current segmentation models. This not only drastically reduces labeling efforts and costs but also showcases our model's high performance with minimal input, establishing the pioneering use of SAM in pavement distress segmentation. Furthermore, researchers can use existing open-source pavement distress images annotated with bounding boxes to create segmentation masks, which increases the availability and diversity of segmentation pavement distress datasets.
Application of 2D Homography for High Resolution Traffic Data Collection using CCTV Cameras
Jan 14, 2024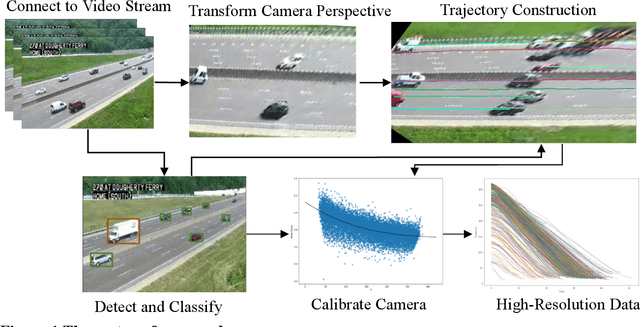
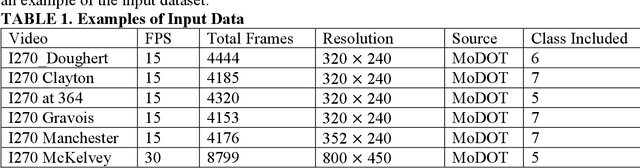
Traffic cameras remain the primary source data for surveillance activities such as congestion and incident monitoring. To date, State agencies continue to rely on manual effort to extract data from networked cameras due to limitations of the current automatic vision systems including requirements for complex camera calibration and inability to generate high resolution data. This study implements a three-stage video analytics framework for extracting high-resolution traffic data such vehicle counts, speed, and acceleration from infrastructure-mounted CCTV cameras. The key components of the framework include object recognition, perspective transformation, and vehicle trajectory reconstruction for traffic data collection. First, a state-of-the-art vehicle recognition model is implemented to detect and classify vehicles. Next, to correct for camera distortion and reduce partial occlusion, an algorithm inspired by two-point linear perspective is utilized to extracts the region of interest (ROI) automatically, while a 2D homography technique transforms the CCTV view to bird's-eye view (BEV). Cameras are calibrated with a two-layer matrix system to enable the extraction of speed and acceleration by converting image coordinates to real-world measurements. Individual vehicle trajectories are constructed and compared in BEV using two time-space-feature-based object trackers, namely Motpy and BYTETrack. The results of the current study showed about +/- 4.5% error rate for directional traffic counts, less than 10% MSE for speed bias between camera estimates in comparison to estimates from probe data sources. Extracting high-resolution data from traffic cameras has several implications, ranging from improvements in traffic management and identify dangerous driving behavior, high-risk areas for accidents, and other safety concerns, enabling proactive measures to reduce accidents and fatalities.
3D Object Detection and High-Resolution Traffic Parameters Extraction Using Low-Resolution LiDAR Data
Jan 13, 2024Traffic volume data collection is a crucial aspect of transportation engineering and urban planning, as it provides vital insights into traffic patterns, congestion, and infrastructure efficiency. Traditional manual methods of traffic data collection are both time-consuming and costly. However, the emergence of modern technologies, particularly Light Detection and Ranging (LiDAR), has revolutionized the process by enabling efficient and accurate data collection. Despite the benefits of using LiDAR for traffic data collection, previous studies have identified two major limitations that have impeded its widespread adoption. These are the need for multiple LiDAR systems to obtain complete point cloud information of objects of interest, as well as the labor-intensive process of annotating 3D bounding boxes for object detection tasks. In response to these challenges, the current study proposes an innovative framework that alleviates the need for multiple LiDAR systems and simplifies the laborious 3D annotation process. To achieve this goal, the study employed a single LiDAR system, that aims at reducing the data acquisition cost and addressed its accompanying limitation of missing point cloud information by developing a Point Cloud Completion (PCC) framework to fill in missing point cloud information using point density. Furthermore, we also used zero-shot learning techniques to detect vehicles and pedestrians, as well as proposed a unique framework for extracting low to high features from the object of interest, such as height, acceleration, and speed. Using the 2D bounding box detection and extracted height information, this study is able to generate 3D bounding boxes automatically without human intervention.
