 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality for Large Language Models
Oct 20, 2024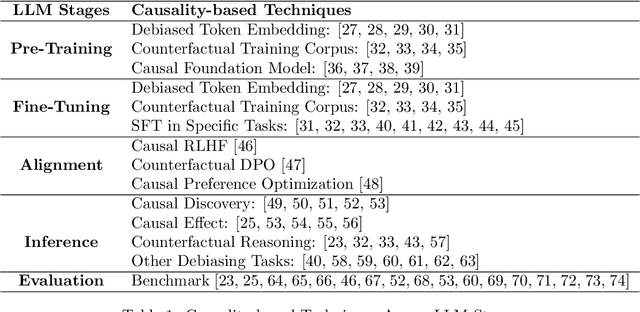
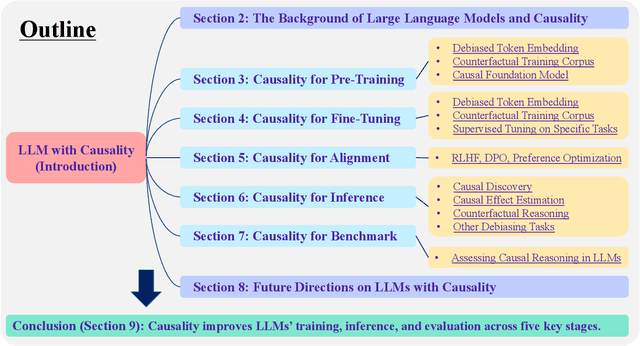
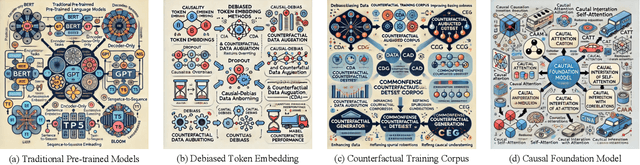
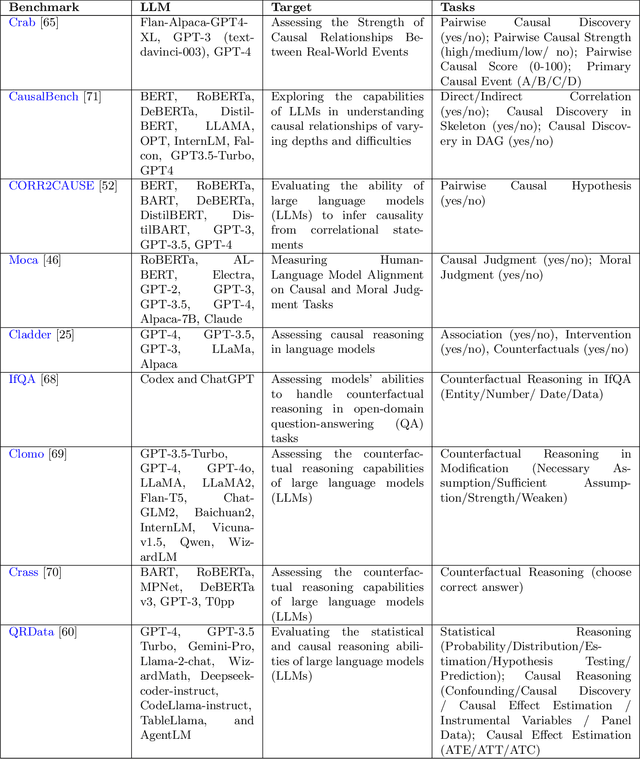
Recent breakthroughs in artificial intelligence have driven a paradigm shift, where large language models (LLMs) with billions or trillions of parameters are trained on vast datasets, achieving unprecedented success across a series of language tasks. However, despite these successes, LLMs still rely on probabilistic modeling, which often captures spurious correlations rooted in linguistic patterns and social stereotypes, rather than the true causal relationships between entities and events. This limitation renders LLMs vulnerable to issues such as demographic biases, social stereotypes, and LLM hallucinations. These challenges highlight the urgent need to integrate causality into LLMs, moving beyond correlation-driven paradigms to build more reliable and ethically aligned AI systems. While many existing surveys and studies focus on utilizing prompt engineering to activate LLMs for causal knowledge or developing benchmarks to assess their causal reasoning abilities, most of these efforts rely on human intervention to activate pre-trained models. How to embed causality into the training process of LLMs and build more general and intelligent models remains unexplored. Recent research highlights that LLMs function as causal parrots, capable of reciting causal knowledge without truly understanding or applying it. These prompt-based methods are still limited to human interventional improvements. This survey aims to address this gap by exploring how causality can enhance LLMs at every stage of their lifecycle-from token embedding learning and foundation model training to fine-tuning, alignment, inference, and evaluation-paving the way for more interpretable, reliable, and causally-informed models. Additionally, we further outline six promising future directions to advance LLM development, enhance their causal reasoning capabilities, and address the current limitations these models face.
