 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGes3ViG: Incorporating Pointing Gestures into Language-Based 3D Visual Grounding for Embodied Reference Understanding
Apr 13, 20253-Dimensional Embodied Reference Understanding (3D-ERU) combines a language description and an accompanying pointing gesture to identify the most relevant target object in a 3D scene. Although prior work has explored pure language-based 3D grounding, there has been limited exploration of 3D-ERU, which also incorporates human pointing gestures. To address this gap, we introduce a data augmentation framework-Imputer, and use it to curate a new benchmark dataset-ImputeRefer for 3D-ERU, by incorporating human pointing gestures into existing 3D scene datasets that only contain language instructions. We also propose Ges3ViG, a novel model for 3D-ERU that achieves ~30% improvement in accuracy as compared to other 3D-ERU models and ~9% compared to other purely language-based 3D grounding models. Our code and dataset are available at https://github.com/AtharvMane/Ges3ViG.
RF-Enhanced Road Infrastructure for Intelligent Transportation
Nov 01, 2023



The EPC GEN 2 communication protocol for Ultra-high frequency Radio Frequency Identification (RFID) has offered a promising avenue for advancing the intelligence of transportation infrastructure. With the capability of linking vehicles to RFID readers to crowdsource information from RFID tags on road infrastructures, the RF-enhanced road infrastructure (REI) can potentially transform data acquisition for urban transportation. Despite its potential, the broader adoption of RFID technologies in building intelligent roads has been limited by a deficiency in understanding how the GEN 2 protocol impacts system performance under different transportation settings. This paper fills this knowledge gap by presenting the system architecture and detailing the design challenges associated with REI. Comprehensive real-world experiments are conducted to assess REI's effectiveness across various urban contexts. The results yield crucial insights into the optimal design of on-vehicle RFID readers and on-road RFID tags, considering the constraints imposed by vehicle dynamics, road geometries, and tag placements. With the optimized designs of encoding schemes for reader-tag communication and on-vehicle antennas, REI is able to fulfill the requirements of traffic sign inventory management and environmental monitoring while falling short of catering to the demand for high-speed navigation. In particular, the Miller 2 encoding scheme strikes the best balance between reading performance (e.g., throughput) and noise tolerance for the multipath effect. Additionally, we show that the on-vehicle antenna should be oriented to maximize the available time for reading on-road tags, although it may reduce the received power by the tags in the forward link.
