 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunt Instead of Wait: Evaluating Deep Data Research on Large Language Models
Feb 02, 2026The agency expected of Agentic Large Language Models goes beyond answering correctly, requiring autonomy to set goals and decide what to explore. We term this investigatory intelligence, distinguishing it from executional intelligence, which merely completes assigned tasks. Data Science provides a natural testbed, as real-world analysis starts from raw data rather than explicit queries, yet few benchmarks focus on it. To address this, we introduce Deep Data Research (DDR), an open-ended task where LLMs autonomously extract key insights from databases, and DDR-Bench, a large-scale, checklist-based benchmark that enables verifiable evaluation. Results show that while frontier models display emerging agency, long-horizon exploration remains challenging. Our analysis highlights that effective investigatory intelligence depends not only on agent scaffolding or merely scaling, but also on intrinsic strategies of agentic models.
Is Pure Exploitation Sufficient in Exogenous MDPs with Linear Function Approximation?
Jan 28, 2026Exogenous MDPs (Exo-MDPs) capture sequential decision-making where uncertainty comes solely from exogenous inputs that evolve independently of the learner's actions. This structure is especially common in operations research applications such as inventory control, energy storage, and resource allocation, where exogenous randomness (e.g., demand, arrivals, or prices) drives system behavior. Despite decades of empirical evidence that greedy, exploitation-only methods work remarkably well in these settings, theory has lagged behind: all existing regret guarantees for Exo-MDPs rely on explicit exploration or tabular assumptions. We show that exploration is unnecessary. We propose Pure Exploitation Learning (PEL) and prove the first general finite-sample regret bounds for exploitation-only algorithms in Exo-MDPs. In the tabular case, PEL achieves $\widetilde{O}(H^2|Ξ|\sqrt{K})$. For large, continuous endogenous state spaces, we introduce LSVI-PE, a simple linear-approximation method whose regret is polynomial in the feature dimension, exogenous state space, and horizon, independent of the endogenous state and action spaces. Our analysis introduces two new tools: counterfactual trajectories and Bellman-closed feature transport, which together allow greedy policies to have accurate value estimates without optimism. Experiments on synthetic and resource-management tasks show that PEL consistently outperforming baselines. Overall, our results overturn the conventional wisdom that exploration is required, demonstrating that in Exo-MDPs, pure exploitation is enough.
Social World Model-Augmented Mechanism Design Policy Learning
Oct 22, 2025Designing adaptive mechanisms to align individual and collective interests remains a central challenge in artificial social intelligence. Existing methods often struggle with modeling heterogeneous agents possessing persistent latent traits (e.g., skills, preferences) and dealing with complex multi-agent system dynamics. These challenges are compounded by the critical need for high sample efficiency due to costly real-world interactions. World Models, by learning to predict environmental dynamics, offer a promising pathway to enhance mechanism design in heterogeneous and complex systems. In this paper, we introduce a novel method named SWM-AP (Social World Model-Augmented Mechanism Design Policy Learning), which learns a social world model hierarchically modeling agents' behavior to enhance mechanism design. Specifically, the social world model infers agents' traits from their interaction trajectories and learns a trait-based model to predict agents' responses to the deployed mechanisms. The mechanism design policy collects extensive training trajectories by interacting with the social world model, while concurrently inferring agents' traits online during real-world interactions to further boost policy learning efficiency. Experiments in diverse settings (tax policy design, team coordination, and facility location) demonstrate that SWM-AP outperforms established model-based and model-free RL baselines in cumulative rewards and sample efficiency.
Intrinsic Memory Agents: Heterogeneous Multi-Agent LLM Systems through Structured Contextual Memory
Aug 12, 2025Multi-agent systems built on Large Language Models (LLMs) show exceptional promise for complex collaborative problem-solving, yet they face fundamental challenges stemming from context window limitations that impair memory consistency, role adherence, and procedural integrity. This paper introduces Intrinsic Memory Agents, a novel framework that addresses these limitations through structured agent-specific memories that evolve intrinsically with agent outputs. Specifically, our method maintains role-aligned memory templates that preserve specialized perspectives while focusing on task-relevant information. We benchmark our approach on the PDDL dataset, comparing its performance to existing state-of-the-art multi-agentic memory approaches and showing an improvement of 38.6\% with the highest token efficiency. An additional evaluation is performed on a complex data pipeline design task, we demonstrate that our approach produces higher quality designs when comparing 5 metrics: scalability, reliability, usability, cost-effectiveness and documentation with additional qualitative evidence of the improvements. Our findings suggest that addressing memory limitations through structured, intrinsic approaches can improve the capabilities of multi-agent LLM systems on structured planning tasks.
NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning
May 21, 2025Recent advances such as DeepSeek R1-Zero highlight the effectiveness of incentive training, a reinforcement learning paradigm that computes rewards solely based on the final answer part of a language model's output, thereby encouraging the generation of intermediate reasoning steps. However, these methods fundamentally rely on external verifiers, which limits their applicability to domains like mathematics and coding where such verifiers are readily available. Although reward models can serve as verifiers, they require high-quality annotated data and are costly to train. In this work, we propose NOVER, NO-VERifier Reinforcement Learning, a general reinforcement learning framework that requires only standard supervised fine-tuning data with no need for an external verifier. NOVER enables incentive training across a wide range of text-to-text tasks and outperforms the model of the same size distilled from large reasoning models such as DeepSeek R1 671B by 7.7 percent. Moreover, the flexibility of NOVER enables new possibilities for optimizing large language models, such as inverse incentive training.
Automatic Dataset Generation for Knowledge Intensive Question Answering Tasks
May 20, 2025A question-answering (QA) system is to search suitable answers within a knowledge base. Current QA systems struggle with queries requiring complex reasoning or real-time knowledge integration. They are often supplemented with retrieval techniques on a data source such as Retrieval-Augmented Generation (RAG). However, RAG continues to face challenges in handling complex reasoning and logical connections between multiple sources of information. A novel approach for enhancing Large Language Models (LLMs) in knowledge-intensive QA tasks is presented through the automated generation of context-based QA pairs. This methodology leverages LLMs to create fine-tuning data, reducing reliance on human labelling and improving model comprehension and reasoning capabilities. The proposed system includes an automated QA generator and a model fine-tuner, evaluated using perplexity, ROUGE, BLEU, and BERTScore. Comprehensive experiments demonstrate improvements in logical coherence and factual accuracy, with implications for developing adaptable Artificial Intelligence (AI) systems. Mistral-7b-v0.3 outperforms Llama-3-8b with BERT F1, BLEU, and ROUGE scores 0.858, 0.172, and 0.260 of for the LLM generated QA pairs compared to scores of 0.836, 0.083, and 0.139 for the human annotated QA pairs.
Post-Incorporating Code Structural Knowledge into LLMs via In-Context Learning for Code Translation
Mar 28, 2025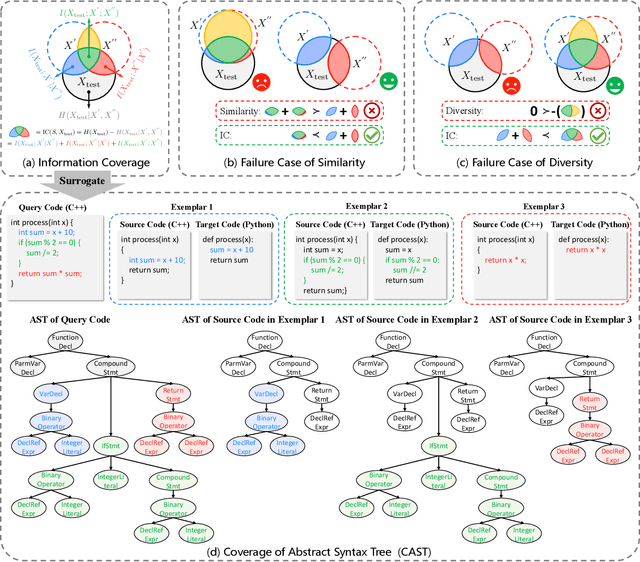
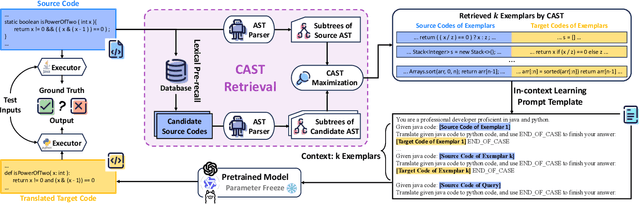
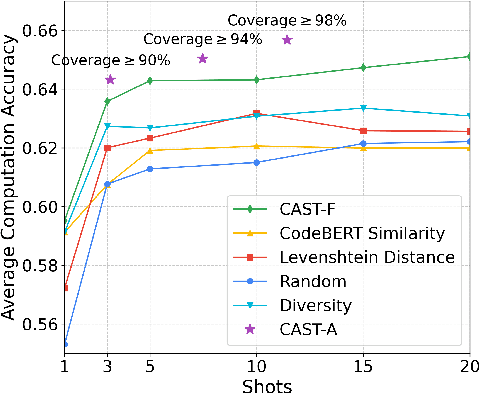
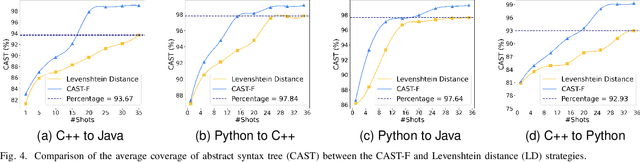
Code translation migrates codebases across programming languages. Recently, large language models (LLMs) have achieved significant advancements in software mining. However, handling the syntactic structure of source code remains a challenge. Classic syntax-aware methods depend on intricate model architectures and loss functions, rendering their integration into LLM training resource-intensive. This paper employs in-context learning (ICL), which directly integrates task exemplars into the input context, to post-incorporate code structural knowledge into pre-trained LLMs. We revisit exemplar selection in ICL from an information-theoretic perspective, proposing that list-wise selection based on information coverage is more precise and general objective than traditional methods based on combining similarity and diversity. To address the challenges of quantifying information coverage, we introduce a surrogate measure, Coverage of Abstract Syntax Tree (CAST). Furthermore, we formulate the NP-hard CAST maximization for exemplar selection and prove that it is a standard submodular maximization problem. Therefore, we propose a greedy algorithm for CAST submodular maximization, which theoretically guarantees a (1-1/e)-approximate solution in polynomial time complexity. Our method is the first training-free and model-agnostic approach to post-incorporate code structural knowledge into existing LLMs at test time. Experimental results show that our method significantly improves LLMs performance and reveals two meaningful insights: 1) Code structural knowledge can be effectively post-incorporated into pre-trained LLMs during inference, despite being overlooked during training; 2) Scaling up model size or training data does not lead to the emergence of code structural knowledge, underscoring the necessity of explicitly considering code syntactic structure.
