 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontierOR: Benchmarking LLMs' Capacity for Efficient Algorithm Design in Large-Scale Optimization
May 26, 2026Large language models (LLMs) are increasingly used for optimization modeling and solver-code generation, yet practical operations research and optimization problems often require a harder capability: designing scalable algorithms that exploit problem structure and outperform direct formulation-and-solve baselines. Existing benchmarks are limited to small or simplified examples far below real-world scale and complexity. We introduce FrontierOR, among the first benchmarks to systematically evaluate LLM-based efficient algorithm design for realistic large-scale optimization problems. FrontierOR includes 180 tasks derived from methodologically diverse papers published in top-tier operations research venues, each with standardized instances and a hidden, expert-verified evaluation suite. We evaluate seven LLMs spanning frontier, cost-effective, and open-source models both in one-shot and test-time evolution settings. The results reveal that frontier models still struggle to move from executable formulations to efficient optimization algorithms: the strongest one-shot model outperforms Gurobi in only 31% of cases in both solution quality and computational efficiency, and even strong coding agents with test-time evolution achieve only 50% on selected hard tasks. FrontierOR establishes a practical evaluation platform for LLM-based optimization algorithm design, which enables future LLMs and agents to be systematically tested on whether they can move beyond correct formulation toward a feasible, high-quality, and efficient algorithm.
RF-Enhanced Road Infrastructure for Intelligent Transportation
Nov 01, 2023



The EPC GEN 2 communication protocol for Ultra-high frequency Radio Frequency Identification (RFID) has offered a promising avenue for advancing the intelligence of transportation infrastructure. With the capability of linking vehicles to RFID readers to crowdsource information from RFID tags on road infrastructures, the RF-enhanced road infrastructure (REI) can potentially transform data acquisition for urban transportation. Despite its potential, the broader adoption of RFID technologies in building intelligent roads has been limited by a deficiency in understanding how the GEN 2 protocol impacts system performance under different transportation settings. This paper fills this knowledge gap by presenting the system architecture and detailing the design challenges associated with REI. Comprehensive real-world experiments are conducted to assess REI's effectiveness across various urban contexts. The results yield crucial insights into the optimal design of on-vehicle RFID readers and on-road RFID tags, considering the constraints imposed by vehicle dynamics, road geometries, and tag placements. With the optimized designs of encoding schemes for reader-tag communication and on-vehicle antennas, REI is able to fulfill the requirements of traffic sign inventory management and environmental monitoring while falling short of catering to the demand for high-speed navigation. In particular, the Miller 2 encoding scheme strikes the best balance between reading performance (e.g., throughput) and noise tolerance for the multipath effect. Additionally, we show that the on-vehicle antenna should be oriented to maximize the available time for reading on-road tags, although it may reduce the received power by the tags in the forward link.
TrTr: A Versatile Pre-Trained Large Traffic Model based on Transformer for Capturing Trajectory Diversity in Vehicle Population
Sep 22, 2023



Understanding trajectory diversity is a fundamental aspect of addressing practical traffic tasks. However, capturing the diversity of trajectories presents challenges, particularly with traditional machine learning and recurrent neural networks due to the requirement of large-scale parameters. The emerging Transformer technology, renowned for its parallel computation capabilities enabling the utilization of models with hundreds of millions of parameters, offers a promising solution. In this study, we apply the Transformer architecture to traffic tasks, aiming to learn the diversity of trajectories within vehicle populations. We analyze the Transformer's attention mechanism and its adaptability to the goals of traffic tasks, and subsequently, design specific pre-training tasks. To achieve this, we create a data structure tailored to the attention mechanism and introduce a set of noises that correspond to spatio-temporal demands, which are incorporated into the structured data during the pre-training process. The designed pre-training model demonstrates excellent performance in capturing the spatial distribution of the vehicle population, with no instances of vehicle overlap and an RMSE of 0.6059 when compared to the ground truth values. In the context of time series prediction, approximately 95% of the predicted trajectories' speeds closely align with the true speeds, within a deviation of 7.5144m/s. Furthermore, in the stability test, the model exhibits robustness by continuously predicting a time series ten times longer than the input sequence, delivering smooth trajectories and showcasing diverse driving behaviors. The pre-trained model also provides a good basis for downstream fine-tuning tasks. The number of parameters of our model is over 50 million.
