 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriver Maneuver Detection and Analysis using Time Series Segmentation and Classification
Nov 10, 2022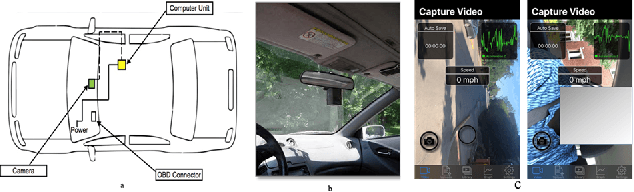

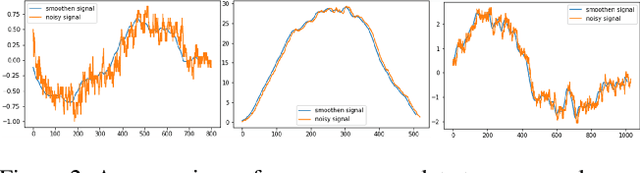

The current paper implements a methodology for automatically detecting vehicle maneuvers from vehicle telemetry data under naturalistic driving settings. Previous approaches have treated vehicle maneuver detection as a classification problem, although both time series segmentation and classification are required since input telemetry data is continuous. Our objective is to develop an end-to-end pipeline for frame-by-frame annotation of naturalistic driving studies videos into various driving events including stop and lane keeping events, lane changes, left-right turning movements, and horizontal curve maneuvers. To address the time series segmentation problem, the study developed an Energy Maximization Algorithm (EMA) capable of extracting driving events of varying durations and frequencies from continuous signal data. To reduce overfitting and false alarm rates, heuristic algorithms were used to classify events with highly variable patterns such as stops and lane-keeping. To classify segmented driving events, four machine learning models were implemented, and their accuracy and transferability were assessed over multiple data sources. The duration of events extracted by EMA were comparable to actual events, with accuracies ranging from 59.30% (left lane change) to 85.60% (lane-keeping). Additionally, the overall accuracy of the 1D-convolutional neural network model was 98.99%, followed by the Long-short-term-memory model at 97.75%, then random forest model at 97.71%, and the support vector machine model at 97.65%. These model accuracies where consistent across different data sources. The study concludes that implementing a segmentation-classification pipeline significantly improves both the accuracy for driver maneuver detection and transferability of shallow and deep ML models across diverse datasets.
Synthetic Distracted Driving (SynDD1) dataset for analyzing distracted behaviors and various gaze zones of a driver
Apr 19, 2022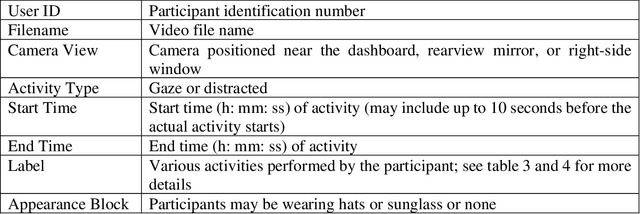



This article presents a synthetic distracted driving (SynDD1) dataset for machine learning models to detect and analyze drivers' various distracted behavior and different gaze zones. We collected the data in a stationary vehicle using three in-vehicle cameras positioned at locations: on the dashboard, near the rearview mirror, and on the top right-side window corner. The dataset contains two activity types: distracted activities, and gaze zones for each participant and each activity type has two sets: without appearance blocks and with appearance blocks such as wearing a hat or sunglasses. The order and duration of each activity for each participant are random. In addition, the dataset contains manual annotations for each activity, having its start and end time annotated. Researchers could use this dataset to evaluate the performance of machine learning algorithms for the classification of various distracting activities and gaze zones of drivers.