 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality for Large Language Models
Oct 20, 2024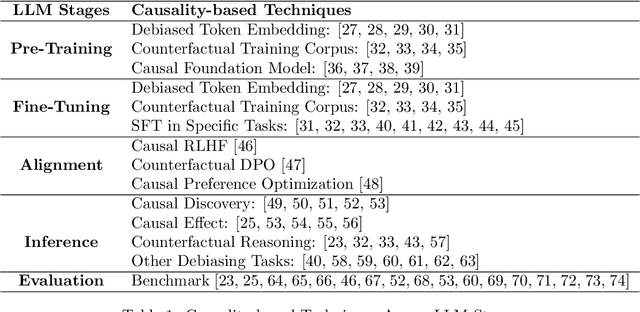
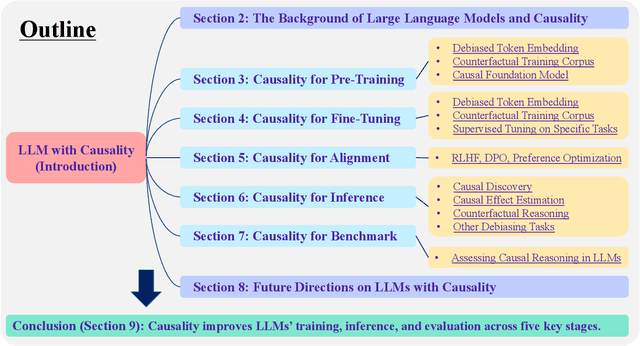
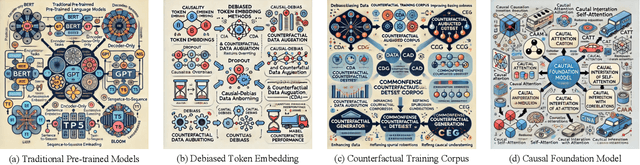
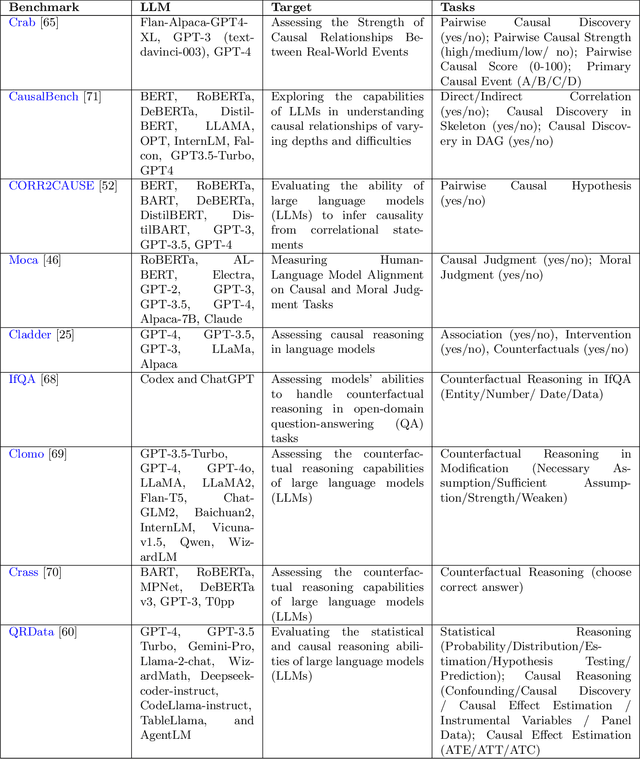
Recent breakthroughs in artificial intelligence have driven a paradigm shift, where large language models (LLMs) with billions or trillions of parameters are trained on vast datasets, achieving unprecedented success across a series of language tasks. However, despite these successes, LLMs still rely on probabilistic modeling, which often captures spurious correlations rooted in linguistic patterns and social stereotypes, rather than the true causal relationships between entities and events. This limitation renders LLMs vulnerable to issues such as demographic biases, social stereotypes, and LLM hallucinations. These challenges highlight the urgent need to integrate causality into LLMs, moving beyond correlation-driven paradigms to build more reliable and ethically aligned AI systems. While many existing surveys and studies focus on utilizing prompt engineering to activate LLMs for causal knowledge or developing benchmarks to assess their causal reasoning abilities, most of these efforts rely on human intervention to activate pre-trained models. How to embed causality into the training process of LLMs and build more general and intelligent models remains unexplored. Recent research highlights that LLMs function as causal parrots, capable of reciting causal knowledge without truly understanding or applying it. These prompt-based methods are still limited to human interventional improvements. This survey aims to address this gap by exploring how causality can enhance LLMs at every stage of their lifecycle-from token embedding learning and foundation model training to fine-tuning, alignment, inference, and evaluation-paving the way for more interpretable, reliable, and causally-informed models. Additionally, we further outline six promising future directions to advance LLM development, enhance their causal reasoning capabilities, and address the current limitations these models face.
Causal Agent based on Large Language Model
Aug 13, 2024Large language models (LLMs) have achieved significant success across various domains. However, the inherent complexity of causal problems and causal theory poses challenges in accurately describing them in natural language, making it difficult for LLMs to comprehend and use them effectively. Causal methods are not easily conveyed through natural language, which hinders LLMs' ability to apply them accurately. Additionally, causal datasets are typically tabular, while LLMs excel in handling natural language data, creating a structural mismatch that impedes effective reasoning with tabular data. This lack of causal reasoning capability limits the development of LLMs. To address these challenges, we have equipped the LLM with causal tools within an agent framework, named the Causal Agent, enabling it to tackle causal problems. The causal agent comprises tools, memory, and reasoning modules. In the tools module, the causal agent applies causal methods to align tabular data with natural language. In the reasoning module, the causal agent employs the ReAct framework to perform reasoning through multiple iterations with the tools. In the memory module, the causal agent maintains a dictionary instance where the keys are unique names and the values are causal graphs. To verify the causal ability of the causal agent, we established a benchmark consisting of four levels of causal problems: variable level, edge level, causal graph level, and causal effect level. We generated a test dataset of 1.3K using ChatGPT-3.5 for these four levels of issues and tested the causal agent on the datasets. Our methodology demonstrates remarkable efficacy on the four-level causal problems, with accuracy rates all above 80%. For further insights and implementation details, our code is accessible via the GitHub repository https://github.com/Kairong-Han/Causal_Agent.