 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaveSAM Segment Anything for Pavement Distress
Paper and Code
Sep 11, 2024
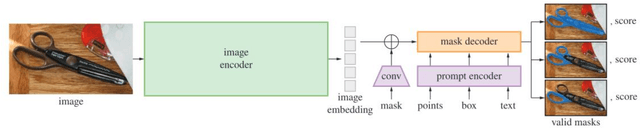

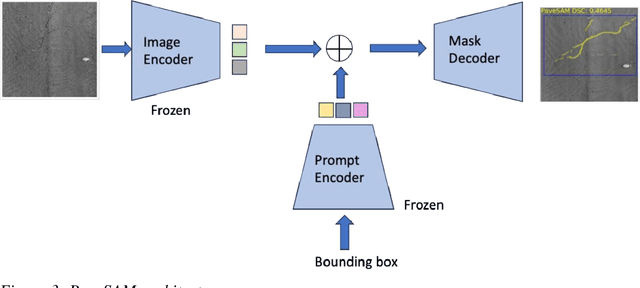
Automated pavement monitoring using computer vision can analyze pavement conditions more efficiently and accurately than manual methods. Accurate segmentation is essential for quantifying the severity and extent of pavement defects and consequently, the overall condition index used for prioritizing rehabilitation and maintenance activities. Deep learning-based segmentation models are however, often supervised and require pixel-level annotations, which can be costly and time-consuming. While the recent evolution of zero-shot segmentation models can generate pixel-wise labels for unseen classes without any training data, they struggle with irregularities of cracks and textured pavement backgrounds. This research proposes a zero-shot segmentation model, PaveSAM, that can segment pavement distresses using bounding box prompts. By retraining SAM's mask decoder with just 180 images, pavement distress segmentation is revolutionized, enabling efficient distress segmentation using bounding box prompts, a capability not found in current segmentation models. This not only drastically reduces labeling efforts and costs but also showcases our model's high performance with minimal input, establishing the pioneering use of SAM in pavement distress segmentation. Furthermore, researchers can use existing open-source pavement distress images annotated with bounding boxes to create segmentation masks, which increases the availability and diversity of segmentation pavement distress datasets.