 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Diverse Fashion Collocation by Neural Graph Filtering
Mar 11, 2020
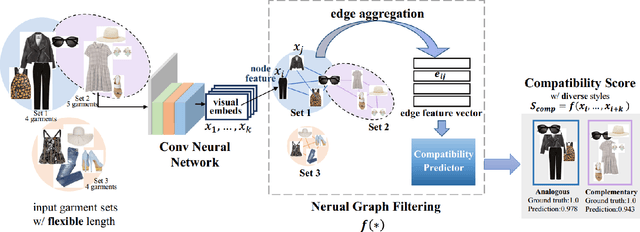


Fashion recommendation systems are highly desired by customers to find visually-collocated fashion items, such as clothes, shoes, bags, etc. While existing methods demonstrate promising results, they remain lacking in flexibility and diversity, e.g. assuming a fixed number of items or favoring safe but boring recommendations. In this paper, we propose a novel fashion collocation framework, Neural Graph Filtering, that models a flexible set of fashion items via a graph neural network. Specifically, we consider the visual embeddings of each garment as a node in the graph, and describe the inter-garment relationship as the edge between nodes. By applying symmetric operations on the edge vectors, this framework allows varying numbers of inputs/outputs and is invariant to their ordering. We further include a style classifier augmented with focal loss to enable the collocation of significantly diverse styles, which are inherently imbalanced in the training set. To facilitate a comprehensive study on diverse fashion collocation, we reorganize Amazon Fashion dataset with carefully designed evaluation protocols. We evaluate the proposed approach on three popular benchmarks, the Polyvore dataset, the Polyvore-D dataset, and our reorganized Amazon Fashion dataset. Extensive experimental results show that our approach significantly outperforms the state-of-the-art methods with over 10% improvements on the standard AUC metric on the established tasks. More importantly, 82.5% of the users prefer our diverse-style recommendations over other alternatives in a real-world perception study.
A gamified simulator and physical platform for self-driving algorithm training and validation
Nov 18, 2019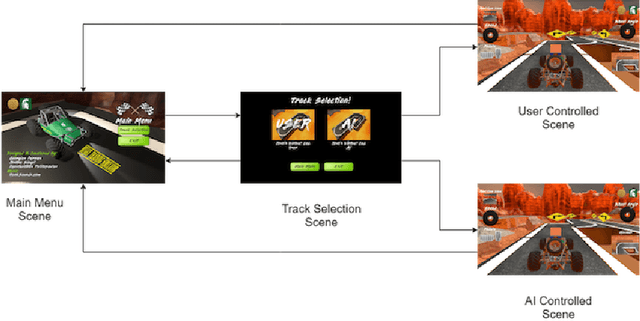


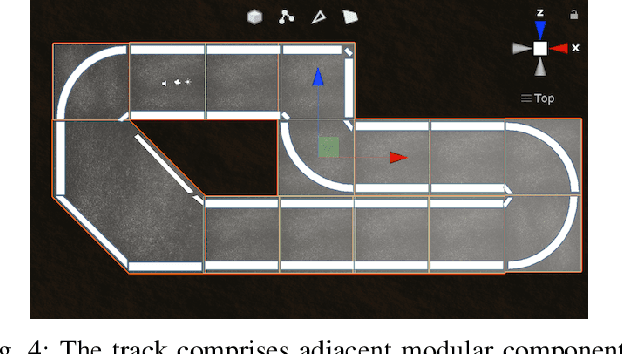
We identify the need for a gamified self-driving simulator where game mechanics encourage high-quality data capture, and design and apply such a simulator to collecting lane-following training data. The resulting synthetic data enables a Convolutional Neural Network (CNN) to drive an in-game vehicle. We simultaneously develop a physical test platform based on a radio-controlled vehicle and the Robotic Operating System (ROS) and successfully transfer the simulation-trained model to the physical domain without modification. The cross-platform simulator facilitates unsupervised crowdsourcing, helping to collect diverse data emulating complex, dynamic environment data, infrequent events, and edge cases. The physical platform provides a low-cost solution for validating simulation-trained models or enabling rapid transfer learning, thereby improving the safety and resilience of self-driving algorithms.
