 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMCAformer: Macro-Micro Cross-Attention Transformer for Traffic Speed Prediction with Microscopic Connected Vehicle Driving Behavior
Feb 17, 2026Accurate speed prediction is crucial for proactive traffic management to enhance traffic efficiency and safety. Existing studies have primarily relied on aggregated, macroscopic traffic flow data to predict future traffic trends, whereas road traffic dynamics are also influenced by individual, microscopic human driving behaviors. Recent Connected Vehicle (CV) data provide rich driving behavior features, offering new opportunities to incorporate these behavioral insights into speed prediction. To this end, we propose the Macro-Micro Cross-Attention Transformer (MMCAformer) to integrate CV data-based micro driving behavior features with macro traffic features for speed prediction. Specifically, MMCAformer employs self-attention to learn intrinsic dependencies in macro traffic flow and cross-attention to capture spatiotemporal interplays between macro traffic status and micro driving behavior. MMCAformer is optimized with a Student-t negative log-likelihood loss to provide point-wise speed prediction and estimate uncertainty. Experiments on four Florida freeways demonstrate the superior performance of the proposed MMCAformer compared to baselines. Compared with only using macro features, introducing micro driving behavior features not only enhances prediction accuracy (e.g., overall RMSE, MAE, and MAPE reduced by 9.0%, 6.9%, and 10.2%, respectively) but also shrinks model prediction uncertainty (e.g., mean predictive intervals decreased by 10.1-24.0% across the four freeways). Results reveal that hard braking and acceleration frequencies emerge as the most influential features. Such improvements are more pronounced under congested, low-speed traffic conditions.
Real-time Secondary Crash Likelihood Prediction Excluding Post Primary Crash Features
Feb 17, 2026Secondary crash likelihood prediction is a critical component of an active traffic management system to mitigate congestion and adverse impacts caused by secondary crashes. However, existing approaches mainly rely on post-crash features (e.g., crash type and severity) that are rarely available in real time, limiting their practical applicability. To address this limitation, we propose a hybrid secondary crash likelihood prediction framework that does not depend on post-crash features. A dynamic spatiotemporal window is designed to extract real-time traffic flow and environmental features from primary crash locations and their upstream segments. The framework includes three models: a primary crash model to estimate the likelihood of secondary crash occurrence, and two secondary crash models to evaluate traffic conditions at crash and upstream segments under different comparative scenarios. An ensemble learning strategy integrating six machine learning algorithms is developed to enhance predictive performance, and a voting-based mechanism combines the outputs of the three models. Experiments on Florida freeways demonstrate that the proposed hybrid framework correctly identifies 91% of secondary crashes with a low false alarm rate of 0.20. The Area Under the ROC Curve improves from 0.654, 0.744, and 0.902 for the individual models to 0.952 for the hybrid model, outperforming previous studies.
An Integrated Causal Inference Framework for Traffic Safety Modeling with Semantic Street-View Visual Features
Feb 12, 2026Macroscopic traffic safety modeling aims to identify critical risk factors for regional crashes, thereby informing targeted policy interventions for safety improvement. However, current approaches rely heavily on static sociodemographic and infrastructure metrics, frequently overlooking the impacts from drivers' visual perception of driving environment. Although visual environment features have been found to impact driving and traffic crashes, existing evidence remains largely observational, failing to establish the robust causality for traffic policy evaluation under complex spatial environment. To fill these gaps, we applied semantic segmentation on Google Street View imageries to extract visual environmental features and proposed a Double Machine Learning framework to quantify their causal effects on regional crashes. Meanwhile, we utilized SHAP values to characterize the nonlinear influence mechanisms of confounding variables in the models and applied causal forests to estimate conditional average treatment effects. Leveraging crash records from the Miami metropolitan area, Florida, and 220,000 street view images, evidence shows that greenery proportion exerts a significant and robust negative causal effect on traffic crashes (Average Treatment Effect = -6.38, p = 0.005). This protective effect exhibits spatial heterogeneity, being most pronounced in densely populated and socially vulnerable urban cores. While greenery significantly mitigates angle and rear-end crashes, its protective benefit for vulnerable road users (VRUs) remains limited. Our findings provide causal evidence for greening as a potential safety intervention, prioritizing hazardous visual environments while highlighting the need for distinct design optimizations to protect VRUs.
