 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRADE: Probing Knowledge Gaps in LLMs through Gradient Subspace Dynamics
Apr 03, 2026Detecting whether a model's internal knowledge is sufficient to correctly answer a given question is a fundamental challenge in deploying responsible LLMs. In addition to verbalising the confidence by LLM self-report, more recent methods explore the model internals, such as the hidden states of the response tokens to capture how much knowledge is activated. We argue that such activated knowledge may not align with what the query requires, e.g., capturing the stylistic and length-related features that are uninformative for answering the query. To fill the gap, we propose GRADE (Gradient Dynamics for knowledge gap detection), which quantifies the knowledge gap via the cross-layer rank ratio of the gradient to that of the corresponding hidden state subspace. This is motivated by the property of gradients as estimators of the required knowledge updates for a given target. We validate \modelname{} on six benchmarks, demonstrating its effectiveness and robustness to input perturbations. In addition, we present a case study showing how the gradient chain can generate interpretable explanations of knowledge gaps for long-form answers.
Stop the Flip-Flop: Context-Preserving Verification for Fast Revocable Diffusion Decoding
Feb 05, 2026Parallel diffusion decoding can accelerate diffusion language model inference by unmasking multiple tokens per step, but aggressive parallelism often harms quality. Revocable decoding mitigates this by rechecking earlier tokens, yet we observe that existing verification schemes frequently trigger flip-flop oscillations, where tokens are remasked and later restored unchanged. This behaviour slows inference in two ways: remasking verified positions weakens the conditioning context for parallel drafting, and repeated remask cycles consume the revision budget with little net progress. We propose COVER (Cache Override Verification for Efficient Revision), which performs leave-one-out verification and stable drafting within a single forward pass. COVER constructs two attention views via KV cache override: selected seeds are masked for verification, while their cached key value states are injected for all other queries to preserve contextual information, with a closed form diagonal correction preventing self leakage at the seed positions. COVER further prioritises seeds using a stability aware score that balances uncertainty, downstream influence, and cache drift, and it adapts the number of verified seeds per step. Across benchmarks, COVER markedly reduces unnecessary revisions and yields faster decoding while preserving output quality.
Context Compression via Explicit Information Transmission
Feb 03, 2026Long-context inference with Large Language Models (LLMs) is costly due to quadratic attention and growing key-value caches, motivating context compression. In this work, we study soft context compression, where a long context is condensed into a small set of continuous representations. Existing methods typically re-purpose the LLM itself as a trainable compressor, relying on layer-by-layer self-attention to iteratively aggregate information. We argue that this paradigm suffers from two structural limitations: (i) progressive representation overwriting across layers (ii) uncoordinated allocation of compression capacity across tokens. We propose ComprExIT (Context Compression via Explicit Information Transmission), a lightweight framework that formulates soft compression into a new paradigm: explicit information transmission over frozen LLM hidden states. This decouples compression from the model's internal self-attention dynamics. ComprExIT performs (i) depth-wise transmission to selectively transmit multi-layer information into token anchors, mitigating progressive overwriting, and (ii) width-wise transmission to aggregate anchors into a small number of slots via a globally optimized transmission plan, ensuring coordinated allocation of information. Across six question-answering benchmarks, ComprExIT consistently outperforms state-of-the-art context compression methods while introducing only ~1% additional parameters, demonstrating that explicit and coordinated information transmission enables more effective and robust long-context compression.
Beyond RAG for Agent Memory: Retrieval by Decoupling and Aggregation
Feb 02, 2026Agent memory systems often adopt the standard Retrieval-Augmented Generation (RAG) pipeline, yet its underlying assumptions differ in this setting. RAG targets large, heterogeneous corpora where retrieved passages are diverse, whereas agent memory is a bounded, coherent dialogue stream with highly correlated spans that are often duplicates. Under this shift, fixed top-$k$ similarity retrieval tends to return redundant context, and post-hoc pruning can delete temporally linked prerequisites needed for correct reasoning. We argue retrieval should move beyond similarity matching and instead operate over latent components, following decoupling to aggregation: disentangle memories into semantic components, organise them into a hierarchy, and use this structure to drive retrieval. We propose xMemory, which builds a hierarchy of intact units and maintains a searchable yet faithful high-level node organisation via a sparsity--semantics objective that guides memory split and merge. At inference, xMemory retrieves top-down, selecting a compact, diverse set of themes and semantics for multi-fact queries, and expanding to episodes and raw messages only when it reduces the reader's uncertainty. Experiments on LoCoMo and PerLTQA across the three latest LLMs show consistent gains in answer quality and token efficiency.
