 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Crack Foundation Model for Engineering-Reliable Crack Representation and Topology Preservation in Civil Infrastructure
Jun 04, 2026Reliable crack assessment requires not only accurate pixel-level masks but also connected crack geometry and confidence estimates that remain stable under domain shift. However, existing segmentation models can achieve high overlap scores while fragmenting cracks, missing fine branches, and providing no calibrated uncertainty. To address this gap, this paper proposes CrackGeoFM, a multi-task framework that combines a frozen visual foundation backbone with crack-specific adaptation for mask prediction, skeleton reconstruction, and uncertainty estimation. The framework integrates a Frequency-Guided Crack Enhancement Module (FCEM) to enhance high-frequency crack cues, a Crack-Domain Feature Adaptation Module (CFAM) to adapt frozen backbone features to crack-domain patterns, and a Structure-Aware Multi-Task Decoder (SMTD) to jointly decode masks, skeletons, and uncertainty. Across 20 crack datasets, CrackGeoFM achieves state-of-the-art segmentation, improved topology preservation, calibrated uncertainty, and effective few-shot adaptation with only five labeled images. These results support reliable, generalizable, and engineering-oriented crack analysis for infrastructure assessment.
A Road-Conditioned Traffic Movie Prediction Network with Spatiotemporal and Structure-Consistent Learning
May 27, 2026City-wide traffic forecasting is important for congestion management, route guidance, and intelligent transportation systems, but accurate prediction remains challenging when future traffic must be generated as spatial maps over an entire urban network. Existing traffic movie prediction methods have improved frame-level accuracy, yet many still treat forecasting mainly as image reconstruction. This can produce traffic maps that are numerically close to the ground truth but weakly constrained by road layout, connectivity, travel direction, and congestion propagation, especially in cross-city settings where both traffic behavior and road structure change. To address this limitation, this study proposes RCSNet, a road-conditioned spatiotemporal network that reformulates traffic movie prediction as topology-guided future-state generation. RCSNet extracts road-aware representations from static road maps, models multi-horizon traffic dynamics from historical observations, aligns directional traffic features with local road structure, and progressively generates future traffic maps for improved temporal consistency. A structure-consistent learning objective further encourages predictions to remain accurate, road-aligned, and spatially stable. Experiments across multiple cities show that RCSNet improves both forecasting accuracy and structural consistency. In same-city forecasting on Berlin, Antwerp, and Moscow, RCSNet reduces average MAE, MSE, and RMSE by 11.5%, 10.0%, and 5.1%, respectively, compared with the closest baseline. In cross-city testing on unseen Chicago and Bangkok, it reduces RMSE by 10.6% and 10.5% without target-city fine-tuning. Additional horizon-wise, road-structure, explainability, statistical, and efficiency analyses show that RCSNet produces more accurate, transferable, road-aligned, and computationally efficient traffic forecasts.
Hybrid Congestion Classification Framework Using Flow-Guided Attention and Empirical Mode Decomposition
May 06, 2026Accurate traffic congestion classification requires models that jointly capture roadway scene context and non-stationary traffic motion, yet most prior work treats these requirements in isolation. Vision-based methods often depend on appearance cues with standard temporal pooling, which can bias predictions toward static infrastructure, whereas signal-based approaches characterize temporal dynamics but lack the spatial context needed for scene-level localization. These complementary limitations motivate a unified framework that links motion evidence to spatial feature selection while preserving data-adaptive temporal characterization. This study therefore proposes FLO-EMD, a hybrid approach that couples motion-guided attention with empirical, data-driven temporal decomposition. Dense optical flow guides channel and spatial attention so that RGB features are refined toward motion-relevant regions. In parallel, aggregated flow statistics form compact motion traces that are decomposed using Empirical Mode Decomposition (EMD) to extract intrinsic temporal components. The resulting EMD embedding is fused with learned spatiotemporal representations to classify light, medium, and heavy congestion. Experiments on 1,050 five-second clips from four surveillance networks show that FLO-EMD achieves 97.5% overall test accuracy (weighted F1 = 0.9742), outperforming established baselines and remaining robust across diverse environmental conditions; ablation and sensitivity analyses further quantify the contributions of EMD, the number of intrinsic mode functions, and the selected motion descriptors.