SAVeD: A First-Person Social Media Video Dataset for ADAS-equipped vehicle Near-Miss and Crash Event Analyses
Dec 19, 2025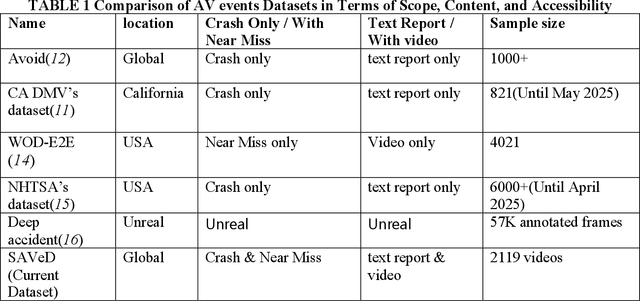
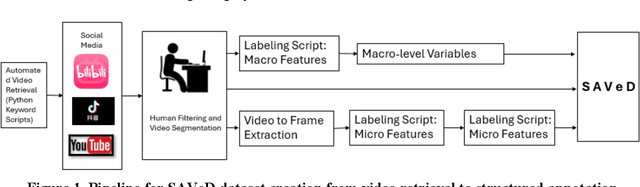
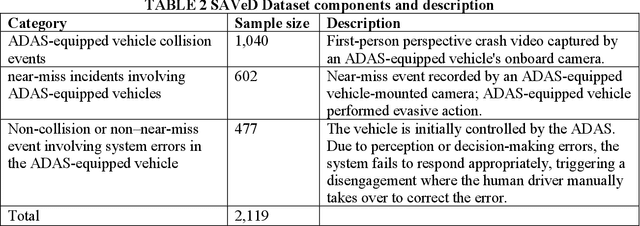
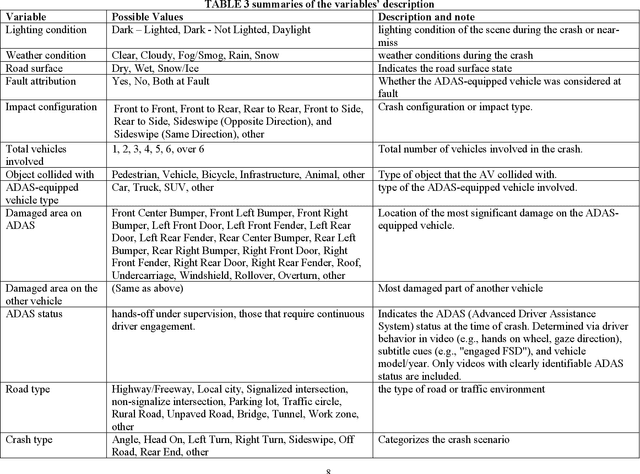
The advancement of safety-critical research in driving behavior in ADAS-equipped vehicles require real-world datasets that not only include diverse traffic scenarios but also capture high-risk edge cases such as near-miss events and system failures. However, existing datasets are largely limited to either simulated environments or human-driven vehicle data, lacking authentic ADAS (Advanced Driver Assistance System) vehicle behavior under risk conditions. To address this gap, this paper introduces SAVeD, a large-scale video dataset curated from publicly available social media content, explicitly focused on ADAS vehicle-related crashes, near-miss incidents, and disengagements. SAVeD features 2,119 first-person videos, capturing ADAS vehicle operations in diverse locations, lighting conditions, and weather scenarios. The dataset includes video frame-level annotations for collisions, evasive maneuvers, and disengagements, enabling analysis of both perception and decision-making failures. We demonstrate SAVeD's utility through multiple analyses and contributions: (1) We propose a novel framework integrating semantic segmentation and monocular depth estimation to compute real-time Time-to-Collision (TTC) for dynamic objects. (2) We utilize the Generalized Extreme Value (GEV) distribution to model and quantify the extreme risk in crash and near-miss events across different roadway types. (3) We establish benchmarks for state-of-the-art VLLMs (VideoLLaMA2 and InternVL2.5 HiCo R16), showing that SAVeD's detailed annotations significantly enhance model performance through domain adaptation in complex near-miss scenarios.