Introducing flexible perovskites to the IoT world using photovoltaic-powered wireless tags
Jul 01, 2022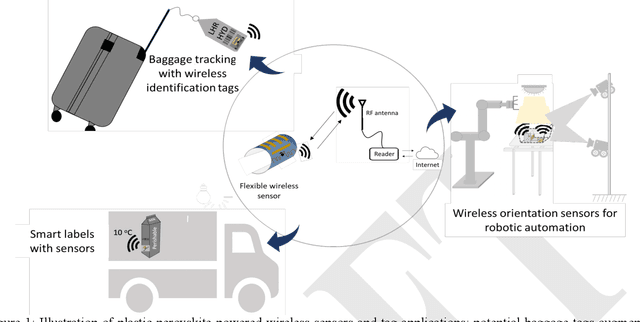
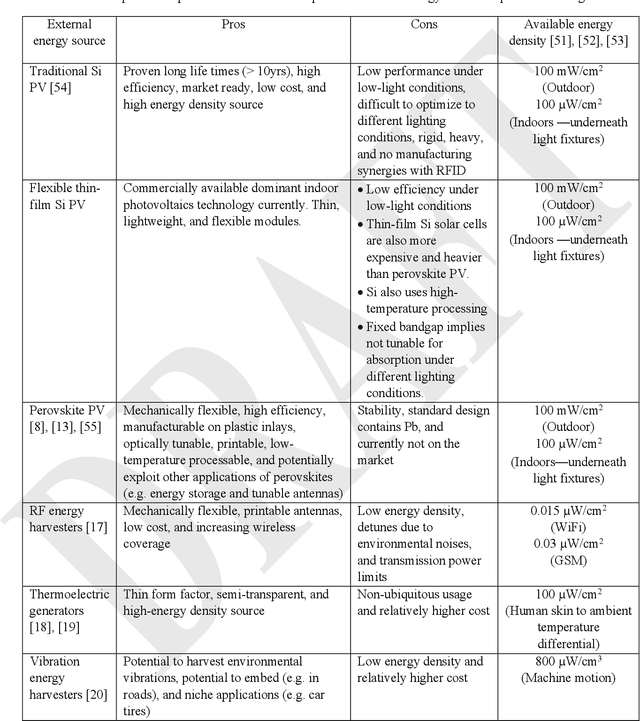
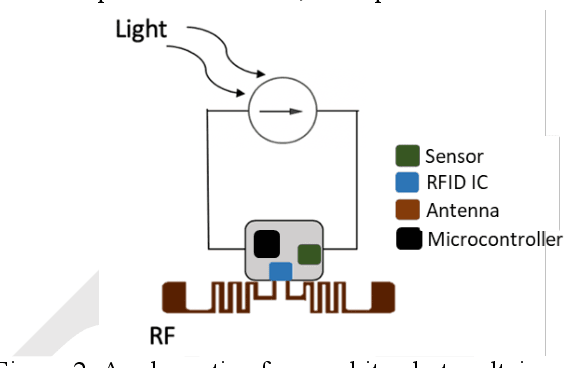
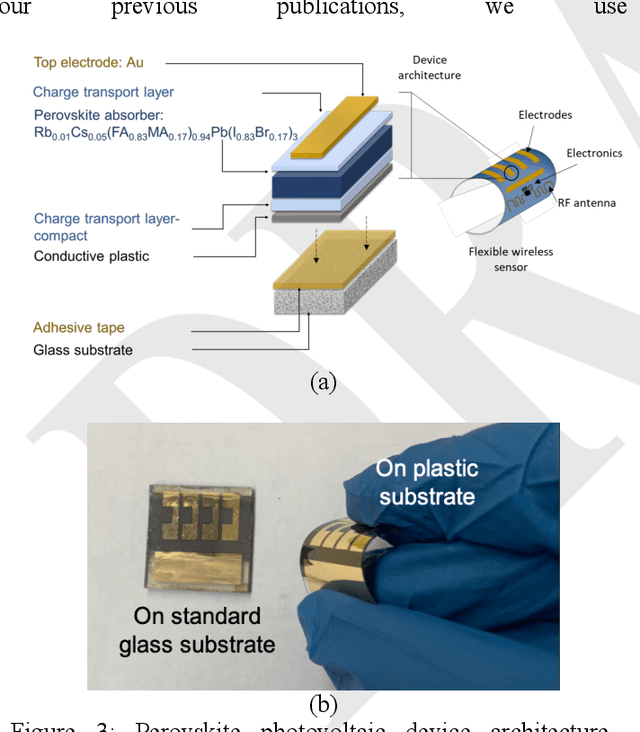
Billions of everyday objects could become part of the Internet of Things (IoT) by augmentation with low-cost, long-range, maintenance-free wireless sensors. Radio Frequency Identification (RFID) is a low-cost wireless technology that could enable this vision, but it is constrained by short communication range and lack of sufficient energy available to power auxiliary electronics and sensors. Here, we explore the use of flexible perovskite photovoltaic cells to provide external power to semi-passive RFID tags to increase range and energy availability for external electronics such as microcontrollers and digital sensors. Perovskites are intriguing materials that hold the possibility to develop high-performance, low-cost, optically tunable (to absorb different light spectra), and flexible light energy harvesters. Our prototype perovskite photovoltaic cells on plastic substrates have an efficiency of 13% and a voltage of 0.88 V at maximum power under standard testing conditions. We built prototypes of RFID sensors powered with these flexible photovoltaic cells to demonstrate real-world applications. Our evaluation of the prototypes suggests that: i) flexible PV cells are durable up to a bending radius of 5 mm with only a 20 % drop in relative efficiency; ii) RFID communication range increased by 5x, and meets the energy needs (10-350 microwatt) to enable self-powered wireless sensors; iii) perovskite powered wireless sensors enable many battery-less sensing applications (e.g., perishable good monitoring, warehouse automation)
Frontier Detection and Reachability Analysis for Efficient 2D Graph-SLAM Based Active Exploration
Sep 07, 2020

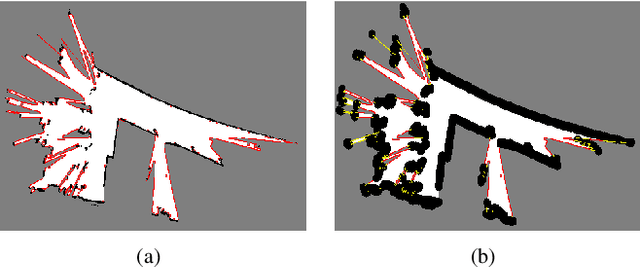

We propose an integrated approach to active exploration by exploiting the Cartographer method as the base SLAM module for submap creation and performing efficient frontier detection in the geometrically co-aligned submaps induced by graph optimization. We also carry out analysis on the reachability of frontiers and their clusters to ensure that the detected frontier can be reached by robot. Our method is tested on a mobile robot in real indoor scene to demonstrate the effectiveness and efficiency of our approach.