PointGrow: Autoregressively Learned Point Cloud Generation with Self-Attention
Oct 12, 2018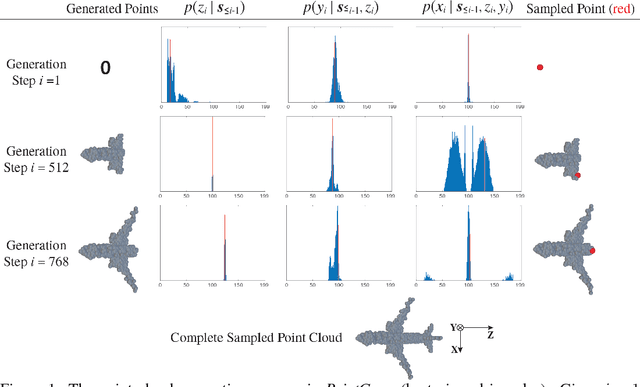
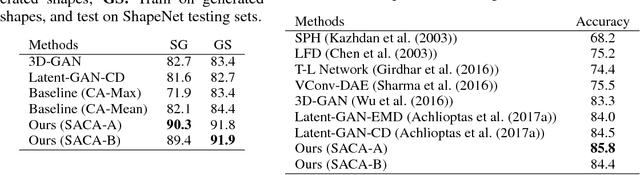
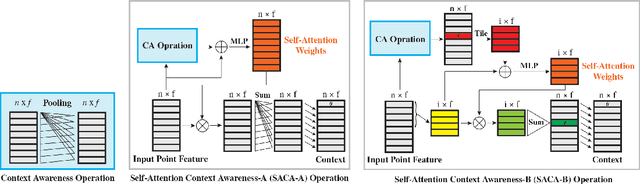
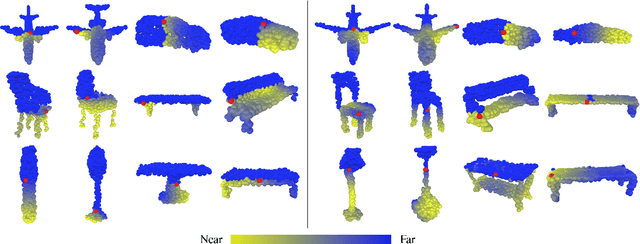
A point cloud is an agile 3D representation, efficiently modeling an object's surface geometry. However, these surface-centric properties also pose challenges on designing tools to recognize and synthesize point clouds. This work presents a novel autoregressive model, PointGrow, which generates realistic point cloud samples from scratch or conditioned on given semantic contexts. Our model operates recurrently, with each point sampled according to a conditional distribution given its previously-generated points. Since point cloud object shapes are typically encoded by long-range interpoint dependencies, we augment our model with dedicated self-attention modules to capture these relations. Extensive evaluation demonstrates that PointGrow achieves satisfying performance on both unconditional and conditional point cloud generation tasks, with respect to fidelity, diversity and semantic preservation. Further, conditional PointGrow learns a smooth manifold of given image conditions where 3D shape interpolation and arithmetic calculation can be performed inside. Code and models are available at: https://github.com/syb7573330/PointGrow.