VRU-CIPI: Crossing Intention Prediction at Intersections for Improving Vulnerable Road Users Safety
May 15, 2025Understanding and predicting human behavior in-thewild, particularly at urban intersections, remains crucial for enhancing interaction safety between road users. Among the most critical behaviors are crossing intentions of Vulnerable Road Users (VRUs), where misinterpretation may result in dangerous conflicts with oncoming vehicles. In this work, we propose the VRU-CIPI framework with a sequential attention-based model designed to predict VRU crossing intentions at intersections. VRU-CIPI employs Gated Recurrent Unit (GRU) to capture temporal dynamics in VRU movements, combined with a multi-head Transformer self-attention mechanism to encode contextual and spatial dependencies critical for predicting crossing direction. Evaluated on UCF-VRU dataset, our proposed achieves state-of-the-art performance with an accuracy of 96.45% and achieving real-time inference speed reaching 33 frames per second. Furthermore, by integrating with Infrastructure-to-Vehicles (I2V) communication, our approach can proactively enhance intersection safety through timely activation of crossing signals and providing early warnings to connected vehicles, ensuring smoother and safer interactions for all road users.
Advanced Crash Causation Analysis for Freeway Safety: A Large Language Model Approach to Identifying Key Contributing Factors
May 15, 2025Understanding the factors contributing to traffic crashes and developing strategies to mitigate their severity is essential. Traditional statistical methods and machine learning models often struggle to capture the complex interactions between various factors and the unique characteristics of each crash. This research leverages large language model (LLM) to analyze freeway crash data and provide crash causation analysis accordingly. By compiling 226 traffic safety studies related to freeway crashes, a training dataset encompassing environmental, driver, traffic, and geometric design factors was created. The Llama3 8B model was fine-tuned using QLoRA to enhance its understanding of freeway crashes and their contributing factors, as covered in these studies. The fine-tuned Llama3 8B model was then used to identify crash causation without pre-labeled data through zero-shot classification, providing comprehensive explanations to ensure that the identified causes were reasonable and aligned with existing research. Results demonstrate that LLMs effectively identify primary crash causes such as alcohol-impaired driving, speeding, aggressive driving, and