A Novel Temporal Multi-Gate Mixture-of-Experts Approach for Vehicle Trajectory and Driving Intention Prediction
Aug 01, 2023



Accurate Vehicle Trajectory Prediction is critical for automated vehicles and advanced driver assistance systems. Vehicle trajectory prediction consists of two essential tasks, i.e., longitudinal position prediction and lateral position prediction. There is a significant correlation between driving intentions and vehicle motion. In existing work, the three tasks are often conducted separately without considering the relationships between the longitudinal position, lateral position, and driving intention. In this paper, we propose a novel Temporal Multi-Gate Mixture-of-Experts (TMMOE) model for simultaneously predicting the vehicle trajectory and driving intention. The proposed model consists of three layers: a shared layer, an expert layer, and a fully connected layer. In the model, the shared layer utilizes Temporal Convolutional Networks (TCN) to extract temporal features. Then the expert layer is built to identify different information according to the three tasks. Moreover, the fully connected layer is used to integrate and export prediction results. To achieve better performance, uncertainty algorithm is used to construct the multi-task loss function. Finally, the publicly available CitySim dataset validates the TMMOE model, demonstrating superior performance compared to the LSTM model, achieving the highest classification and regression results. Keywords: Vehicle trajectory prediction, driving intentions Classification, Multi-task
TrafficSafetyGPT: Tuning a Pre-trained Large Language Model to a Domain-Specific Expert in Transportation Safety
Jul 28, 2023Large Language Models (LLMs) have shown remarkable effectiveness in various general-domain natural language processing (NLP) tasks. However, their performance in transportation safety domain tasks has been suboptimal, primarily attributed to the requirement for specialized transportation safety expertise in generating accurate responses [1]. To address this challenge, we introduce TrafficSafetyGPT, a novel LLAMA-based model, which has undergone supervised fine-tuning using TrafficSafety-2K dataset which has human labels from government produced guiding books and ChatGPT-generated instruction-output pairs. Our proposed TrafficSafetyGPT model and TrafficSafety-2K train dataset are accessible at https://github.com/ozheng1993/TrafficSafetyGPT.