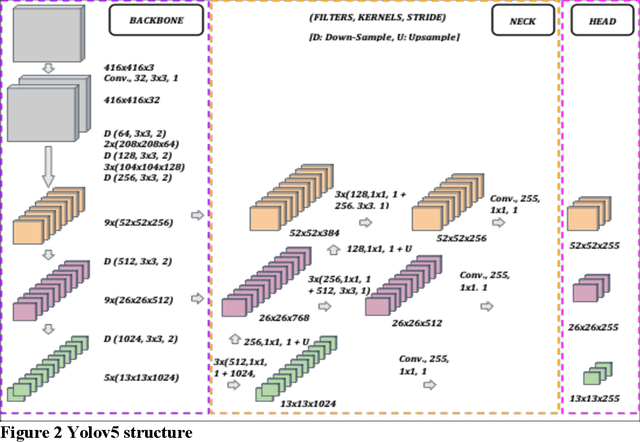
Image2PCI -- A Multitask Learning Framework for Estimating Pavement Condition Indices Directly from Images
Oct 12, 2023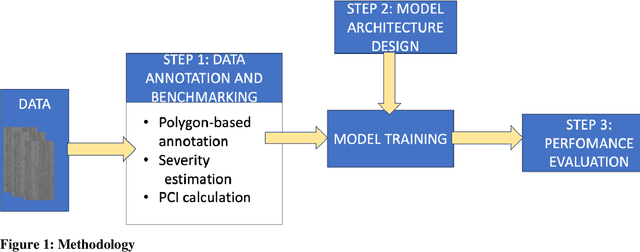
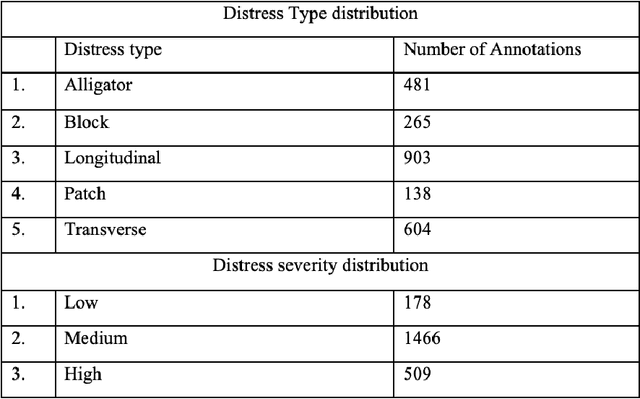

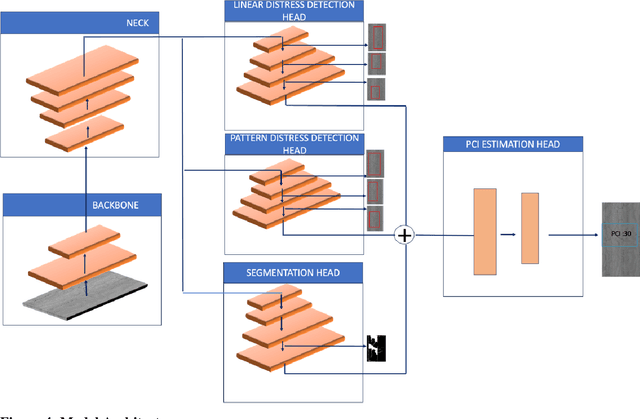
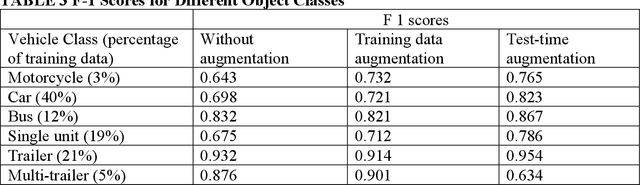
The Pavement Condition Index (PCI) is a widely used metric for evaluating pavement performance based on the type, extent and severity of distresses detected on a pavement surface. In recent times, significant progress has been made in utilizing deep-learning approaches to automate PCI estimation process. However, the current approaches rely on at least two separate models to estimate PCI values -- one model dedicated to determining the type and extent and another for estimating their severity. This approach presents several challenges, including complexities, high computational resource demands, and maintenance burdens that necessitate careful consideration and resolution. To overcome these challenges, the current study develops a unified multi-tasking model that predicts the PCI directly from a top-down pavement image. The proposed architecture is a multi-task model composed of one encoder for feature extraction and four decoders to handle specific tasks: two detection heads, one segmentation head and one PCI estimation head. By multitasking, we are able to extract features from the detection and segmentation heads for automatically estimating the PCI directly from the images. The model performs very well on our benchmarked and open pavement distress dataset that is annotated for multitask learning (the first of its kind). To our best knowledge, this is the first work that can estimate PCI directly from an image at real time speeds while maintaining excellent accuracy on all related tasks for crack detection and segmentation.