PointGrow: Autoregressively Learned Point Cloud Generation with Self-Attention
Oct 12, 2018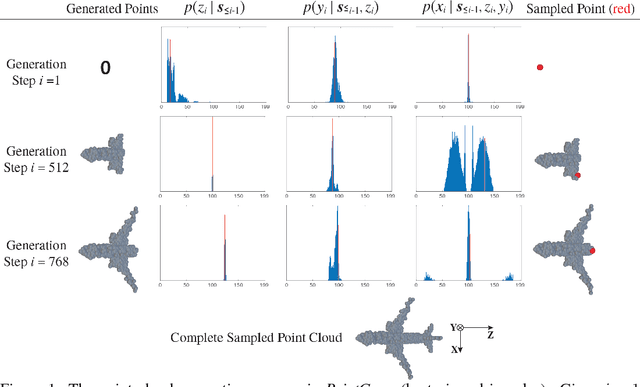
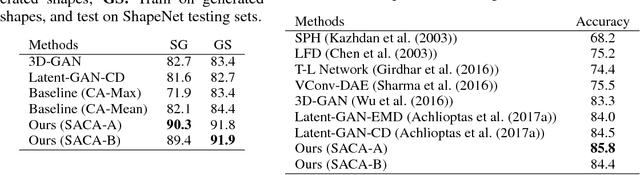
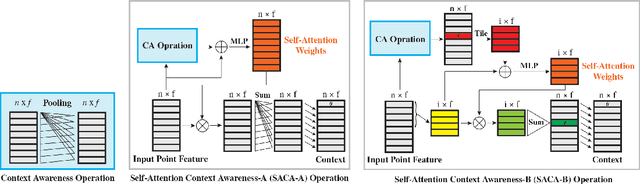
A point cloud is an agile 3D representation, efficiently modeling an object's surface geometry. However, these surface-centric properties also pose challenges on designing tools to recognize and synthesize point clouds. This work presents a novel autoregressive model, PointGrow, which generates realistic point cloud samples from scratch or conditioned on given semantic contexts. Our model operates recurrently, with each point sampled according to a conditional distribution given its previously-generated points. Since point cloud object shapes are typically encoded by long-range interpoint dependencies, we augment our model with dedicated self-attention modules to capture these relations. Extensive evaluation demonstrates that PointGrow achieves satisfying performance on both unconditional and conditional point cloud generation tasks, with respect to fidelity, diversity and semantic preservation. Further, conditional PointGrow learns a smooth manifold of given image conditions where 3D shape interpolation and arithmetic calculation can be performed inside. Code and models are available at: https://github.com/syb7573330/PointGrow.
