 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Treatment Effect Estimation with Unmeasured Confounders
May 14, 2025This paper studies the cumulative causal effects of sequential treatments in the presence of unmeasured confounders. It is a critical issue in sequential decision-making scenarios where treatment decisions and outcomes dynamically evolve over time. Advanced causal methods apply transformer as a backbone to model such time sequences, which shows superiority in capturing long time dependence and periodic patterns via attention mechanism. However, even they control the observed confounding, these estimators still suffer from unmeasured confounders, which influence both treatment assignments and outcomes. How to adjust the latent confounding bias in sequential treatment effect estimation remains an open challenge. Therefore, we propose a novel Decomposing Sequential Instrumental Variable framework for CounterFactual Regression (DSIV-CFR), relying on a common negative control assumption. Specifically, an instrumental variable (IV) is a special negative control exposure, while the previous outcome serves as a negative control outcome. This allows us to recover the IVs latent in observation variables and estimate sequential treatment effects via a generalized moment condition. We conducted experiments on 4 datasets and achieved significant performance in one- and multi-step prediction, supported by which we can identify optimal treatments for dynamic systems.
Causality for Large Language Models
Oct 20, 2024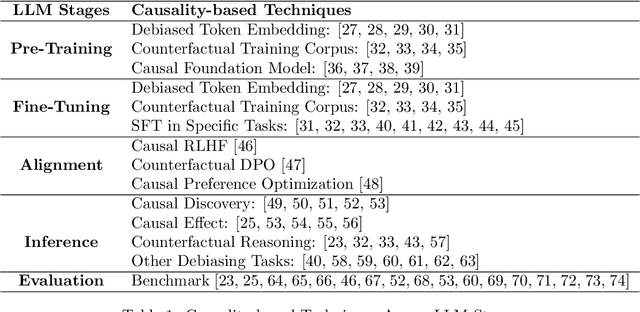
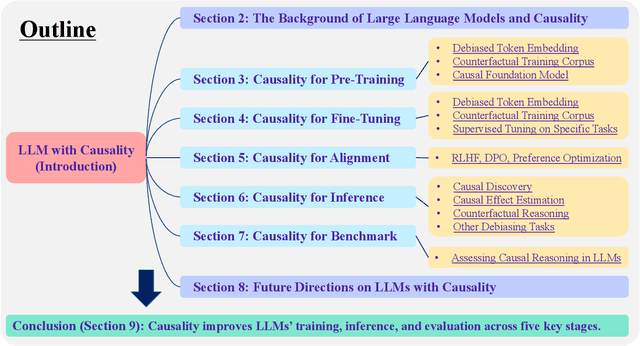
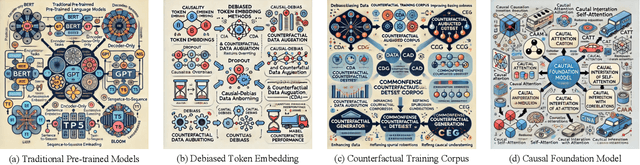
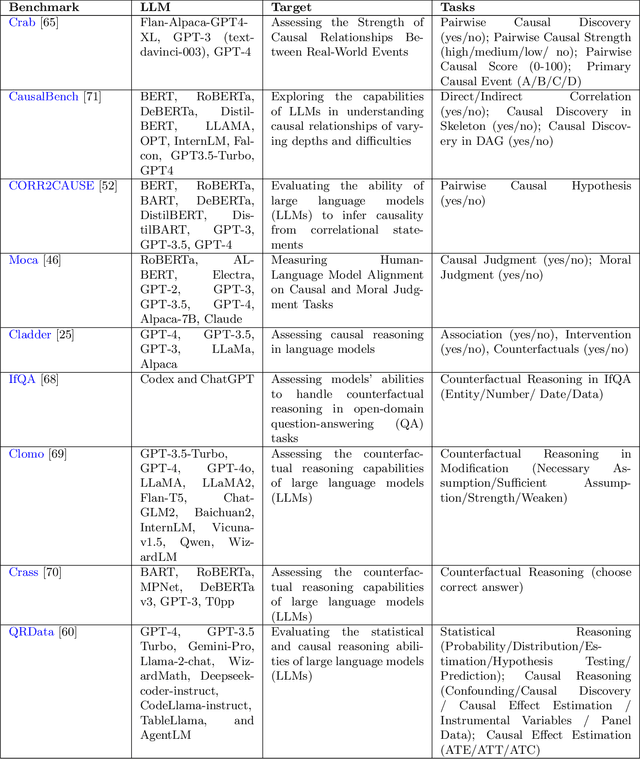
Recent breakthroughs in artificial intelligence have driven a paradigm shift, where large language models (LLMs) with billions or trillions of parameters are trained on vast datasets, achieving unprecedented success across a series of language tasks. However, despite these successes, LLMs still rely on probabilistic modeling, which often captures spurious correlations rooted in linguistic patterns and social stereotypes, rather than the true causal relationships between entities and events. This limitation renders LLMs vulnerable to issues such as demographic biases, social stereotypes, and LLM hallucinations. These challenges highlight the urgent need to integrate causality into LLMs, moving beyond correlation-driven paradigms to build more reliable and ethically aligned AI systems. While many existing surveys and studies focus on utilizing prompt engineering to activate LLMs for causal knowledge or developing benchmarks to assess their causal reasoning abilities, most of these efforts rely on human intervention to activate pre-trained models. How to embed causality into the training process of LLMs and build more general and intelligent models remains unexplored. Recent research highlights that LLMs function as causal parrots, capable of reciting causal knowledge without truly understanding or applying it. These prompt-based methods are still limited to human interventional improvements. This survey aims to address this gap by exploring how causality can enhance LLMs at every stage of their lifecycle-from token embedding learning and foundation model training to fine-tuning, alignment, inference, and evaluation-paving the way for more interpretable, reliable, and causally-informed models. Additionally, we further outline six promising future directions to advance LLM development, enhance their causal reasoning capabilities, and address the current limitations these models face.