Not All Code Is Equal: A Data-Centric Study of Code Complexity and LLM Reasoning
Jan 29, 2026Large Language Models (LLMs) increasingly exhibit strong reasoning abilities, often attributed to their capacity to generate chain-of-thought-style intermediate reasoning. Recent work suggests that exposure to code can further enhance these skills, but existing studies largely treat code as a generic training signal, leaving open the question of which properties of code actually contribute to improved reasoning. To address this gap, we study the structural complexity of code, which captures control flow and compositional structure that may shape how models internalise multi-step reasoning during fine-tuning. We examine two complementary settings: solution-driven complexity, where complexity varies across multiple solutions to the same problem, and problem-driven complexity, where complexity reflects variation in the underlying tasks. Using cyclomatic complexity and logical lines of code to construct controlled fine-tuning datasets, we evaluate a range of open-weight LLMs on diverse reasoning benchmarks. Our findings show that although code can improve reasoning, structural properties strongly determine its usefulness. In 83% of experiments, restricting fine-tuning data to a specific structural complexity range outperforms training on structurally diverse code, pointing to a data-centric path for improving reasoning beyond scaling.
AutoMonitor-Bench: Evaluating the Reliability of LLM-Based Misbehavior Monitor
Jan 09, 2026We introduce AutoMonitor-Bench, the first benchmark designed to systematically evaluate the reliability of LLM-based misbehavior monitors across diverse tasks and failure modes. AutoMonitor-Bench consists of 3,010 carefully annotated test samples spanning question answering, code generation, and reasoning, with paired misbehavior and benign instances. We evaluate monitors using two complementary metrics: Miss Rate (MR) and False Alarm Rate (FAR), capturing failures to detect misbehavior and oversensitivity to benign behavior, respectively. Evaluating 12 proprietary and 10 open-source LLMs, we observe substantial variability in monitoring performance and a consistent trade-off between MR and FAR, revealing an inherent safety-utility tension. To further explore the limits of monitor reliability, we construct a large-scale training corpus of 153,581 samples and fine-tune Qwen3-4B-Instruction to investigate whether training on known, relatively easy-to-construct misbehavior datasets improves monitoring performance on unseen and more implicit misbehaviors. Our results highlight the challenges of reliable, scalable misbehavior monitoring and motivate future work on task-aware designing and training strategies for LLM-based monitors.
Soft Reasoning: Navigating Solution Spaces in Large Language Models through Controlled Embedding Exploration
May 30, 2025Large Language Models (LLMs) struggle with complex reasoning due to limited diversity and inefficient search. We propose Soft Reasoning, an embedding-based search framework that optimises the embedding of the first token to guide generation. It combines (1) embedding perturbation for controlled exploration and (2) Bayesian optimisation to refine embeddings via a verifier-guided objective, balancing exploration and exploitation. This approach improves reasoning accuracy and coherence while avoiding reliance on heuristic search. Experiments demonstrate superior correctness with minimal computation, making it a scalable, model-agnostic solution.
SciReplicate-Bench: Benchmarking LLMs in Agent-driven Algorithmic Reproduction from Research Papers
Mar 31, 2025This study evaluates large language models (LLMs) in generating code from algorithm descriptions from recent NLP papers. The task requires two key competencies: (1) algorithm comprehension: synthesizing information from papers and academic literature to understand implementation logic, and (2) coding expertise: identifying dependencies and correctly implementing necessary APIs. To facilitate rigorous evaluation, we introduce SciReplicate-Bench, a benchmark of 100 tasks from 36 NLP papers published in 2024, featuring detailed annotations and comprehensive test cases. Building on SciReplicate-Bench, we propose Sci-Reproducer, a multi-agent framework consisting of a Paper Agent that interprets algorithmic concepts from literature and a Code Agent that retrieves dependencies from repositories and implement solutions. To assess algorithm understanding, we introduce reasoning graph accuracy, which quantifies similarity between generated and reference reasoning graphs derived from code comments and structure. For evaluating implementation quality, we employ execution accuracy, CodeBLEU, and repository dependency/API recall metrics. In our experiments, we evaluate various powerful Non-Reasoning LLMs and Reasoning LLMs as foundational models. The best-performing LLM using Sci-Reproducer achieves only 39% execution accuracy, highlighting the benchmark's difficulty.Our analysis identifies missing or inconsistent algorithm descriptions as key barriers to successful reproduction. We will open-source our benchmark, and code at https://github.com/xyzCS/SciReplicate-Bench.
