 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Synthetic Image Attribution: Alignment and Disentanglement
Jan 30, 2026As the quality of synthetic images improves, identifying the underlying concepts of model-generated images is becoming increasingly crucial for copyright protection and ensuring model transparency. Existing methods achieve this attribution goal by training models using annotated pairs of synthetic images and their original training sources. However, obtaining such paired supervision is challenging, as it requires either well-designed synthetic concepts or precise annotations from millions of training sources. To eliminate the need for costly paired annotations, in this paper, we explore the possibility of unsupervised synthetic image attribution. We propose a simple yet effective unsupervised method called Alignment and Disentanglement. Specifically, we begin by performing basic concept alignment using contrastive self-supervised learning. Next, we enhance the model's attribution ability by promoting representation disentanglement with the Infomax loss. This approach is motivated by an interesting observation: contrastive self-supervised models, such as MoCo and DINO, inherently exhibit the ability to perform simple cross-domain alignment. By formulating this observation as a theoretical assumption on cross-covariance, we provide a theoretical explanation of how alignment and disentanglement can approximate the concept-matching process through a decomposition of the canonical correlation analysis objective. On the real-world benchmarks, AbC, we show that our unsupervised method surprisingly outperforms the supervised methods. As a starting point, we expect our intuitive insights and experimental findings to provide a fresh perspective on this challenging task.
Learning by Analogy: A Causal Framework for Composition Generalization
Dec 11, 2025Compositional generalization -- the ability to understand and generate novel combinations of learned concepts -- enables models to extend their capabilities beyond limited experiences. While effective, the data structures and principles that enable this crucial capability remain poorly understood. We propose that compositional generalization fundamentally requires decomposing high-level concepts into basic, low-level concepts that can be recombined across similar contexts, similar to how humans draw analogies between concepts. For example, someone who has never seen a peacock eating rice can envision this scene by relating it to their previous observations of a chicken eating rice. In this work, we formalize these intuitive processes using principles of causal modularity and minimal changes. We introduce a hierarchical data-generating process that naturally encodes different levels of concepts and their interaction mechanisms. Theoretically, we demonstrate that this approach enables compositional generalization supporting complex relations between composed concepts, advancing beyond prior work that assumes simpler interactions like additive effects. Critically, we also prove that this latent hierarchical structure is provably recoverable (identifiable) from observable data like text-image pairs, a necessary step for learning such a generative process. To validate our theory, we apply insights from our theoretical framework and achieve significant improvements on benchmark datasets.
Beyond the Black Box: Identifiable Interpretation and Control in Generative Models via Causal Minimality
Dec 11, 2025Deep generative models, while revolutionizing fields like image and text generation, largely operate as opaque black boxes, hindering human understanding, control, and alignment. While methods like sparse autoencoders (SAEs) show remarkable empirical success, they often lack theoretical guarantees, risking subjective insights. Our primary objective is to establish a principled foundation for interpretable generative models. We demonstrate that the principle of causal minimality -- favoring the simplest causal explanation -- can endow the latent representations of diffusion vision and autoregressive language models with clear causal interpretation and robust, component-wise identifiable control. We introduce a novel theoretical framework for hierarchical selection models, where higher-level concepts emerge from the constrained composition of lower-level variables, better capturing the complex dependencies in data generation. Under theoretically derived minimality conditions (manifesting as sparsity or compression constraints), we show that learned representations can be equivalent to the true latent variables of the data-generating process. Empirically, applying these constraints to leading generative models allows us to extract their innate hierarchical concept graphs, offering fresh insights into their internal knowledge organization. Furthermore, these causally grounded concepts serve as levers for fine-grained model steering, paving the way for transparent, reliable systems.
MixAR: Mixture Autoregressive Image Generation
Nov 15, 2025Autoregressive (AR) approaches, which represent images as sequences of discrete tokens from a finite codebook, have achieved remarkable success in image generation. However, the quantization process and the limited codebook size inevitably discard fine-grained information, placing bottlenecks on fidelity. Motivated by this limitation, recent studies have explored autoregressive modeling in continuous latent spaces, which offers higher generation quality. Yet, unlike discrete tokens constrained by a fixed codebook, continuous representations lie in a vast and unstructured space, posing significant challenges for efficient autoregressive modeling. To address these challenges, we introduce MixAR, a novel framework that leverages mixture training paradigms to inject discrete tokens as prior guidance for continuous AR modeling. MixAR is a factorized formulation that leverages discrete tokens as prior guidance for continuous autoregressive prediction. We investigate several discrete-continuous mixture strategies, including self-attention (DC-SA), cross-attention (DC-CA), and a simple approach (DC-Mix) that replaces homogeneous mask tokens with informative discrete counterparts. Moreover, to bridge the gap between ground-truth training tokens and inference tokens produced by the pre-trained AR model, we propose Training-Inference Mixture (TI-Mix) to achieve consistent training and generation distributions. In our experiments, we demonstrate a favorable balance of the DC-Mix strategy between computational efficiency and generation fidelity, and consistent improvement of TI-Mix.