Class-Adaptive Cooperative Perception for Multi-Class LiDAR-based 3D Object Detection in V2X Systems
Apr 11, 2026Cooperative perception allows connected vehicles and roadside infrastructure to share sensor observations, creating a fused scene representation beyond the capability of any single platform. However, most cooperative 3D object detectors use a uniform fusion strategy for all object classes, which limits their ability to handle the different geometric structures and point-sampling patterns of small and large objects. This problem is further reinforced by narrow evaluation protocols that often emphasize a single dominant class or only a few cooperation settings, leaving robust multi-class detection across diverse vehicle-to-everything interactions insufficiently explored. To address this gap, we propose a class-adaptive cooperative perception architecture for multi-class 3D object detection from LiDAR data. The model integrates four components: multi-scale window attention with learned scale routing for spatially adaptive feature extraction, a class-specific fusion module that separates small and large objects into attentive fusion pathways, bird's-eye-view enhancement through parallel dilated convolution and channel recalibration for richer contextual representation, and class-balanced objective weighting to reduce bias toward frequent categories. Experiments on the V2X-Real benchmark cover vehicle-centric, infrastructure-centric, vehicle-to-vehicle, infrastructure-to-infrastructure, and vehicle-to-infrastructure settings under identical backbone and training configurations. The proposed method consistently improves mean detection performance over strong intermediate-fusion baselines, with the largest gains on trucks, clear improvements on pedestrians, and competitive results on cars. These results show that aligning feature extraction and fusion with class-dependent geometry and point density leads to more balanced cooperative perception in realistic vehicle-to-everything deployments.
Vision-Language Foundation Models for Comprehensive Automated Pavement Condition Assessment
Apr 09, 2026General-purpose vision-language models demonstrate strong performance in everyday domains but struggle with specialized technical fields requiring precise terminology, structured reasoning, and adherence to engineering standards. This work addresses whether domain-specific instruction tuning can enable comprehensive pavement condition assessment through vision-language models. PaveInstruct, a dataset containing 278,889 image-instruction-response pairs spanning 32 task types, was created by unifying annotations from nine heterogeneous pavement datasets. PaveGPT, a pavement foundation model trained on this dataset, was evaluated against state-of-the-art vision-language models across perception, understanding, and reasoning tasks. Instruction tuning transformed model capabilities, achieving improvements exceeding 20% in spatial grounding, reasoning, and generation tasks while producing ASTM D6433-compliant outputs. These results enable transportation agencies to deploy unified conversational assessment tools that replace multiple specialized systems, simplifying workflows and reducing technical expertise requirements. The approach establishes a pathway for developing instruction-driven AI systems across infrastructure domains including bridge inspection, railway maintenance, and building condition assessment.
PaveSync: A Unified and Comprehensive Dataset for Pavement Distress Analysis and Classification
Dec 23, 2025



Automated pavement defect detection often struggles to generalize across diverse real-world conditions due to the lack of standardized datasets. Existing datasets differ in annotation styles, distress type definitions, and formats, limiting their integration for unified training. To address this gap, we introduce a comprehensive benchmark dataset that consolidates multiple publicly available sources into a standardized collection of 52747 images from seven countries, with 135277 bounding box annotations covering 13 distinct distress types. The dataset captures broad real-world variation in image quality, resolution, viewing angles, and weather conditions, offering a unique resource for consistent training and evaluation. Its effectiveness was demonstrated through benchmarking with state-of-the-art object detection models including YOLOv8-YOLOv12, Faster R-CNN, and DETR, which achieved competitive performance across diverse scenarios. By standardizing class definitions and annotation formats, this dataset provides the first globally representative benchmark for pavement defect detection and enables fair comparison of models, including zero-shot transfer to new environments.
A Contextual Analysis of Driver-Facing and Dual-View Video Inputs for Distraction Detection in Naturalistic Driving Environments
Dec 23, 2025Despite increasing interest in computer vision-based distracted driving detection, most existing models rely exclusively on driver-facing views and overlook crucial environmental context that influences driving behavior. This study investigates whether incorporating road-facing views alongside driver-facing footage improves distraction detection accuracy in naturalistic driving conditions. Using synchronized dual-camera recordings from real-world driving, we benchmark three leading spatiotemporal action recognition architectures: SlowFast-R50, X3D-M, and SlowOnly-R50. Each model is evaluated under two input configurations: driver-only and stacked dual-view. Results show that while contextual inputs can improve detection in certain models, performance gains depend strongly on the underlying architecture. The single-pathway SlowOnly model achieved a 9.8 percent improvement with dual-view inputs, while the dual-pathway SlowFast model experienced a 7.2 percent drop in accuracy due to representational conflicts. These findings suggest that simply adding visual context is not sufficient and may lead to interference unless the architecture is specifically designed to support multi-view integration. This study presents one of the first systematic comparisons of single- and dual-view distraction detection models using naturalistic driving data and underscores the importance of fusion-aware design for future multimodal driver monitoring systems.