Edge Computing-Enabled Road Condition Monitoring: System Development and Evaluation
Oct 09, 2023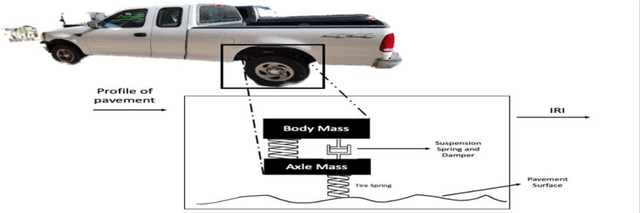
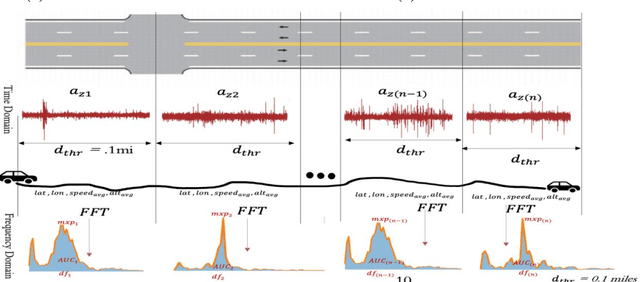
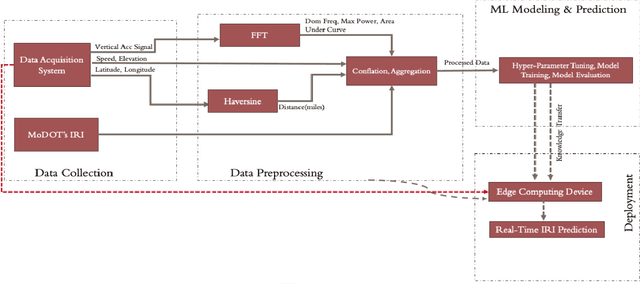
Real-time pavement condition monitoring provides highway agencies with timely and accurate information that could form the basis of pavement maintenance and rehabilitation policies. Existing technologies rely heavily on manual data processing, are expensive and therefore, difficult to scale for frequent, networklevel pavement condition monitoring. Additionally, these systems require sending large packets of data to the cloud which requires large storage space, are computationally expensive to process, and results in high latency. The current study proposes a solution that capitalizes on the widespread availability of affordable Micro Electro-Mechanical System (MEMS) sensors, edge computing and internet connection capabilities of microcontrollers, and deployable machine learning (ML) models to (a) design an Internet of Things (IoT)-enabled device that can be mounted on axles of vehicles to stream live pavement condition data (b) reduce latency through on-device processing and analytics of pavement condition sensor data before sending to the cloud servers. In this study, three ML models including Random Forest, LightGBM and XGBoost were trained to predict International Roughness Index (IRI) at every 0.1-mile segment. XGBoost had the highest accuracy with an RMSE and MAPE of 16.89in/mi and 20.3%, respectively. In terms of the ability to classify the IRI of pavement segments based on ride quality according to MAP-21 criteria, our proposed device achieved an average accuracy of 96.76% on I-70EB and 63.15% on South Providence. Overall, our proposed device demonstrates significant potential in providing real-time pavement condition data to State Highway Agencies (SHA) and Department of Transportation (DOTs) with a satisfactory level of accuracy.