Step-Aware Policy Optimization for Reasoning in Diffusion Large Language Models
Oct 02, 2025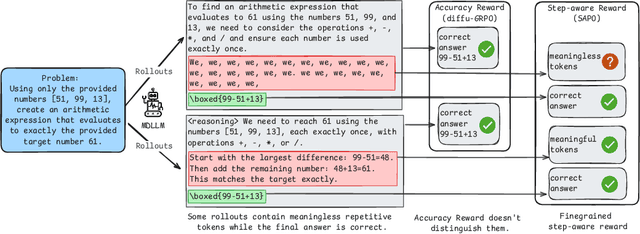
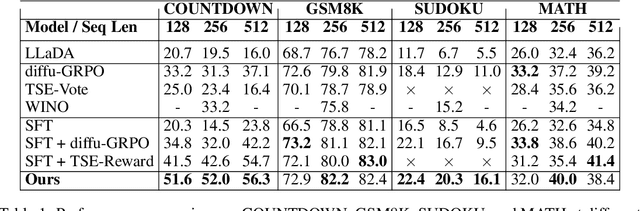
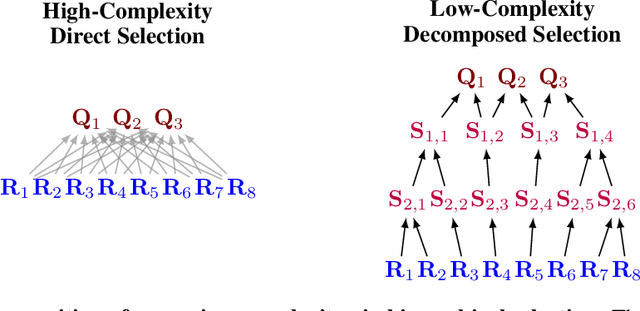
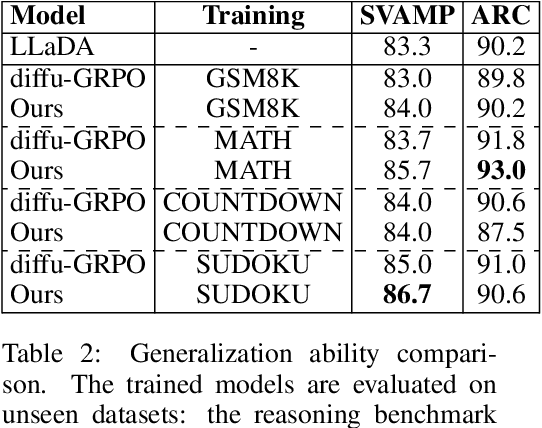
Diffusion language models (dLLMs) offer a promising, non-autoregressive paradigm for text generation, yet training them for complex reasoning remains a key challenge. Current reinforcement learning approaches often rely on sparse, outcome-based rewards, which can reinforce flawed reasoning paths that lead to coincidentally correct answers. We argue that this stems from a fundamental mismatch with the natural structure of reasoning. We first propose a theoretical framework that formalizes complex problem solving as a hierarchical selection process, where an intractable global constraint is decomposed into a series of simpler, localized logical steps. This framework provides a principled foundation for algorithm design, including theoretical insights into the identifiability of this latent reasoning structure. Motivated by this theory, we identify unstructured refinement -- a failure mode where a model's iterative steps do not contribute meaningfully to the solution -- as a core deficiency in existing methods. We then introduce Step-Aware Policy Optimization (SAPO), a novel RL algorithm that aligns the dLLM's denoising process with the latent reasoning hierarchy. By using a process-based reward function that encourages incremental progress, SAPO guides the model to learn structured, coherent reasoning paths. Our empirical results show that this principled approach significantly improves performance on challenging reasoning benchmarks and enhances the interpretability of the generation process.