Beyond Prompting: An Efficient Embedding Framework for Open-Domain Question Answering
Mar 03, 2025



Large language models have recently pushed open domain question answering (ODQA) to new frontiers. However, prevailing retriever-reader pipelines often depend on multiple rounds of prompt level instructions, leading to high computational overhead, instability, and suboptimal retrieval coverage. In this paper, we propose EmbQA, an embedding-level framework that alleviates these shortcomings by enhancing both the retriever and the reader. Specifically, we refine query representations via lightweight linear layers under an unsupervised contrastive learning objective, thereby reordering retrieved passages to highlight those most likely to contain correct answers. Additionally, we introduce an exploratory embedding that broadens the model's latent semantic space to diversify candidate generation and employs an entropy-based selection mechanism to choose the most confident answer automatically. Extensive experiments across three open-source LLMs, three retrieval methods, and four ODQA benchmarks demonstrate that EmbQA substantially outperforms recent baselines in both accuracy and efficiency.
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Feb 28, 2025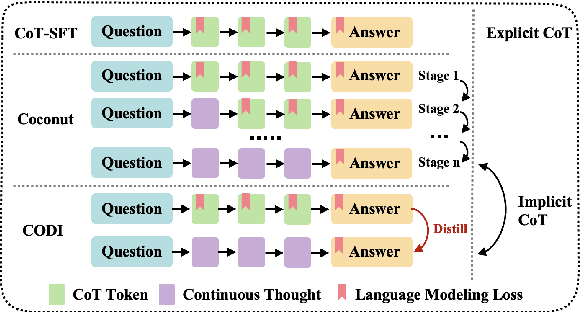
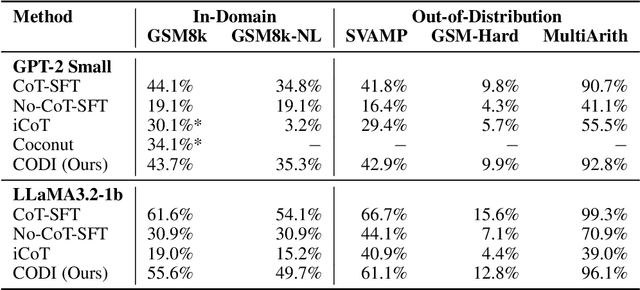
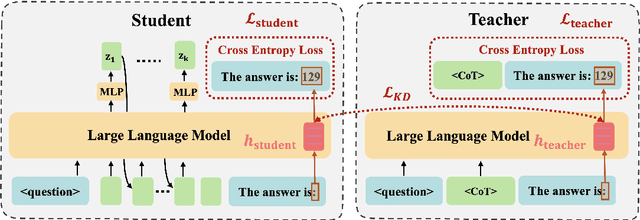
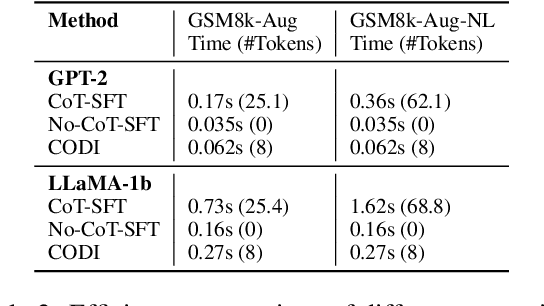
Chain-of-Thought (CoT) enhances Large Language Models (LLMs) by enabling step-by-step reasoning in natural language. However, the language space may be suboptimal for reasoning. While implicit CoT methods attempt to enable reasoning without explicit CoT tokens, they have consistently lagged behind explicit CoT method in task performance. We propose CODI (Continuous Chain-of-Thought via Self-Distillation), a novel framework that distills CoT into a continuous space, where a shared model acts as both teacher and student, jointly learning explicit and implicit CoT while aligning their hidden activation on the token generating the final answer. CODI is the first implicit CoT method to match explicit CoT's performance on GSM8k while achieving 3.1x compression, surpassing the previous state-of-the-art by 28.2% in accuracy. Furthermore, CODI demonstrates scalability, robustness, and generalizability to more complex CoT datasets. Additionally, CODI retains interpretability by decoding its continuous thoughts, making its reasoning process transparent. Our findings establish implicit CoT as not only a more efficient but a powerful alternative to explicit CoT.