Causal Inference with Complex Treatments: A Survey
Jul 19, 2024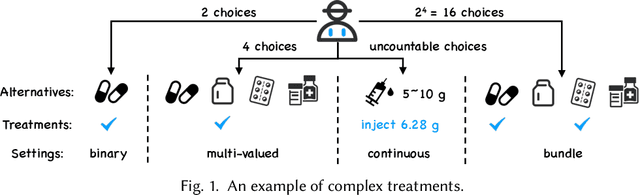
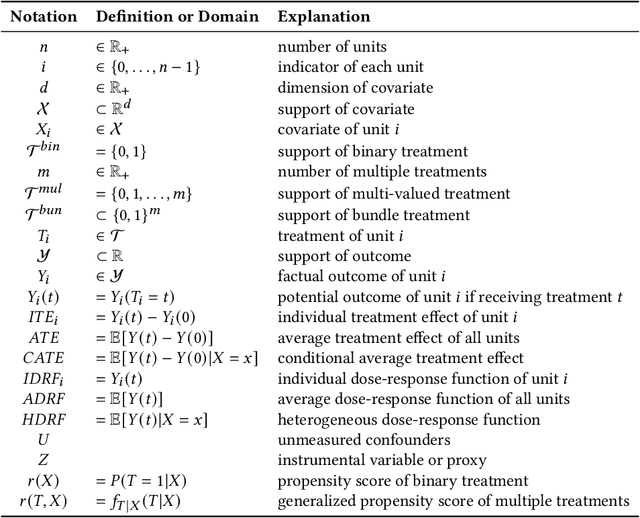
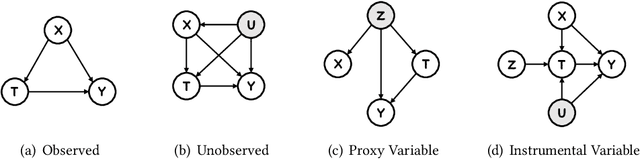

Causal inference plays an important role in explanatory analysis and decision making across various fields like statistics, marketing, health care, and education. Its main task is to estimate treatment effects and make intervention policies. Traditionally, most of the previous works typically focus on the binary treatment setting that there is only one treatment for a unit to adopt or not. However, in practice, the treatment can be much more complex, encompassing multi-valued, continuous, or bundle options. In this paper, we refer to these as complex treatments and systematically and comprehensively review the causal inference methods for addressing them. First, we formally revisit the problem definition, the basic assumptions, and their possible variations under specific conditions. Second, we sequentially review the related methods for multi-valued, continuous, and bundled treatment settings. In each situation, we tentatively divide the methods into two categories: those conforming to the unconfoundedness assumption and those violating it. Subsequently, we discuss the available datasets and open-source codes. Finally, we provide a brief summary of these works and suggest potential directions for future research.
Pareto-Optimal Estimation and Policy Learning on Short-term and Long-term Treatment Effects
Mar 12, 2024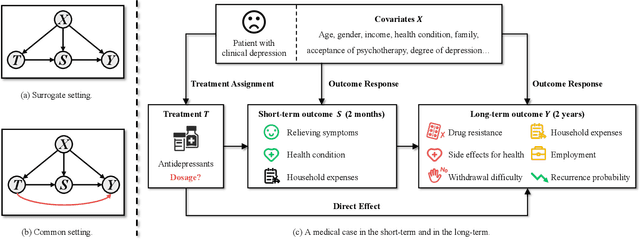



This paper focuses on developing Pareto-optimal estimation and policy learning to identify the most effective treatment that maximizes the total reward from both short-term and long-term effects, which might conflict with each other. For example, a higher dosage of medication might increase the speed of a patient's recovery (short-term) but could also result in severe long-term side effects. Although recent works have investigated the problems about short-term or long-term effects or the both, how to trade-off between them to achieve optimal treatment remains an open challenge. Moreover, when multiple objectives are directly estimated using conventional causal representation learning, the optimization directions among various tasks can conflict as well. In this paper, we systematically investigate these issues and introduce a Pareto-Efficient algorithm, comprising Pareto-Optimal Estimation (POE) and Pareto-Optimal Policy Learning (POPL), to tackle them. POE incorporates a continuous Pareto module with representation balancing, enhancing estimation efficiency across multiple tasks. As for POPL, it involves deriving short-term and long-term outcomes linked with various treatment levels, facilitating an exploration of the Pareto frontier emanating from these outcomes. Results on both the synthetic and real-world datasets demonstrate the superiority of our method.