Real-time Multi-Class Helmet Violation Detection Using Few-Shot Data Sampling Technique and YOLOv8
Apr 13, 2023
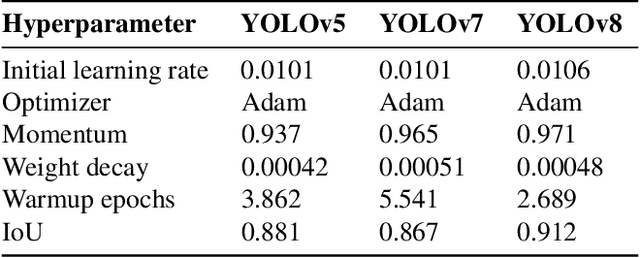

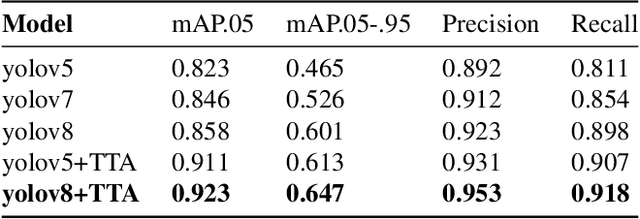
Traffic safety is a major global concern. Helmet usage is a key factor in preventing head injuries and fatalities caused by motorcycle accidents. However, helmet usage violations continue to be a significant problem. To identify such violations, automatic helmet detection systems have been proposed and implemented using computer vision techniques. Real-time implementation of such systems is crucial for traffic surveillance and enforcement, however, most of these systems are not real-time. This study proposes a robust real-time helmet violation detection system. The proposed system utilizes a unique data processing strategy, referred to as few-shot data sampling, to develop a robust model with fewer annotations, and a single-stage object detection model, YOLOv8 (You Only Look Once Version 8), for detecting helmet violations in real-time from video frames. Our proposed method won 7th place in the 2023 AI City Challenge, Track 5, with an mAP score of 0.5861 on experimental validation data. The experimental results demonstrate the effectiveness, efficiency, and robustness of the proposed system.
DeepSegmenter: Temporal Action Localization for Detecting Anomalies in Untrimmed Naturalistic Driving Videos
Apr 13, 2023



Identifying unusual driving behaviors exhibited by drivers during driving is essential for understanding driver behavior and the underlying causes of crashes. Previous studies have primarily approached this problem as a classification task, assuming that naturalistic driving videos come discretized. However, both activity segmentation and classification are required for this task due to the continuous nature of naturalistic driving videos. The current study therefore departs from conventional approaches and introduces a novel methodological framework, DeepSegmenter, that simultaneously performs activity segmentation and classification in a single framework. The proposed framework consists of four major modules namely Data Module, Activity Segmentation Module, Classification Module and Postprocessing Module. Our proposed method won 8th place in the 2023 AI City Challenge, Track 3, with an activity overlap score of 0.5426 on experimental validation data. The experimental results demonstrate the effectiveness, efficiency, and robustness of the proposed system.
AI-Based Framework for Understanding Car Following Behaviors of Drivers in A Naturalistic Driving Environment
Jan 23, 2023



The most common type of accident on the road is a rear-end crash. These crashes have a significant negative impact on traffic flow and are frequently fatal. To gain a more practical understanding of these scenarios, it is necessary to accurately model car following behaviors that result in rear-end crashes. Numerous studies have been carried out to model drivers' car-following behaviors; however, the majority of these studies have relied on simulated data, which may not accurately represent real-world incidents. Furthermore, most studies are restricted to modeling the ego vehicle's acceleration, which is insufficient to explain the behavior of the ego vehicle. As a result, the current study attempts to address these issues by developing an artificial intelligence framework for extracting features relevant to understanding driver behavior in a naturalistic environment. Furthermore, the study modeled the acceleration of both the ego vehicle and the leading vehicle using extracted information from NDS videos. According to the study's findings, young people are more likely to be aggressive drivers than elderly people. In addition, when modeling the ego vehicle's acceleration, it was discovered that the relative velocity between the ego vehicle and the leading vehicle was more important than the distance between the two vehicles.
