 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Optimal Estimation and Policy Learning on Short-term and Long-term Treatment Effects
Paper and Code
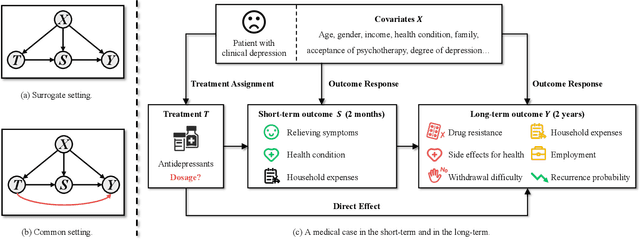



This paper focuses on developing Pareto-optimal estimation and policy learning to identify the most effective treatment that maximizes the total reward from both short-term and long-term effects, which might conflict with each other. For example, a higher dosage of medication might increase the speed of a patient's recovery (short-term) but could also result in severe long-term side effects. Although recent works have investigated the problems about short-term or long-term effects or the both, how to trade-off between them to achieve optimal treatment remains an open challenge. Moreover, when multiple objectives are directly estimated using conventional causal representation learning, the optimization directions among various tasks can conflict as well. In this paper, we systematically investigate these issues and introduce a Pareto-Efficient algorithm, comprising Pareto-Optimal Estimation (POE) and Pareto-Optimal Policy Learning (POPL), to tackle them. POE incorporates a continuous Pareto module with representation balancing, enhancing estimation efficiency across multiple tasks. As for POPL, it involves deriving short-term and long-term outcomes linked with various treatment levels, facilitating an exploration of the Pareto frontier emanating from these outcomes. Results on both the synthetic and real-world datasets demonstrate the superiority of our method.