IntOPE: Off-Policy Evaluation in the Presence of Interference
Aug 24, 2024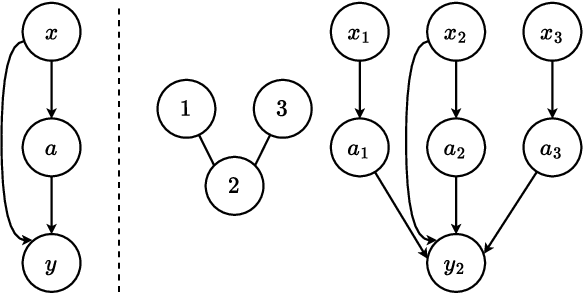
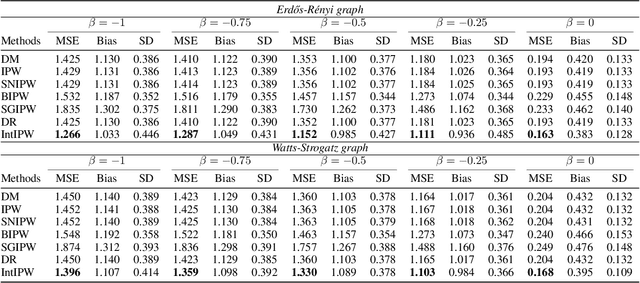
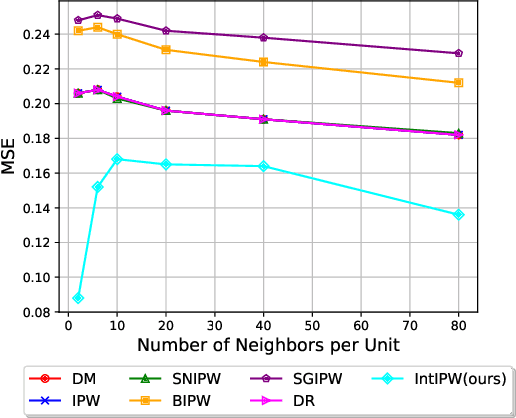
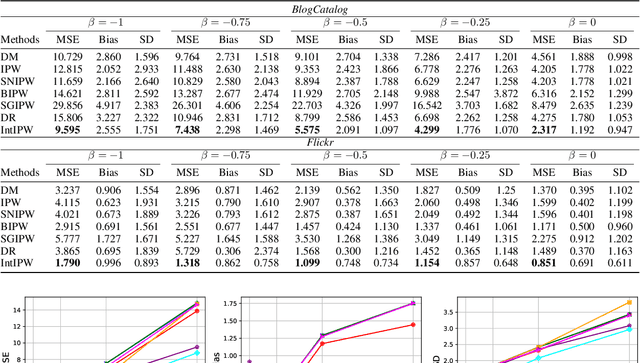
Off-Policy Evaluation (OPE) is employed to assess the potential impact of a hypothetical policy using logged contextual bandit feedback, which is crucial in areas such as personalized medicine and recommender systems, where online interactions are associated with significant risks and costs. Traditionally, OPE methods rely on the Stable Unit Treatment Value Assumption (SUTVA), which assumes that the reward for any given individual is unaffected by the actions of others. However, this assumption often fails in real-world scenarios due to the presence of interference, where an individual's reward is affected not just by their own actions but also by the actions of their peers. This realization reveals significant limitations of existing OPE methods in real-world applications. To address this limitation, we propose IntIPW, an IPW-style estimator that extends the Inverse Probability Weighting (IPW) framework by integrating marginalized importance weights to account for both individual actions and the influence of adjacent entities. Extensive experiments are conducted on both synthetic and real-world data to demonstrate the effectiveness of the proposed IntIPW method.