driver inattention. Incorporating event data, such as road maintenance, offers more profound insights. The model's practical applicability and potential to improve traffic safety measures were validated by a high level of agreement among researchers in the field of traffic safety, as reflected in questionnaire results with 88.89%. This research highlights the complex nature of traffic crashes and how LLMs can be used for comprehensive analysis of crash causation and other contributing factors. Moreover, it provides valuable insights and potential countermeasures to aid planners and policymakers in developing more effective and efficient traffic safety practices.
Video-to-Text Pedestrian Monitoring (VTPM): Leveraging Computer Vision and Large Language Models for Privacy-Preserve Pedestrian Activity Monitoring at Intersections
Aug 21, 2024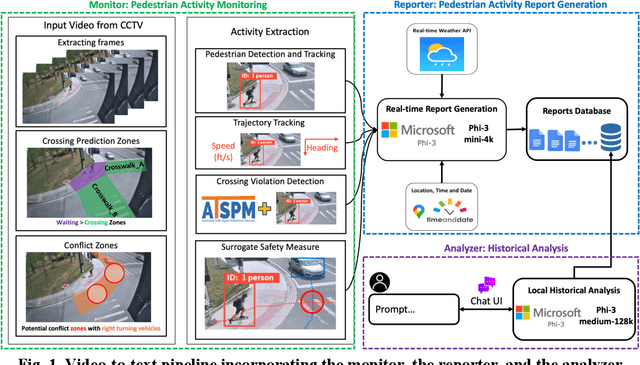
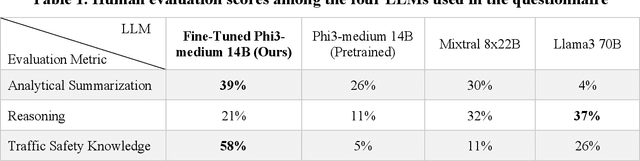
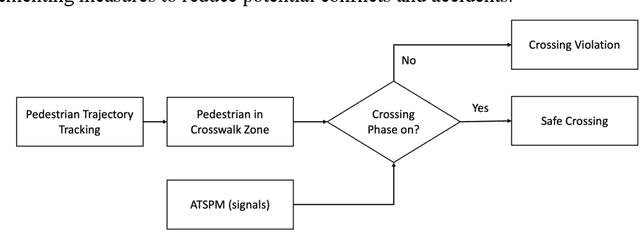
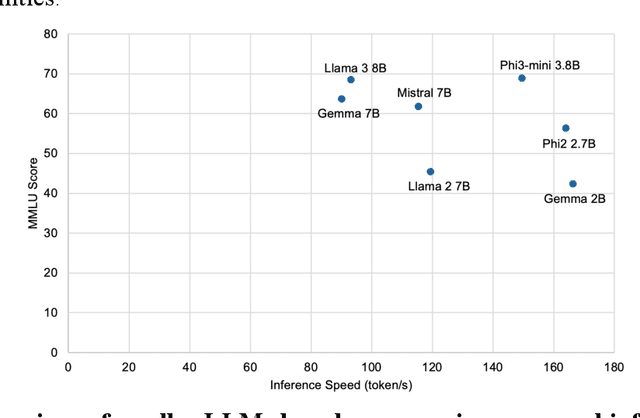
Computer vision has advanced research methodologies, enhancing system services across various fields. It is a core component in traffic monitoring systems for improving road safety; however, these monitoring systems don't preserve the privacy of pedestrians who appear in the videos, potentially revealing their identities. Addressing this issue, our paper introduces Video-to-Text Pedestrian Monitoring (VTPM), which monitors pedestrian movements at intersections and generates real-time textual reports, including traffic signal and weather information. VTPM uses computer vision models for pedestrian detection and tracking, achieving a latency of 0.05 seconds per video frame. Additionally, it detects crossing violations with 90.2% accuracy by incorporating traffic signal data. The proposed framework is equipped with Phi-3 mini-4k to generate real-time textual reports of pedestrian activity while stating safety concerns like crossing violations, conflicts, and the impact of weather on their behavior with latency of 0.33 seconds. To enhance comprehensive analysis of the generated textual reports, Phi-3 medium is fine-tuned for historical analysis of these generated textual reports. This fine-tuning enables more reliable analysis about the pedestrian safety at intersections, effectively detecting patterns and safety critical events. The proposed VTPM offers a more efficient alternative to video footage by using textual reports reducing memory usage, saving up to 253 million percent, eliminating privacy issues, and enabling comprehensive interactive historical analysis.