A Unified Approach to Lane Change Intention Recognition and Driving Status Prediction through TCN-LSTM and Multi-Task Learning Models
Apr 25, 2023
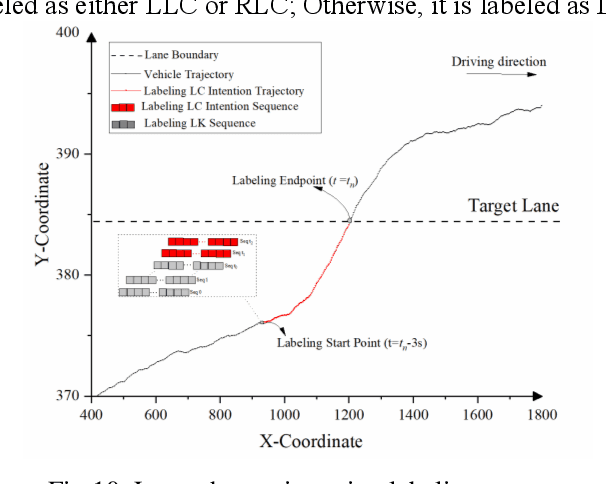
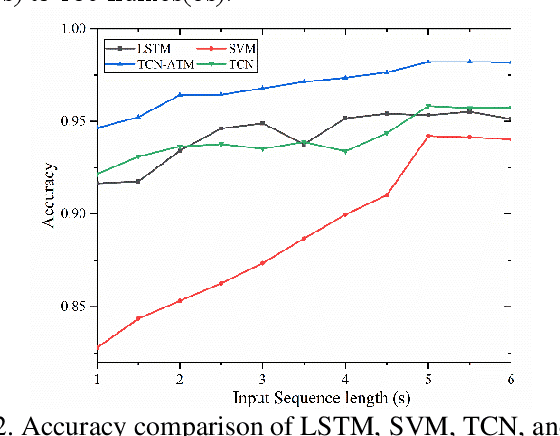
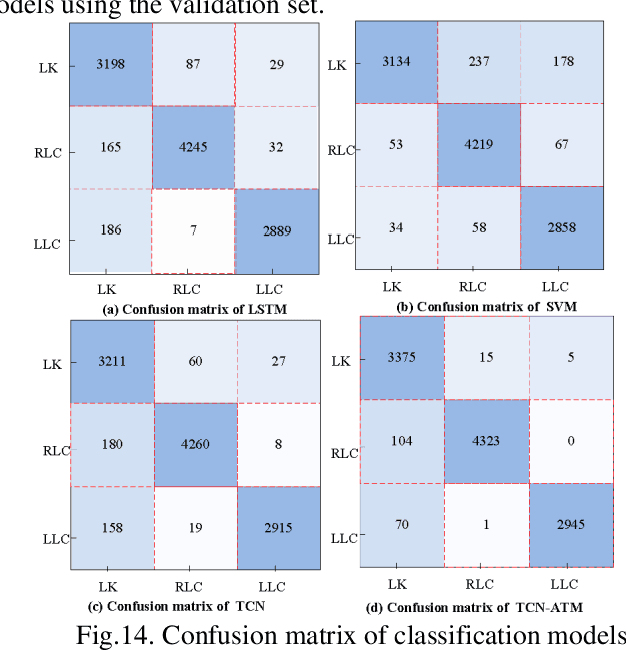
Lane change (LC) is a continuous and complex operation process. Accurately detecting and predicting LC processes can help traffic participants better understand their surrounding environment, recognize potential LC safety hazards, and improve traffic safety. This present paper focuses on LC processes, developing an LC intention recognition (LC-IR) model and an LC status prediction (LC-SP) model. A novel ensemble temporal convolutional network with Long Short-Term Memory units (TCN-LSTM) is first proposed to capture long-range dependencies in sequential data. Then, three multi-task models (MTL-LSTM, MTL-TCN, MTL-TCN -LSTM) are developed to capture the intrinsic relationship among output indicators. Furthermore, a unified modeling framework for LC intention recognition and driving status prediction (LC-IR-SP) is developed. To validate the performance of the proposed models, a total number of 1023 vehicle trajectories is extracted from the CitySim dataset. The Pearson coefficient is employed to determine the related indicators. The results indicate that using150 frames as input length, the TCN-LSTM model with 96.67% accuracy outperforms TCN and LSTM models in LC intention classification and provides more balanced results for each class. Three proposed multi-tasking learning models provide markedly increased performance compared to corresponding single-task models, with an average reduction of 24.24% and 22.86% in the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE), respectively. The developed LC-IR-SP model has promising applications for autonomous vehicles to identity lane change behaviors, calculate a real-time traffic conflict index and improve vehicle control strategies.