Im2Avatar: Colorful 3D Reconstruction from a Single Image
Apr 17, 2018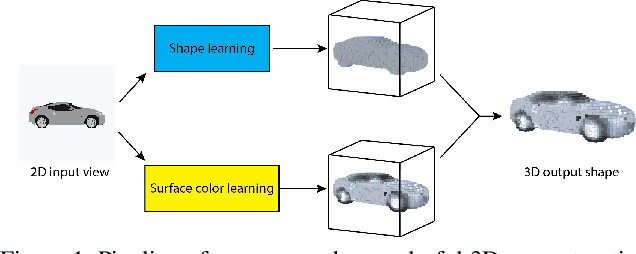
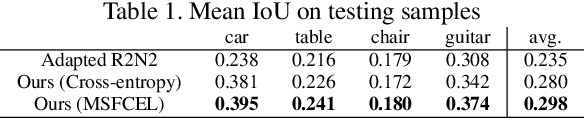
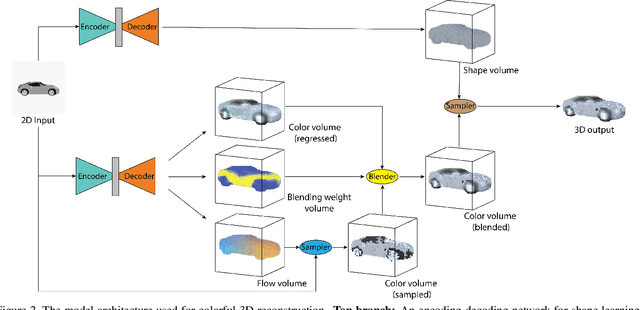
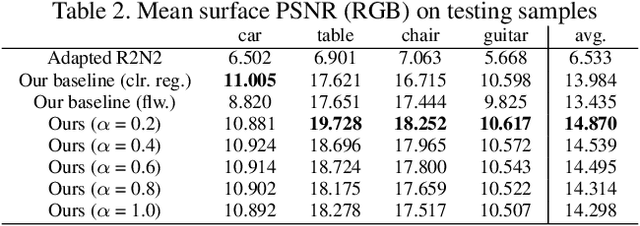
Existing works on single-image 3D reconstruction mainly focus on shape recovery. In this work, we study a new problem, that is, simultaneously recovering 3D shape and surface color from a single image, namely "colorful 3D reconstruction". This problem is both challenging and intriguing because the ability to infer textured 3D model from a single image is at the core of visual understanding. Here, we propose an end-to-end trainable framework, Colorful Voxel Network (CVN), to tackle this problem. Conditioned on a single 2D input, CVN learns to decompose shape and surface color information of a 3D object into a 3D shape branch and a surface color branch, respectively. Specifically, for the shape recovery, we generate a shape volume with the state of its voxels indicating occupancy. For the surface color recovery, we combine the strength of appearance hallucination and geometric projection by concurrently learning a regressed color volume and a 2D-to-3D flow volume, which are then fused into a blended color volume. The final textured 3D model is obtained by sampling color from the blended color volume at the positions of occupied voxels in the shape volume. To handle the severe sparse volume representations, a novel loss function, Mean Squared False Cross-Entropy Loss (MSFCEL), is designed. Extensive experiments demonstrate that our approach achieves significant improvement over baselines, and shows great generalization across diverse object categories and arbitrary viewpoints.
Dynamic Graph CNN for Learning on Point Clouds
Jan 24, 2018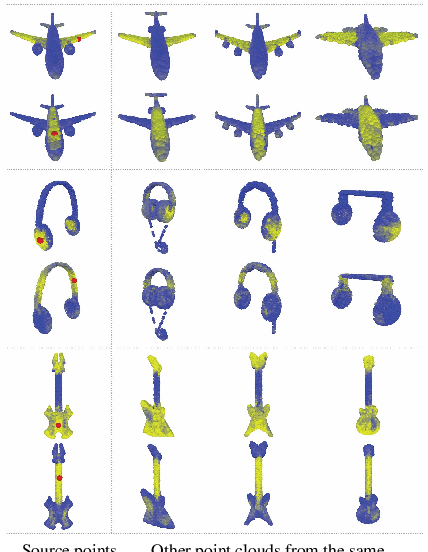
Point clouds provide a flexible and scalable geometric representation suitable for countless applications in computer graphics; they also comprise the raw output of most 3D data acquisition devices. Hence, the design of intelligent computational models that act directly on point clouds is critical, especially when efficiency considerations or noise preclude the possibility of expensive denoising and meshing procedures. While hand-designed features on point clouds have long been proposed in graphics and vision, however, the recent overwhelming success of convolutional neural networks (CNNs) for image analysis suggests the value of adapting insight from CNN to the point cloud world. To this end, we propose a new neural network module dubbed EdgeConv suitable for CNN-based high-level tasks on point clouds including classification and segmentation. EdgeConv is differentiable and can be plugged into existing architectures. Compared to existing modules operating largely in extrinsic space or treating each point independently, EdgeConv has several appealing properties: It incorporates local neighborhood information; it can be stacked or recurrently applied to learn global shape properties; and in multi-layer systems affinity in feature space captures semantic characteristics over potentially long distances in the original embedding. Beyond proposing this module, we provide extensive evaluation and analysis revealing that EdgeConv captures and exploits fine-grained geometric properties of point clouds. The proposed approach achieves state-of-the-art performance on standard benchmarks including ModelNet40 and S3DIS.