Im2Avatar: Colorful 3D Reconstruction from a Single Image
Apr 17, 2018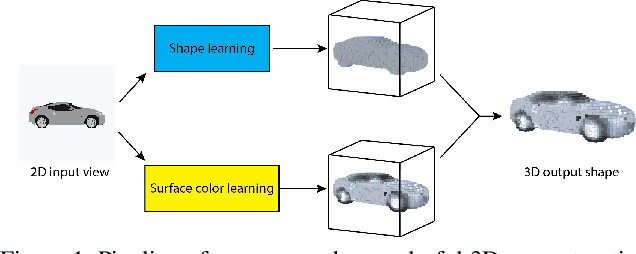
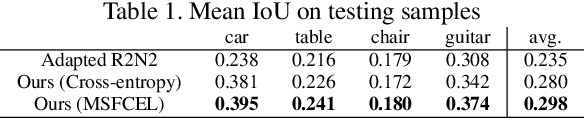
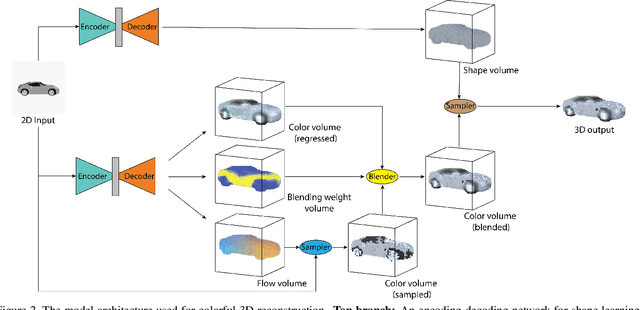
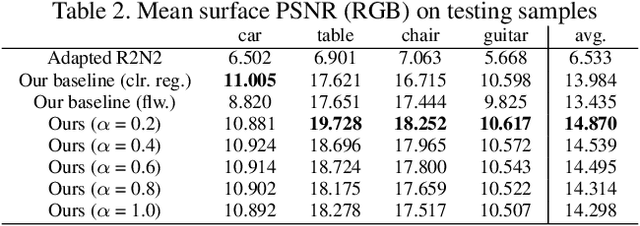
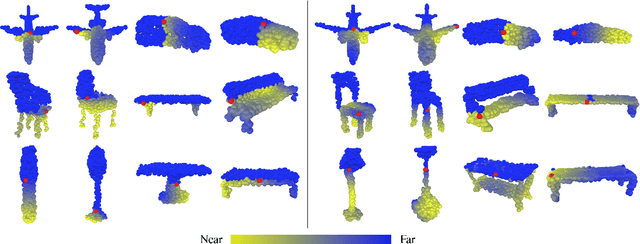
Existing works on single-image 3D reconstruction mainly focus on shape recovery. In this work, we study a new problem, that is, simultaneously recovering 3D shape and surface color from a single image, namely "colorful 3D reconstruction". This problem is both challenging and intriguing because the ability to infer textured 3D model from a single image is at the core of visual understanding. Here, we propose an end-to-end trainable framework, Colorful Voxel Network (CVN), to tackle this problem. Conditioned on a single 2D input, CVN learns to decompose shape and surface color information of a 3D object into a 3D shape branch and a surface color branch, respectively. Specifically, for the shape recovery, we generate a shape volume with the state of its voxels indicating occupancy. For the surface color recovery, we combine the strength of appearance hallucination and geometric projection by concurrently learning a regressed color volume and a 2D-to-3D flow volume, which are then fused into a blended color volume. The final textured 3D model is obtained by sampling color from the blended color volume at the positions of occupied voxels in the shape volume. To handle the severe sparse volume representations, a novel loss function, Mean Squared False Cross-Entropy Loss (MSFCEL), is designed. Extensive experiments demonstrate that our approach achieves significant improvement over baselines, and shows great generalization across diverse object categories and arbitrary viewpoints.
Dynamic Graph CNN for Learning on Point Clouds
Jan 24, 2018
Point clouds provide a flexible and scalable geometric representation suitable for countless applications in computer graphics; they also comprise the raw output of most 3D data acquisition devices. Hence, the design of intelligent computational models that act directly on point clouds is critical, especially when efficiency considerations or noise preclude the possibility of expensive denoising and meshing procedures. While hand-designed features on point clouds have long been proposed in graphics and vision, however, the recent overwhelming success of convolutional neural networks (CNNs) for image analysis suggests the value of adapting insight from CNN to the point cloud world. To this end, we propose a new neural network module dubbed EdgeConv suitable for CNN-based high-level tasks on point clouds including classification and segmentation. EdgeConv is differentiable and can be plugged into existing architectures. Compared to existing modules operating largely in extrinsic space or treating each point independently, EdgeConv has several appealing properties: It incorporates local neighborhood information; it can be stacked or recurrently applied to learn global shape properties; and in multi-layer systems affinity in feature space captures semantic characteristics over potentially long distances in the original embedding. Beyond proposing this module, we provide extensive evaluation and analysis revealing that EdgeConv captures and exploits fine-grained geometric properties of point clouds. The proposed approach achieves state-of-the-art performance on standard benchmarks including ModelNet40 and S3DIS.