 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncourage or Inhibit Monosemanticity? Revisit Monosemanticity from a Feature Decorrelation Perspective
Paper and Code
Jun 25, 2024
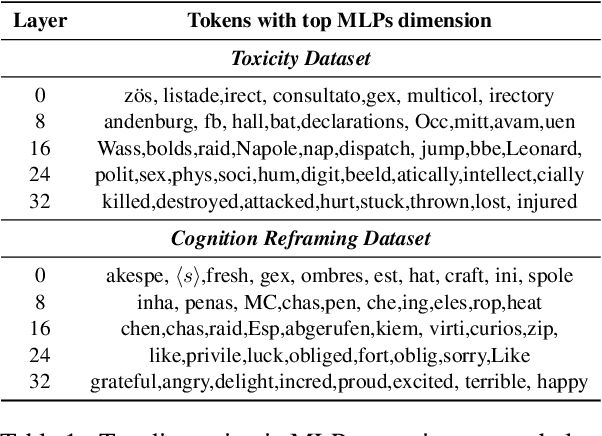
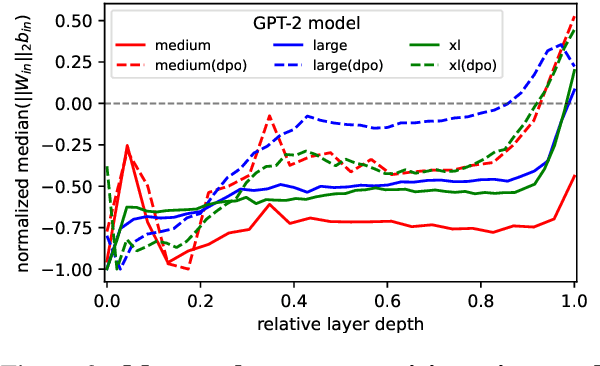

To better interpret the intrinsic mechanism of large language models (LLMs), recent studies focus on monosemanticity on its basic units. A monosemantic neuron is dedicated to a single and specific concept, which forms a one-to-one correlation between neurons and concepts. Despite extensive research in monosemanticity probing, it remains unclear whether monosemanticity is beneficial or harmful to model capacity. To explore this question, we revisit monosemanticity from the feature decorrelation perspective and advocate for its encouragement. We experimentally observe that the current conclusion by wang2024learning, which suggests that decreasing monosemanticity enhances model performance, does not hold when the model changes. Instead, we demonstrate that monosemanticity consistently exhibits a positive correlation with model capacity, in the preference alignment process. Consequently, we apply feature correlation as a proxy for monosemanticity and incorporate a feature decorrelation regularizer into the dynamic preference optimization process. The experiments show that our method not only enhances representation diversity and activation sparsity but also improves preference alignment performance.