GC-GRU-N for Traffic Prediction using Loop Detector Data
Nov 13, 2022

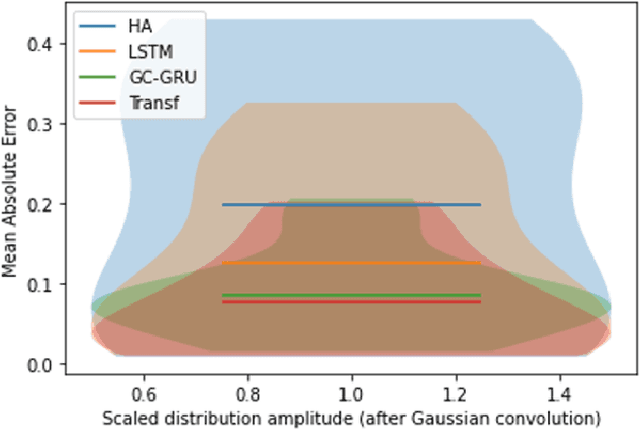
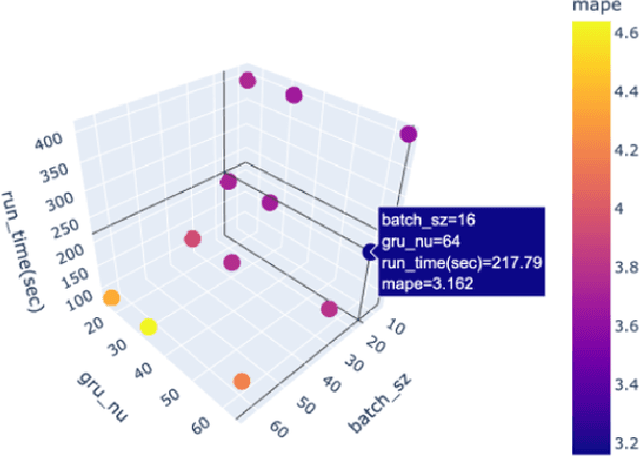
Because traffic characteristics display stochastic nonlinear spatiotemporal dependencies, traffic prediction is a challenging task. In this paper develop a graph convolution gated recurrent unit (GC GRU N) network to extract the essential Spatio temporal features. we use Seattle loop detector data aggregated over 15 minutes and reframe the problem through space and time. The model performance is compared o benchmark models; Historical Average, Long Short Term Memory (LSTM), and Transformers. The proposed model ranked second with the fastest inference time and a very close performance to first place (Transformers). Our model also achieves a running time that is six times faster than transformers. Finally, we present a comparative study of our model and the available benchmarks using metrics such as training time, inference time, MAPE, MAE and RMSE. Spatial and temporal aspects are also analyzed for each of the trained models.
Driver Maneuver Detection and Analysis using Time Series Segmentation and Classification
Nov 10, 2022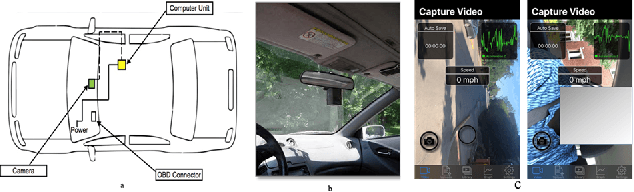

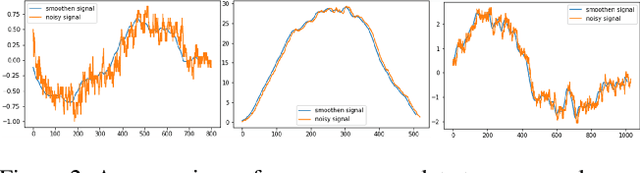

The current paper implements a methodology for automatically detecting vehicle maneuvers from vehicle telemetry data under naturalistic driving settings. Previous approaches have treated vehicle maneuver detection as a classification problem, although both time series segmentation and classification are required since input telemetry data is continuous. Our objective is to develop an end-to-end pipeline for frame-by-frame annotation of naturalistic driving studies videos into various driving events including stop and lane keeping events, lane changes, left-right turning movements, and horizontal curve maneuvers. To address the time series segmentation problem, the study developed an Energy Maximization Algorithm (EMA) capable of extracting driving events of varying durations and frequencies from continuous signal data. To reduce overfitting and false alarm rates, heuristic algorithms were used to classify events with highly variable patterns such as stops and lane-keeping. To classify segmented driving events, four machine learning models were implemented, and their accuracy and transferability were assessed over multiple data sources. The duration of events extracted by EMA were comparable to actual events, with accuracies ranging from 59.30% (left lane change) to 85.60% (lane-keeping). Additionally, the overall accuracy of the 1D-convolutional neural network model was 98.99%, followed by the Long-short-term-memory model at 97.75%, then random forest model at 97.71%, and the support vector machine model at 97.65%. These model accuracies where consistent across different data sources. The study concludes that implementing a segmentation-classification pipeline significantly improves both the accuracy for driver maneuver detection and transferability of shallow and deep ML models across diverse datasets.