Causal Inference with Complex Treatments: A Survey
Jul 19, 2024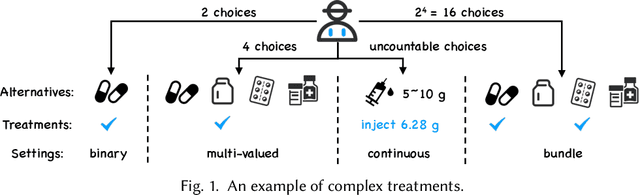
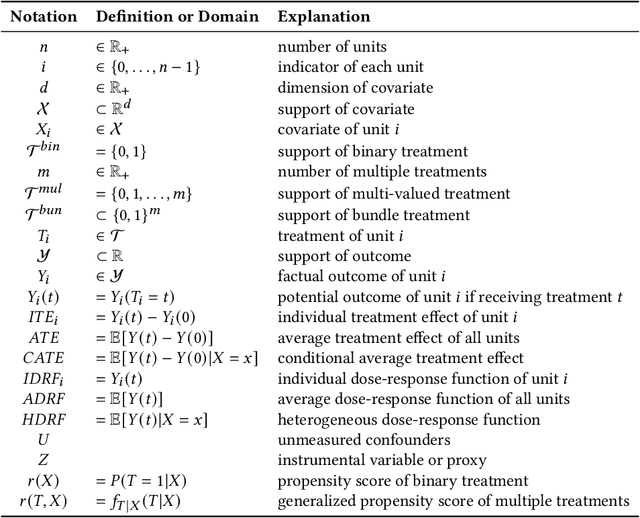
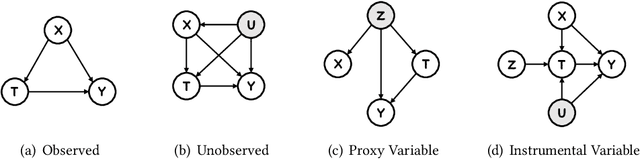

Causal inference plays an important role in explanatory analysis and decision making across various fields like statistics, marketing, health care, and education. Its main task is to estimate treatment effects and make intervention policies. Traditionally, most of the previous works typically focus on the binary treatment setting that there is only one treatment for a unit to adopt or not. However, in practice, the treatment can be much more complex, encompassing multi-valued, continuous, or bundle options. In this paper, we refer to these as complex treatments and systematically and comprehensively review the causal inference methods for addressing them. First, we formally revisit the problem definition, the basic assumptions, and their possible variations under specific conditions. Second, we sequentially review the related methods for multi-valued, continuous, and bundled treatment settings. In each situation, we tentatively divide the methods into two categories: those conforming to the unconfoundedness assumption and those violating it. Subsequently, we discuss the available datasets and open-source codes. Finally, we provide a brief summary of these works and suggest potential directions for future research.
Contrastive Balancing Representation Learning for Heterogeneous Dose-Response Curves Estimation
Mar 21, 2024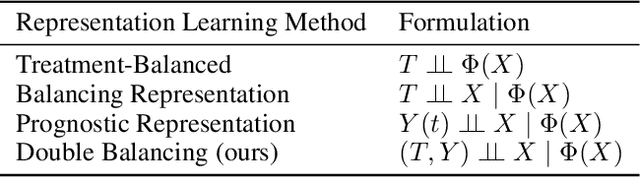
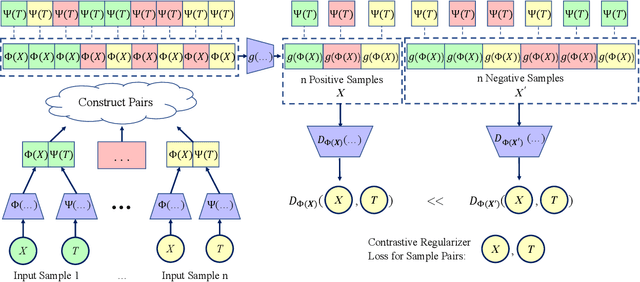
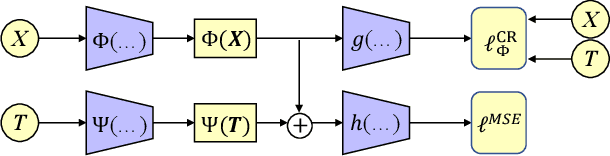
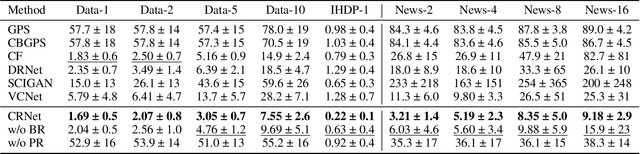
Estimating the individuals' potential response to varying treatment doses is crucial for decision-making in areas such as precision medicine and management science. Most recent studies predict counterfactual outcomes by learning a covariate representation that is independent of the treatment variable. However, such independence constraints neglect much of the covariate information that is useful for counterfactual prediction, especially when the treatment variables are continuous. To tackle the above issue, in this paper, we first theoretically demonstrate the importance of the balancing and prognostic representations for unbiased estimation of the heterogeneous dose-response curves, that is, the learned representations are constrained to satisfy the conditional independence between the covariates and both of the treatment variables and the potential responses. Based on this, we propose a novel Contrastive balancing Representation learning Network using a partial distance measure, called CRNet, for estimating the heterogeneous dose-response curves without losing the continuity of treatments. Extensive experiments are conducted on synthetic and real-world datasets demonstrating that our proposal significantly outperforms previous methods.