 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Skills to Talent: Organising Heterogeneous Agents as a Real-World Company
Apr 24, 2026Individual agent capabilities have advanced rapidly through modular skills and tool integrations, yet multi-agent systems remain constrained by fixed team structures, tightly coupled coordination logic, and session-bound learning. We argue that this reflects a deeper absence: a principled organisational layer that governs how a workforce of agents is assembled, governed, and improved over time, decoupled from what individual agents know. To fill this gap, we introduce \emph{OneManCompany (OMC)}, a framework that elevates multi-agent systems to the organisational level. OMC encapsulates skills, tools, and runtime configurations into portable agent identities called \emph{Talents}, orchestrated through typed organisational interfaces that abstract over heterogeneous backends. A community-driven \emph{Talent Market} enables on-demand recruitment, allowing the organisation to close capability gaps and reconfigure itself dynamically during execution. Organisational decision-making is operationalised through an \emph{Explore-Execute-Review} ($\text{E}^2$R) tree search, which unifies planning, execution, and evaluation in a single hierarchical loop: tasks are decomposed top-down into accountable units and execution outcomes are aggregated bottom-up to drive systematic review and refinement. This loop provides formal guarantees on termination and deadlock freedom while mirroring the feedback mechanisms of human enterprises. Together, these contributions transform multi-agent systems from static, pre-configured pipelines into self-organising and self-improving AI organisations capable of adapting to open-ended tasks across diverse domains. Empirical evaluation on PRDBench shows that OMC achieves an $84.67\%$ success rate, surpassing the state of the art by $15.48$ percentage points, with cross-domain case studies further demonstrating its generality.
InfoSeeker: A Scalable Hierarchical Parallel Agent Framework for Web Information Seeking
Apr 03, 2026Recent agentic search systems have made substantial progress by emphasising deep, multi-step reasoning. However, this focus often overlooks the challenges of wide-scale information synthesis, where agents must aggregate large volumes of heterogeneous evidence across many sources. As a result, most existing large language model agent systems face severe limitations in data-intensive settings, including context saturation, cascading error propagation, and high end-to-end latency. To address these challenges, we present \framework, a hierarchical framework based on principle of near-decomposability, containing a strategic \textit{Host}, multiple \textit{Managers} and parallel \textit{Workers}. By leveraging aggregation and reflection mechanisms at the Manager layer, our framework enforces strict context isolation to prevent saturation and error propagation. Simultaneously, the parallelism in worker layer accelerates the speed of overall task execution, mitigating the significant latency. Our evaluation on two complementary benchmarks demonstrates both efficiency ($ 3-5 \times$ speed-up) and effectiveness, achieving a $8.4\%$ success rate on WideSearch-en and $52.9\%$ accuracy on BrowseComp-zh. The code is released at https://github.com/agent-on-the-fly/InfoSeeker
Spontaneous Spatial Cognition Emerges during Egocentric Video Viewing through Non-invasive BCI
Jul 16, 2025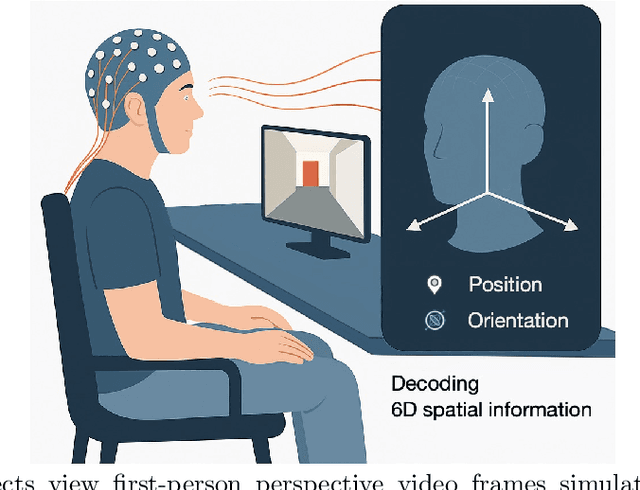