SmartCLIP: Modular Vision-language Alignment with Identification Guarantees
Jul 29, 2025
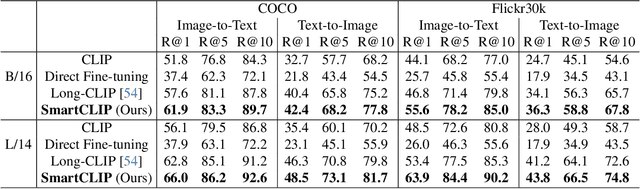
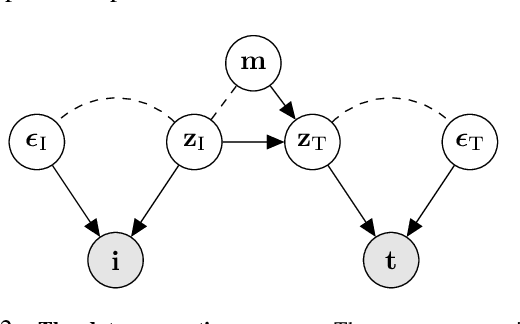
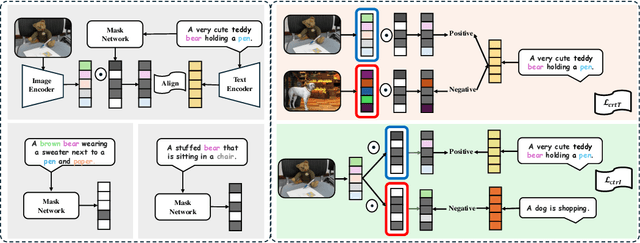
Contrastive Language-Image Pre-training (CLIP)~\citep{radford2021learning} has emerged as a pivotal model in computer vision and multimodal learning, achieving state-of-the-art performance at aligning visual and textual representations through contrastive learning. However, CLIP struggles with potential information misalignment in many image-text datasets and suffers from entangled representation. On the one hand, short captions for a single image in datasets like MSCOCO may describe disjoint regions in the image, leaving the model uncertain about which visual features to retain or disregard. On the other hand, directly aligning long captions with images can lead to the retention of entangled details, preventing the model from learning disentangled, atomic concepts -- ultimately limiting its generalization on certain downstream tasks involving short prompts. In this paper, we establish theoretical conditions that enable flexible alignment between textual and visual representations across varying levels of granularity. Specifically, our framework ensures that a model can not only \emph{preserve} cross-modal semantic information in its entirety but also \emph{disentangle} visual representations to capture fine-grained textual concepts. Building on this foundation, we introduce \ours, a novel approach that identifies and aligns the most relevant visual and textual representations in a modular manner. Superior performance across various tasks demonstrates its capability to handle information misalignment and supports our identification theory. The code is available at https://github.com/Mid-Push/SmartCLIP.
Should Bias Always be Eliminated? A Principled Framework to Use Data Bias for OOD Generation
Jul 22, 2025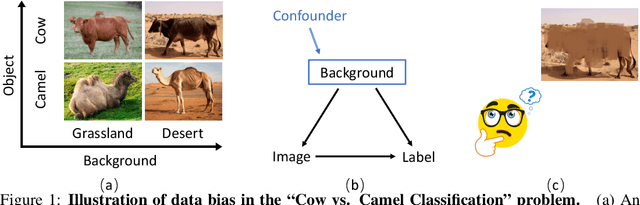
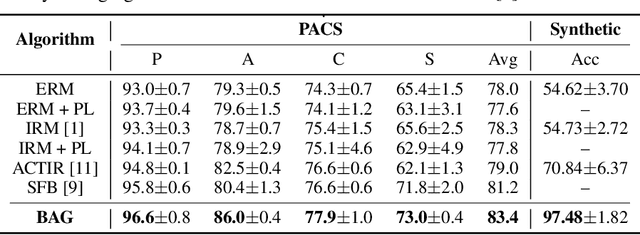
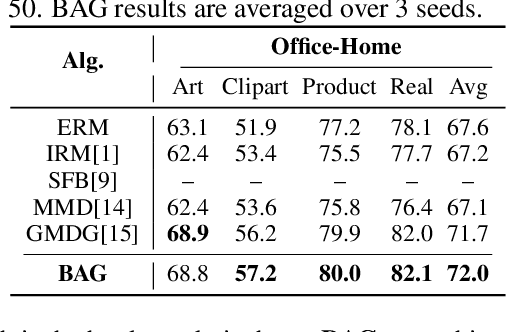
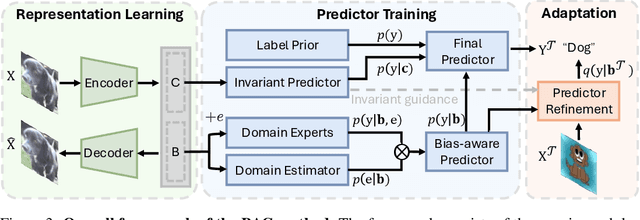
Most existing methods for adapting models to out-of-distribution (OOD) domains rely on invariant representation learning to eliminate the influence of biased features. However, should bias always be eliminated -- and if not, when should it be retained, and how can it be leveraged? To address these questions, we first present a theoretical analysis that explores the conditions under which biased features can be identified and effectively utilized. Building on this theoretical foundation, we introduce a novel framework that strategically leverages bias to complement invariant representations during inference. The framework comprises two key components that leverage bias in both direct and indirect ways: (1) using invariance as guidance to extract predictive ingredients from bias, and (2) exploiting identified bias to estimate the environmental condition and then use it to explore appropriate bias-aware predictors to alleviate environment gaps. We validate our approach through experiments on both synthetic datasets and standard domain generalization benchmarks. Results consistently demonstrate that our method outperforms existing approaches, underscoring its robustness and adaptability.
Reflection-Window Decoding: Text Generation with Selective Refinement
Feb 05, 2025