Advances and Applications of Computer Vision Techniques in Vehicle Trajectory Generation and Surrogate Traffic Safety Indicators
Mar 27, 2023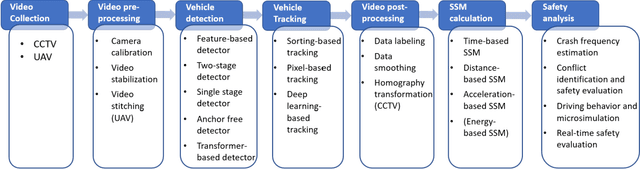
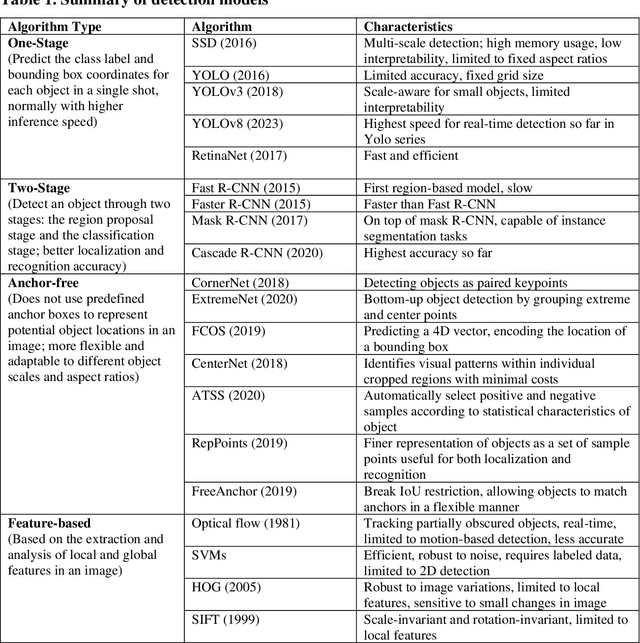
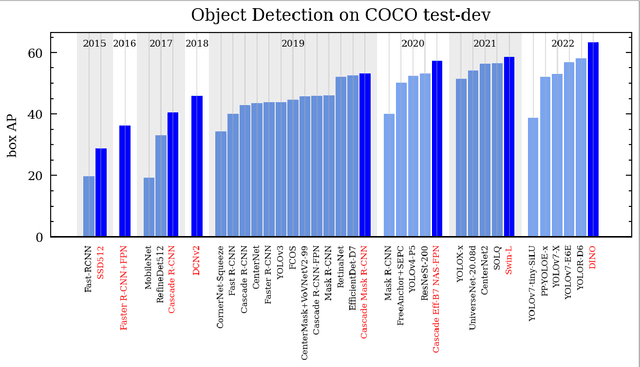
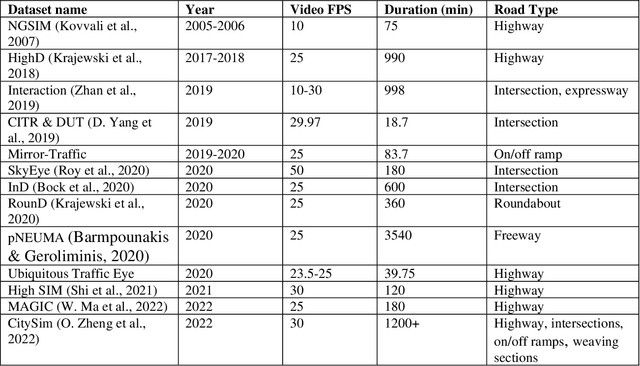
The application of Computer Vision (CV) techniques massively stimulates microscopic traffic safety analysis from the perspective of traffic conflicts and near misses, which is usually measured using Surrogate Safety Measures (SSM). However, as video processing and traffic safety modeling are two separate research domains and few research have focused on systematically bridging the gap between them, it is necessary to provide transportation researchers and practitioners with corresponding guidance. With this aim in mind, this paper focuses on reviewing the applications of CV techniques in traffic safety modeling using SSM and suggesting the best way forward. The CV algorithm that are used for vehicle detection and tracking from early approaches to the state-of-the-art models are summarized at a high level. Then, the video pre-processing and post-processing techniques for vehicle trajectory extraction are introduced. A detailed review of SSMs for vehicle trajectory data along with their application on traffic safety analysis is presented. Finally, practical issues in traffic video processing and SSM-based safety analysis are discussed, and the available or potential solutions are provided. This review is expected to assist transportation researchers and engineers with the selection of suitable CV techniques for video processing, and the usage of SSMs for various traffic safety research objectives.
AVOID: Autonomous Vehicle Operation Incident Dataset Across the Globe
Mar 22, 2023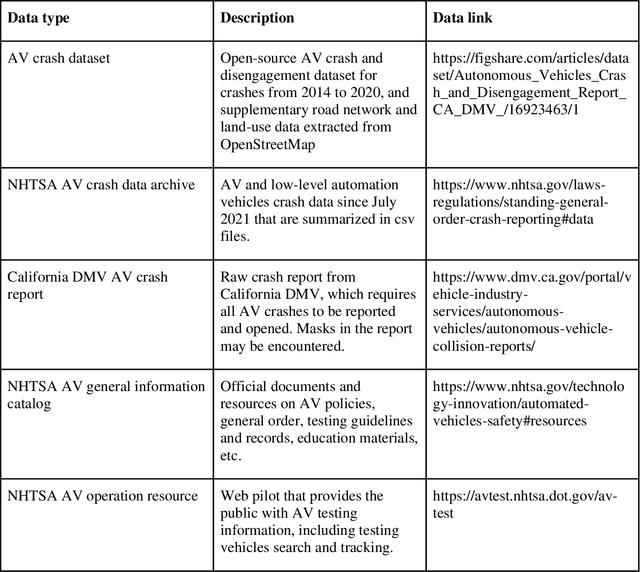
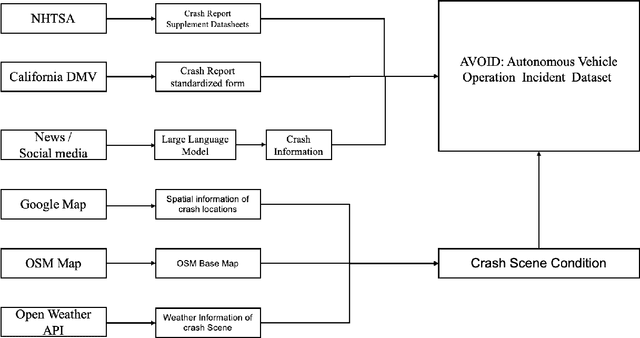
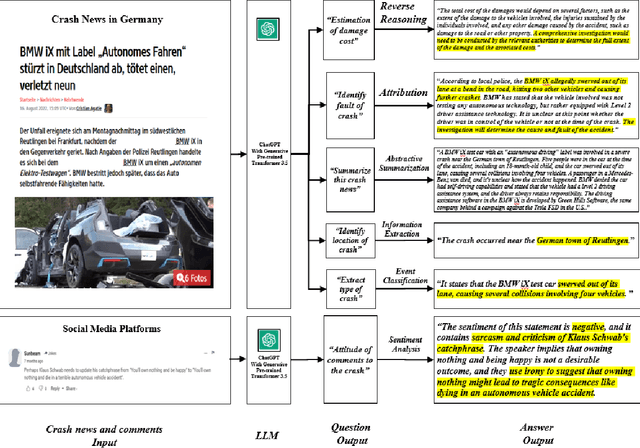
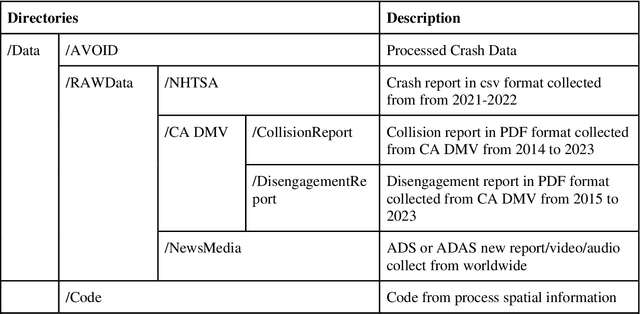