Demographics-Informed Neural Network for Multi-Modal Spatiotemporal forecasting of Urban Growth and Travel Patterns Using Satellite Imagery
Jun 14, 2025This study presents a novel demographics informed deep learning framework designed to forecast urban spatial transformations by jointly modeling geographic satellite imagery, socio-demographics, and travel behavior dynamics. The proposed model employs an encoder-decoder architecture with temporal gated residual connections, integrating satellite imagery and demographic data to accurately forecast future spatial transformations. The study also introduces a demographics prediction component which ensures that predicted satellite imagery are consistent with demographic features, significantly enhancing physiological realism and socioeconomic accuracy. The framework is enhanced by a proposed multi-objective loss function complemented by a semantic loss function that balances visual realism with temporal coherence. The experimental results from this study demonstrate the superior performance of the proposed model compared to state-of-the-art models, achieving higher structural similarity (SSIM: 0.8342) and significantly improved demographic consistency (Demo-loss: 0.14 versus 0.95 and 0.96 for baseline models). Additionally, the study validates co-evolutionary theories of urban development, demonstrating quantifiable bidirectional influences between built environment characteristics and population patterns. The study also contributes a comprehensive multimodal dataset pairing satellite imagery sequences (2012-2023) with corresponding demographic and travel behavior attributes, addressing existing gaps in urban and transportation planning resources by explicitly connecting physical landscape evolution with socio-demographic patterns.
Visual Dominance and Emerging Multimodal Approaches in Distracted Driving Detection: A Review of Machine Learning Techniques
May 04, 2025
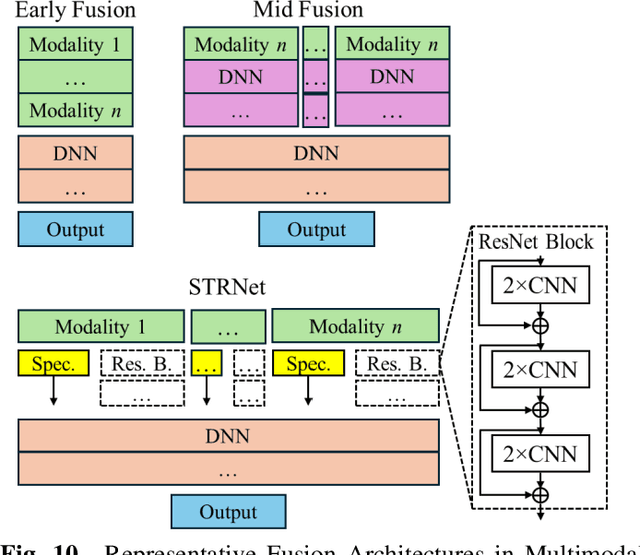


Distracted driving continues to be a significant cause of road traffic injuries and fatalities worldwide, even with advancements in driver monitoring technologies. Recent developments in machine learning (ML) and deep learning (DL) have primarily focused on visual data to detect distraction, often neglecting the complex, multimodal nature of driver behavior. This systematic review assesses 74 peer-reviewed studies from 2019 to 2024 that utilize ML/DL techniques for distracted driving detection across visual, sensor-based, multimodal, and emerging modalities. The review highlights a significant prevalence of visual-only models, particularly convolutional neural networks (CNNs) and temporal architectures, which achieve high accuracy but show limited generalizability in real-world scenarios. Sensor-based and physiological models provide complementary strengths by capturing internal states and vehicle dynamics, while emerging techniques, such as auditory sensing and radio frequency (RF) methods, offer privacy-aware alternatives. Multimodal architecture consistently surpasses unimodal baselines, demonstrating enhanced robustness, context awareness, and scalability by integrating diverse data streams. These findings emphasize the need to move beyond visual-only approaches and adopt multimodal systems that combine visual, physiological, and vehicular cues while keeping in checking the need to balance computational requirements. Future research should focus on developing lightweight, deployable multimodal frameworks, incorporating personalized baselines, and establishing cross-modality benchmarks to ensure real-world reliability in advanced driver assistance systems (ADAS) and road safety interventions.
An Improved ResNet50 Model for Predicting Pavement Condition Index (PCI) Directly from Pavement Images
Apr 25, 2025Accurately predicting the Pavement Condition Index (PCI), a measure of roadway conditions, from pavement images is crucial for infrastructure maintenance. This study proposes an enhanced version of the Residual Network (ResNet50) architecture, integrated with a Convolutional Block Attention Module (CBAM), to predict PCI directly from pavement images without additional annotations. By incorporating CBAM, the model autonomously prioritizes critical features within the images, improving prediction accuracy. Compared to the original baseline ResNet50 and DenseNet161 architectures, the enhanced ResNet50-CBAM model achieved a significantly lower mean absolute percentage error (MAPE) of 58.16%, compared to the baseline models that achieved 70.76% and 65.48% respectively. These results highlight the potential of using attention mechanisms to refine feature extraction, ultimately enabling more accurate and efficient assessments of pavement conditions. This study emphasizes the importance of targeted feature refinement in advancing automated pavement analysis through attention mechanisms.