The autoregressive decoding for text generation in large language models (LLMs), while widely used, is inherently suboptimal due to the lack of a built-in mechanism to perform refinement and/or correction of the generated content. In this paper, we consider optimality in terms of the joint probability over the generated response, when jointly considering all tokens at the same time. We theoretically characterize the potential deviation of the autoregressively generated response from its globally optimal counterpart that is of the same length. Our analysis suggests that we need to be cautious when noticeable uncertainty arises during text generation, which may signal the sub-optimality of the generation history. To address the pitfall of autoregressive decoding for text generation, we propose an approach that incorporates a sliding reflection window and a pausing criterion, such that refinement and generation can be carried out interchangeably as the decoding proceeds. Our selective refinement framework strikes a balance between efficiency and optimality, and our extensive experimental results demonstrate the effectiveness of our approach.
Controllable Video Generation with Provable Disentanglement
Feb 04, 2025



Controllable video generation remains a significant challenge, despite recent advances in generating high-quality and consistent videos. Most existing methods for controlling video generation treat the video as a whole, neglecting intricate fine-grained spatiotemporal relationships, which limits both control precision and efficiency. In this paper, we propose Controllable Video Generative Adversarial Networks (CoVoGAN) to disentangle the video concepts, thus facilitating efficient and independent control over individual concepts. Specifically, following the minimal change principle, we first disentangle static and dynamic latent variables. We then leverage the sufficient change property to achieve component-wise identifiability of dynamic latent variables, enabling independent control over motion and identity. To establish the theoretical foundation, we provide a rigorous analysis demonstrating the identifiability of our approach. Building on these theoretical insights, we design a Temporal Transition Module to disentangle latent dynamics. To enforce the minimal change principle and sufficient change property, we minimize the dimensionality of latent dynamic variables and impose temporal conditional independence. To validate our approach, we integrate this module as a plug-in for GANs. Extensive qualitative and quantitative experiments on various video generation benchmarks demonstrate that our method significantly improves generation quality and controllability across diverse real-world scenarios.
Towards Understanding Extrapolation: a Causal Lens
Jan 15, 2025



Canonical work handling distribution shifts typically necessitates an entire target distribution that lands inside the training distribution. However, practical scenarios often involve only a handful of target samples, potentially lying outside the training support, which requires the capability of extrapolation. In this work, we aim to provide a theoretical understanding of when extrapolation is possible and offer principled methods to achieve it without requiring an on-support target distribution. To this end, we formulate the extrapolation problem with a latent-variable model that embodies the minimal change principle in causal mechanisms. Under this formulation, we cast the extrapolation problem into a latent-variable identification problem. We provide realistic conditions on shift properties and the estimation objectives that lead to identification even when only one off-support target sample is available, tackling the most challenging scenarios. Our theory reveals the intricate interplay between the underlying manifold's smoothness and the shift properties. We showcase how our theoretical results inform the design of practical adaptation algorithms. Through experiments on both synthetic and real-world data, we validate our theoretical findings and their practical implications.