Crash data of autonomous vehicles (AV) or vehicles equipped with advanced driver assistance systems (ADAS) are the key information to understand the crash nature and to enhance the automation systems. However, most of the existing crash data sources are either limited by the sample size or suffer from missing or unverified data. To contribute to the AV safety research community, we introduce AVOID: an open AV crash dataset. Three types of vehicles are considered: Advanced Driving System (ADS) vehicles, Advanced Driver Assistance Systems (ADAS) vehicles, and low-speed autonomous shuttles. The crash data are collected from the National Highway Traffic Safety Administration (NHTSA), California Department of Motor Vehicles (CA DMV) and incident news worldwide, and the data are manually verified and summarized in ready-to-use format. In addition, land use, weather, and geometry information are also provided. The dataset is expected to accelerate the research on AV crash analysis and potential risk identification by providing the research community with data of rich samples, diverse data sources, clear data structure, and high data quality.
ChatGPT Is on the Horizon: Could a Large Language Model Be All We Need for Intelligent Transportation?
Mar 21, 2023



ChatGPT, developed by OpenAI, is one of the milestone large language models (LLMs) with 6 billion parameters. ChatGPT has demonstrated the impressive language understanding capability of LLM, particularly in generating conversational response. As LLMs start to gain more attention in various research or engineering domains, it is time to envision how LLM may revolutionize the way we approach intelligent transportation systems. This paper explores the future applications of LLM in addressing key transportation problems. By leveraging LLM with cross-modal encoder, an intelligent system can also process traffic data from different modalities and execute transportation operations through an LLM. We present and validate these potential transportation applications equipped by LLM. To further demonstrate this potential, we also provide a concrete smartphone-based crash report auto-generation and analysis framework as a use case. Despite the potential benefits, challenges related to data privacy, data quality, and model bias must be considered. Overall, the use of LLM in intelligent transport systems holds promise for more efficient, intelligent, and sustainable transportation systems that further improve daily life around the world.