Enhancing Traffic Safety with Parallel Dense Video Captioning for End-to-End Event Analysis
Apr 12, 2024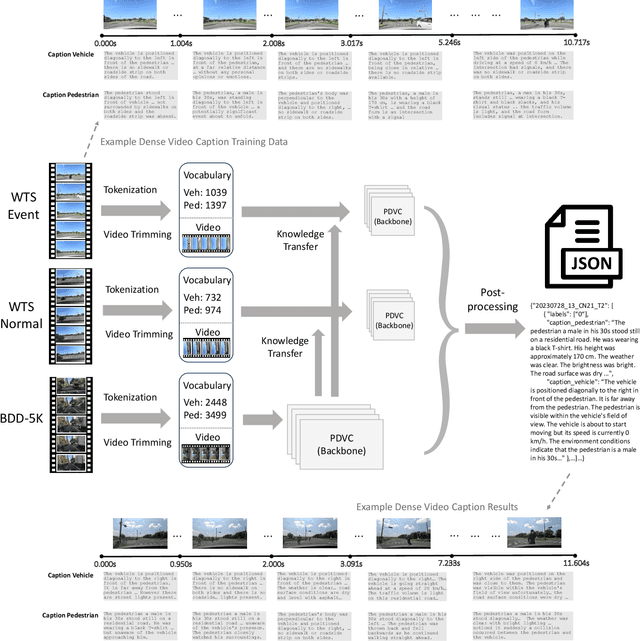


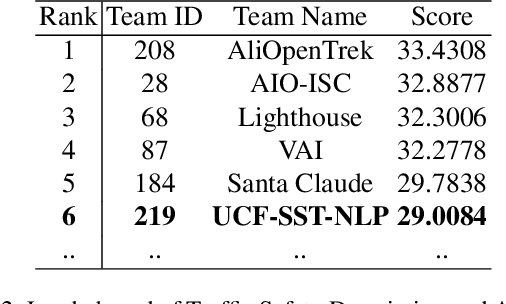
This paper introduces our solution for Track 2 in AI City Challenge 2024. The task aims to solve traffic safety description and analysis with the dataset of Woven Traffic Safety (WTS), a real-world Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding. Our solution mainly focuses on the following points: 1) To solve dense video captioning, we leverage the framework of dense video captioning with parallel decoding (PDVC) to model visual-language sequences and generate dense caption by chapters for video. 2) Our work leverages CLIP to extract visual features to more efficiently perform cross-modality training between visual and textual representations. 3) We conduct domain-specific model adaptation to mitigate domain shift problem that poses recognition challenge in video understanding. 4) Moreover, we leverage BDD-5K captioned videos to conduct knowledge transfer for better understanding WTS videos and more accurate captioning. Our solution has yielded on the test set, achieving 6th place in the competition. The open source code will be available at https://github.com/UCF-SST-Lab/AICity2024CVPRW
Vehicle-group-based Crash Risk Formation and Propagation Analysis for Expressways
Feb 19, 2024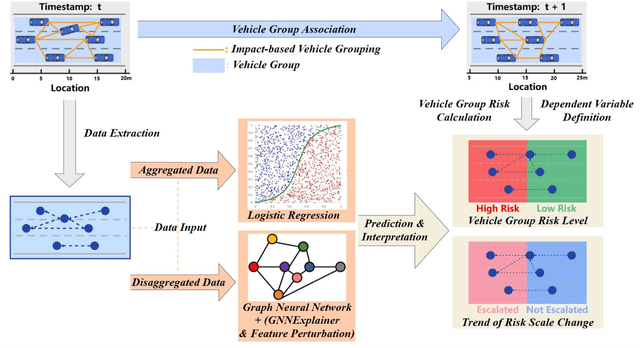
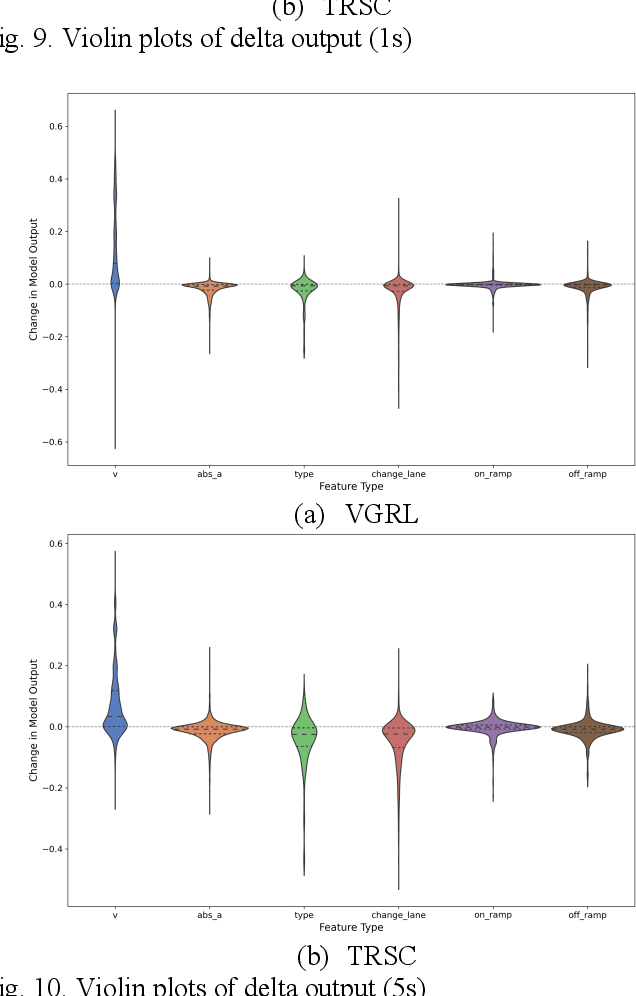
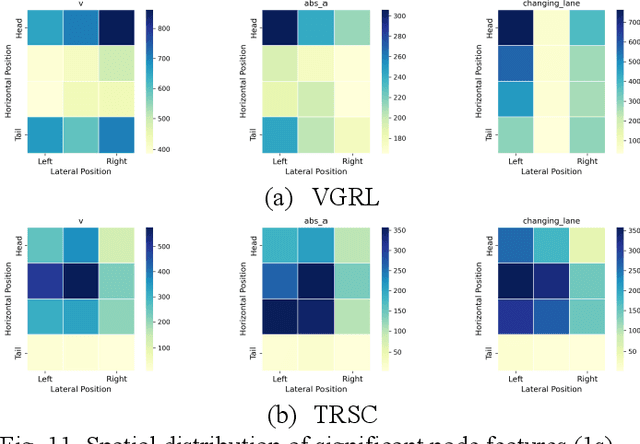
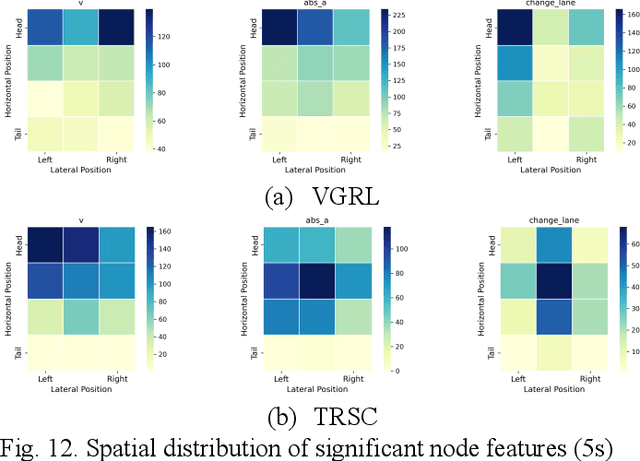
Previous studies in predicting crash risk primarily associated the number or likelihood of crashes on a road segment with traffic parameters or geometric characteristics of the segment, usually neglecting the impact of vehicles' continuous movement and interactions with nearby vehicles. Advancements in communication technologies have empowered driving information collected from surrounding vehicles, enabling the study of group-based crash risks. Based on high-resolution vehicle trajectory data, this research focused on vehicle groups as the subject of analysis and explored risk formation and propagation mechanisms considering features of vehicle groups and road segments. Several key factors contributing to crash risks were identified, including past high-risk vehicle-group states, complex vehicle behaviors, high percentage of large vehicles, frequent lane changes within a vehicle group, and specific road geometries. A multinomial logistic regression model was developed to analyze the spatial risk propagation patterns, which were classified based on the