SocialJax: An Evaluation Suite for Multi-agent Reinforcement Learning in Sequential Social Dilemmas
Mar 18, 2025Social dilemmas pose a significant challenge in the field of multi-agent reinforcement learning (MARL). Melting Pot is an extensive framework designed to evaluate social dilemma environments, providing an evaluation protocol that measures generalization to new social partners across various test scenarios. However, running reinforcement learning algorithms in the official Melting Pot environments demands substantial computational resources. In this paper, we introduce SocialJax, a suite of sequential social dilemma environments implemented in JAX. JAX is a high-performance numerical computing library for Python that enables significant improvements in the operational efficiency of SocialJax on GPUs and TPUs. Our experiments demonstrate that the training pipeline of SocialJax achieves a 50\texttimes{} speedup in real-time performance compared to Melting Pot's RLlib baselines. Additionally, we validate the effectiveness of baseline algorithms within the SocialJax environments. Finally, we use Schelling diagrams to verify the social dilemma properties of these environments, ensuring they accurately capture the dynamics of social dilemmas.
GRU: Mitigating the Trade-off between Unlearning and Retention for Large Language Models
Mar 12, 2025Large language model (LLM) unlearning has demonstrated its essential role in removing privacy and copyright-related responses, crucial for their legal and safe applications. However, the pursuit of complete unlearning often comes with substantial costs due to its compromises in their general functionality, leading to a notorious trade-off between unlearning and retention. In examining the update process for unlearning dynamically, we find gradients hold essential information for revealing this trade-off. In particular, we look at the varying relationship between retention performance and directional disparities between gradients during unlearning. It motivates the sculpting of an update mechanism derived from gradients from two sources, i.e., harmful for retention and useful for unlearning. Accordingly, we propose Gradient Rectified Unlearning (GRU), an enhanced unlearning framework controlling the updating gradients in a geometry-focused and optimization-driven manner such that their side impacts on other, unrelated responses can be minimized. Specifically, GRU derives a closed-form solution to project the unlearning gradient onto the orthogonal space of that gradient harmful for retention, ensuring minimal deviation from its original direction under the condition that overall performance is retained. Comprehensive experiments are conducted to demonstrate that GRU, as a general framework, is straightforward to implement and efficiently enhances a range of baseline methods through its adaptable and compatible characteristics. Additionally, experimental results show its broad effectiveness across a diverse set of benchmarks for LLM unlearning.
M3HF: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
Mar 06, 2025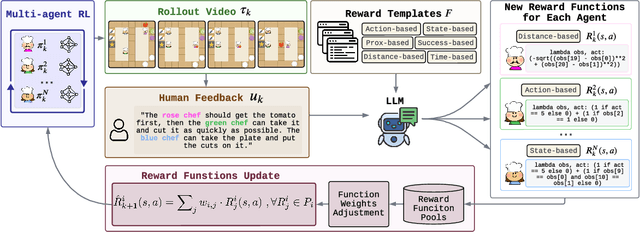
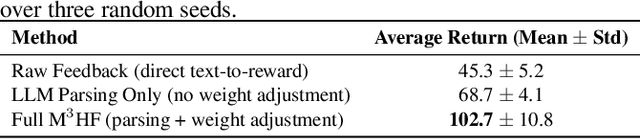
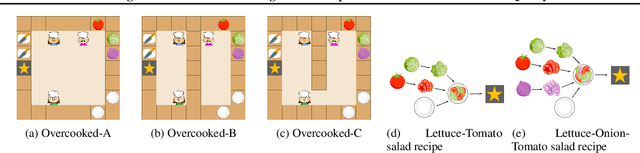
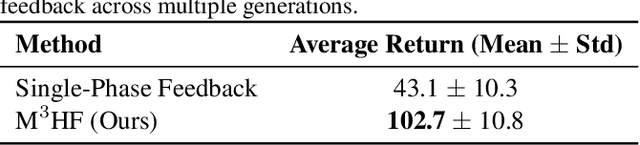
Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality (M3HF), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, M3HF leverages both expert and non-expert feedback to continuously refine agents' policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weight by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that M3HF significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.