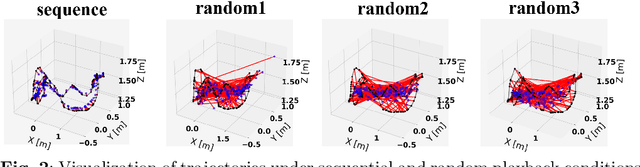

Humans possess a remarkable capacity for spatial cognition, allowing for self-localization even in novel or unfamiliar environments. While hippocampal neurons encoding position and orientation are well documented, the large-scale neural dynamics supporting spatial representation, particularly during naturalistic, passive experience, remain poorly understood. Here, we demonstrate for the first time that non-invasive brain-computer interfaces (BCIs) based on electroencephalography (EEG) can decode spontaneous, fine-grained egocentric 6D pose, comprising three-dimensional position and orientation, during passive viewing of egocentric video. Despite EEG's limited spatial resolution and high signal noise, we find that spatially coherent visual input (i.e., continuous and structured motion) reliably evokes decodable spatial representations, aligning with participants' subjective sense of spatial engagement. Decoding performance further improves when visual input is presented at a frame rate of 100 ms per image, suggesting alignment with intrinsic neural temporal dynamics. Using gradient-based backpropagation through a neural decoding model, we identify distinct EEG channels contributing to position -- and orientation specific -- components, revealing a distributed yet complementary neural encoding scheme. These findings indicate that the brain's spatial systems operate spontaneously and continuously, even under passive conditions, challenging traditional distinctions between active and passive spatial cognition. Our results offer a non-invasive window into the automatic construction of egocentric spatial maps and advance our understanding of how the human mind transforms everyday sensory experience into structured internal representations.
Synthesis by Design: Controlled Data Generation via Structural Guidance
Jun 09, 2025Mathematical reasoning remains challenging for LLMs due to complex logic and the need for precise computation. Existing methods enhance LLM reasoning by synthesizing datasets through problem rephrasing, but face issues with generation quality and problem complexity. To address this, we propose to extract structural information with generated problem-solving code from mathematical reasoning and guide data generation with structured solutions. Applied to MATH and GSM8K, our approach produces 39K problems with labeled intermediate steps and a 6.1K-problem benchmark of higher difficulty. Results on our benchmark show that model performance declines as reasoning length increases. Additionally, we conducted fine-tuning experiments using the proposed training data on a range of LLMs, and the results validate the effectiveness of our dataset. We hope the proposed method and dataset will contribute to future research in enhancing LLM reasoning capabilities.
ATLaS: Agent Tuning via Learning Critical Steps
Mar 04, 2025



Large Language Model (LLM) agents have demonstrated remarkable generalization capabilities across multi-domain tasks. Existing agent tuning approaches typically employ supervised finetuning on entire expert trajectories. However, behavior-cloning of full trajectories can introduce expert bias and weaken generalization to states not covered by the expert data. Additionally, critical steps, such as planning, complex reasoning for intermediate subtasks, and strategic decision-making, are essential to success in agent tasks, so learning these steps is the key to improving LLM agents. For more effective and efficient agent tuning, we propose ATLaS that identifies the critical steps in expert trajectories and finetunes LLMs solely on these steps with reduced costs. By steering the training's focus to a few critical steps, our method mitigates the risk of overfitting entire trajectories and promotes generalization across different environments and tasks. In extensive experiments, an LLM finetuned on only 30% critical steps selected by ATLaS outperforms the LLM finetuned on all steps and recent open-source LLM agents. ATLaS maintains and improves base LLM skills as generalist agents interacting with diverse environments.
Orca: Enhancing Role-Playing Abilities of Large Language Models by Integrating Personality Traits
Nov 15, 2024Large language models has catalyzed the development of personalized dialogue systems, numerous role-playing conversational agents have emerged. While previous research predominantly focused on enhancing the model's capability to follow instructions by designing character profiles, neglecting the psychological factors that drive human conversations. In this paper, we propose Orca, a framework for data processing and training LLMs of custom characters by integrating personality traits. Orca comprises four stages: (1) Personality traits inferring, leverage LLMs to infer user's BigFive personality trait reports and scores. (2) Data Augment, simulate user's profile, background story, and psychological activities. (3) Dataset construction, personality-conditioned instruction prompting (PCIP) to stimulate LLMs. (4) Modeling and Training, personality-conditioned instruction tuning (PTIT and PSIT), using the generated data to enhance existing open-source LLMs. We introduce OrcaBench, the first benchmark for evaluating the quality of content generated by LLMs on social platforms across multiple scales. Our experiments demonstrate that our proposed model achieves superior performance on this benchmark, demonstrating its excellence and effectiveness in perceiving personality traits that significantly improve role-playing abilities. Our Code is available at https://github.com/Aipura/Orca.
Alignment Between the Decision-Making Logic of LLMs and Human Cognition: A Case Study on Legal LLMs
Oct 06, 2024