trend of high-risk occurrences within vehicle groups. The results indicated that extended periods of high-risk states, increase in vehicle-group size, and frequent lane changes are associated with adverse risk propagation patterns. Conversely, smoother traffic flow and high initial crash risk values are linked to risk dissipation. Furthermore, the study conducted sensitivity analysis on different types of classifiers, prediction time intervalsss and adaptive TTC thresholds. The highest AUC value for vehicle-group risk prediction surpassed 0.93. The findings provide valuable insights to researchers and practitioners in understanding and prediction of vehicle-group safety, ultimately improving active traffic safety management and operations of Connected and Autonomous Vehicles.
RF-Enhanced Road Infrastructure for Intelligent Transportation
Nov 01, 2023



The EPC GEN 2 communication protocol for Ultra-high frequency Radio Frequency Identification (RFID) has offered a promising avenue for advancing the intelligence of transportation infrastructure. With the capability of linking vehicles to RFID readers to crowdsource information from RFID tags on road infrastructures, the RF-enhanced road infrastructure (REI) can potentially transform data acquisition for urban transportation. Despite its potential, the broader adoption of RFID technologies in building intelligent roads has been limited by a deficiency in understanding how the GEN 2 protocol impacts system performance under different transportation settings. This paper fills this knowledge gap by presenting the system architecture and detailing the design challenges associated with REI. Comprehensive real-world experiments are conducted to assess REI's effectiveness across various urban contexts. The results yield crucial insights into the optimal design of on-vehicle RFID readers and on-road RFID tags, considering the constraints imposed by vehicle dynamics, road geometries, and tag placements. With the optimized designs of encoding schemes for reader-tag communication and on-vehicle antennas, REI is able to fulfill the requirements of traffic sign inventory management and environmental monitoring while falling short of catering to the demand for high-speed navigation. In particular, the Miller 2 encoding scheme strikes the best balance between reading performance (e.g., throughput) and noise tolerance for the multipath effect. Additionally, we show that the on-vehicle antenna should be oriented to maximize the available time for reading on-road tags, although it may reduce the received power by the tags in the forward link.