Towards Next Generation of Pedestrian and Connected Vehicle In-the-loop Research: A Digital Twin Simulation Framework
Dec 08, 2022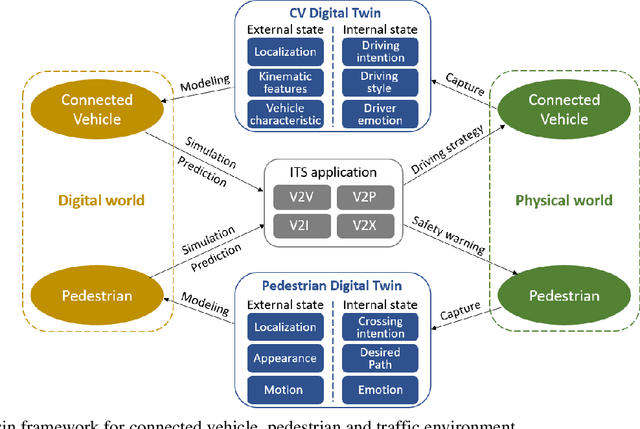
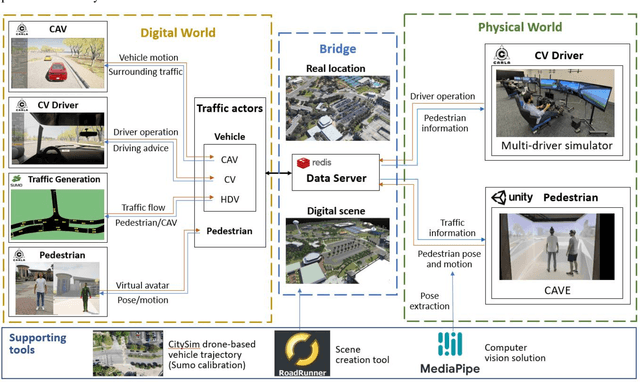
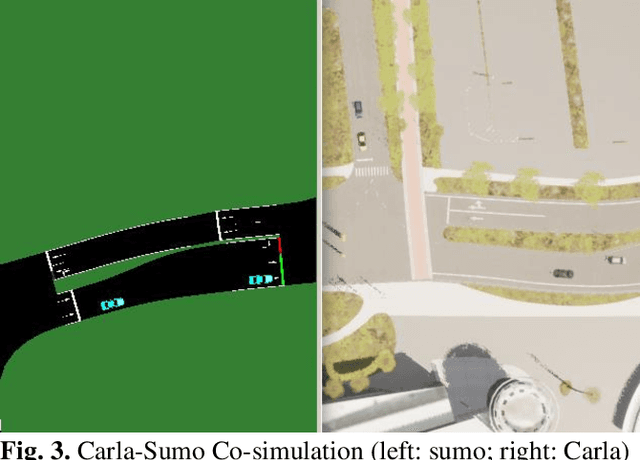
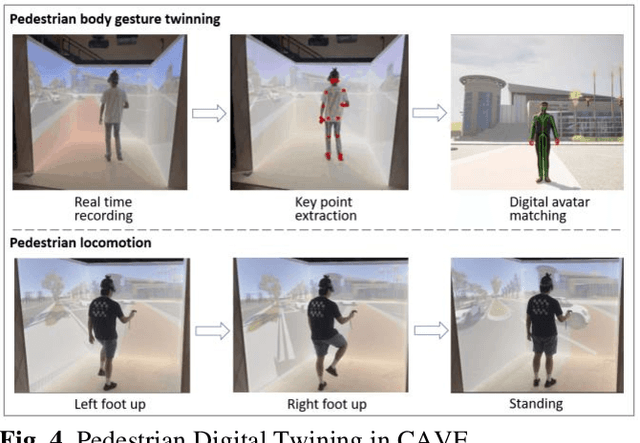
Digital Twin is an emerging technology that replicates real-world entities into a digital space. It has attracted increasing attention in the transportation field and many researchers are exploring its future applications in the development of Intelligent Transportation System (ITS) technologies. Connected vehicles (CVs) and pedestrians are among the major traffic participants in ITS. However, the usage of Digital Twin in research involving both CV and pedestrian remains largely unexplored. In this study, a Digital Twin framework for CV and pedestrian in-the-loop simulation is proposed. The proposed framework consists of the physical world, the digital world, and data transmission in between. The features for the entities (CV and pedestrian) that need digital twined are divided into external state and internal state, and the attributes in each state are described. We also demonstrate a sample architecture under the proposed Digital Twin framework, which is based on Carla-Sumo Co-simulation and Cave automatic virtual environment (CAVE). The proposed framework is expected to provide guidance to the future Digital Twin research, and the architecture we build can serve as the testbed for further research and development of ITS applications on CV and pedestrian.