This paper presents a method to evaluate the alignment between the decision-making logic of Large Language Models (LLMs) and human cognition in a case study on legal LLMs. Unlike traditional evaluations on language generation results, we propose to evaluate the correctness of the detailed decision-making logic of an LLM behind its seemingly correct outputs, which represents the core challenge for an LLM to earn human trust. To this end, we quantify the interactions encoded by the LLM as primitive decision-making logic, because recent theoretical achievements have proven several mathematical guarantees of the faithfulness of the interaction-based explanation. We design a set of metrics to evaluate the detailed decision-making logic of LLMs. Experiments show that even when the language generation results appear correct, a significant portion of the internal inference logic contains notable issues.
Open-Set Video-based Facial Expression Recognition with Human Expression-sensitive Prompting
Apr 26, 2024In Video-based Facial Expression Recognition (V-FER), models are typically trained on closed-set datasets with a fixed number of known classes. However, these V-FER models cannot deal with unknown classes that are prevalent in real-world scenarios. In this paper, we introduce a challenging Open-set Video-based Facial Expression Recognition (OV-FER) task, aiming at identifying not only known classes but also new, unknown human facial expressions not encountered during training. While existing approaches address open-set recognition by leveraging large-scale vision-language models like CLIP to identify unseen classes, we argue that these methods may not adequately capture the nuanced and subtle human expression patterns required by the OV-FER task. To address this limitation, we propose a novel Human Expression-Sensitive Prompting (HESP) mechanism to significantly enhance CLIP's ability to model video-based facial expression details effectively, thereby presenting a new CLIP-based OV-FER approach. Our proposed HESP comprises three components: 1) a textual prompting module with learnable prompt representations to complement the original CLIP textual prompts and enhance the textual representations of both known and unknown emotions, 2) a visual prompting module that encodes temporal emotional information from video frames using expression-sensitive attention, equipping CLIP with a new visual modeling ability to extract emotion-rich information, 3) a delicately designed open-set multi-task learning scheme that facilitates prompt learning and encourages interactions between the textual and visual prompting modules. Extensive experiments conducted on four OV-FER task settings demonstrate that HESP can significantly boost CLIP's performance (a relative improvement of 17.93% on AUROC and 106.18% on OSCR) and outperform other state-of-the-art open-set video understanding methods by a large margin.
LLM-ARK: Knowledge Graph Reasoning Using Large Language Models via Deep Reinforcement Learning
Dec 18, 2023



With the evolution of pre-training methods, large language models (LLMs) have exhibited exemplary reasoning capabilities via prompt engineering. However, the absence of Knowledge Graph (KG) environment awareness and the challenge of engineering viable optimization mechanisms for intermediary reasoning processes, constrict the performance of LLMs on KG reasoning tasks compared to smaller models. We introduce LLM-ARK, a LLM grounded KG reasoning agent designed to deliver precise and adaptable predictions on KG paths. LLM-ARK utilizes Full Textual Environment (FTE) prompts to assimilate state information for each step-sized intelligence. Leveraging LLMs to richly encode and represent various types of inputs and integrate the knowledge graph further with path environment data, before making the final decision. Reframing the Knowledge Graph (KG) multi-hop inference problem as a sequential decision-making issue, we optimize our model using the Proximal Policy Optimization (PPO) online policy gradient reinforcement learning algorithm which allows the model to learn from a vast array of reward signals across diverse tasks and environments. We evaluate state-of-the-art LLM(GPT-4) and our method which using open-source models of varying sizes on OpenDialKG dataset. Our experiment shows that LLaMA7B-ARK provides excellent results with a performance rate of 48.75% for the target@1 evaluation metric, far exceeding the current state-of-the-art model by 17.64 percentage points. Meanwhile, GPT-4 accomplished a score of only 14.91%, further highlighting the efficacy and complexity of our methodology. Our code is available on GitHub for further access.
Automatic Image Blending Algorithm Based on SAM and DINO
Jun 11, 2023The field of image blending has gained popularity in recent years for its ability to create visually stunning content. However, the current image blending algorithm has the following problems: 1) The manual creation of the image blending mask requires a lot of manpower and material resources; 2) The image blending algorithm cannot effectively solve the problems of brightness distortion and low resolution. To this end, we propose a new image blending method: it combines semantic object detection and segmentation with corresponding mask generation to automatically blend images, while a two-stage iterative algorithm based on our proposed new saturation loss and PAN algorithm to fix brightness distortion and low resolution issues. Results on publicly available datasets show that our method outperforms many classic image blending algorithms on various performance metrics such as PSNR and SSIM.