 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in 4D Generation: A Survey
Mar 19, 2025Generative artificial intelligence (AI) has made significant progress across various domains in recent years. Building on the rapid advancements in 2D, video, and 3D content generation fields, 4D generation has emerged as a novel and rapidly evolving research area, attracting growing attention. 4D generation focuses on creating dynamic 3D assets with spatiotemporal consistency based on user input, offering greater creative freedom and richer immersive experiences. This paper presents a comprehensive survey of the 4D generation field, systematically summarizing its core technologies, developmental trajectory, key challenges, and practical applications, while also exploring potential future research directions. The survey begins by introducing various fundamental 4D representation models, followed by a review of 4D generation frameworks built upon these representations and the key technologies that incorporate motion and geometry priors into 4D assets. We summarize five major challenges of 4D generation: consistency, controllability, diversity, efficiency, and fidelity, accompanied by an outline of existing solutions to address these issues. We systematically analyze applications of 4D generation, spanning dynamic object generation, scene generation, digital human synthesis, 4D editing, and autonomous driving. Finally, we provide an in-depth discussion of the obstacles currently hindering the development of the 4D generation. This survey offers a clear and comprehensive overview of 4D generation, aiming to stimulate further exploration and innovation in this rapidly evolving field. Our code is publicly available at: https://github.com/MiaoQiaowei/Awesome-4D.
DICS: Find Domain-Invariant and Class-Specific Features for Out-of-Distribution Generalization
Sep 13, 2024



While deep neural networks have made remarkable progress in various vision tasks, their performance typically deteriorates when tested in out-of-distribution (OOD) scenarios. Many OOD methods focus on extracting domain-invariant features but neglect whether these features are unique to each class. Even if some features are domain-invariant, they cannot serve as key classification criteria if shared across different classes. In OOD tasks, both domain-related and class-shared features act as confounders that hinder generalization. In this paper, we propose a DICS model to extract Domain-Invariant and Class-Specific features, including Domain Invariance Testing (DIT) and Class Specificity Testing (CST), which mitigate the effects of spurious correlations introduced by confounders. DIT learns domain-related features of each source domain and removes them from inputs to isolate domain-invariant class-related features. DIT ensures domain invariance by aligning same-class features across different domains. Then, CST calculates soft labels for those features by comparing them with features learned in previous steps. We optimize the cross-entropy between the soft labels and their true labels, which enhances same-class similarity and different-class distinctiveness, thereby reinforcing class specificity. Extensive experiments on widely-used benchmarks demonstrate the effectiveness of our proposed algorithm. Additional visualizations further demonstrate that DICS effectively identifies the key features of each class in target domains.
PLA4D: Pixel-Level Alignments for Text-to-4D Gaussian Splatting
Jun 04, 2024As text-conditioned diffusion models (DMs) achieve breakthroughs in image, video, and 3D generation, the research community's focus has shifted to the more challenging task of text-to-4D synthesis, which introduces a temporal dimension to generate dynamic 3D objects. In this context, we identify Score Distillation Sampling (SDS), a widely used technique for text-to-3D synthesis, as a significant hindrance to text-to-4D performance due to its Janus-faced and texture-unrealistic problems coupled with high computational costs. In this paper, we propose \textbf{P}ixel-\textbf{L}evel \textbf{A}lignments for Text-to-\textbf{4D} Gaussian Splatting (\textbf{PLA4D}), a novel method that utilizes text-to-video frames as explicit pixel alignment targets to generate static 3D objects and inject motion into them. Specifically, we introduce Focal Alignment to calibrate camera poses for rendering and GS-Mesh Contrastive Learning to distill geometry priors from rendered image contrasts at the pixel level. Additionally, we develop Motion Alignment using a deformation network to drive changes in Gaussians and implement Reference Refinement for smooth 4D object surfaces. These techniques enable 4D Gaussian Splatting to align geometry, texture, and motion with generated videos at the pixel level. Compared to previous methods, PLA4D produces synthesized outputs with better texture details in less time and effectively mitigates the Janus-faced problem. PLA4D is fully implemented using open-source models, offering an accessible, user-friendly, and promising direction for 4D digital content creation. Our project page: https://github.com/MiaoQiaowei/PLA4D.github.io.
Pareto-Optimal Estimation and Policy Learning on Short-term and Long-term Treatment Effects
Mar 12, 2024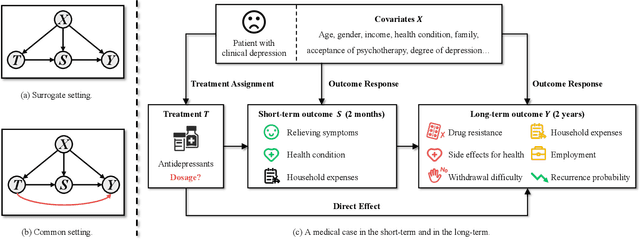



This paper focuses on developing Pareto-optimal estimation and policy learning to identify the most effective treatment that maximizes the total reward from both short-term and long-term effects, which might conflict with each other. For example, a higher dosage of medication might increase the speed of a patient's recovery (short-term) but could also result in severe long-term side effects. Although recent works have investigated the problems about short-term or long-term effects or the both, how to trade-off between them to achieve optimal treatment remains an open challenge. Moreover, when multiple objectives are directly estimated using conventional causal representation learning, the optimization directions among various tasks can conflict as well. In this paper, we systematically investigate these issues and introduce a Pareto-Efficient algorithm, comprising Pareto-Optimal Estimation (POE) and Pareto-Optimal Policy Learning (POPL), to tackle them. POE incorporates a continuous Pareto module with representation balancing, enhancing estimation efficiency across multiple tasks. As for POPL, it involves deriving short-term and long-term outcomes linked with various treatment levels, facilitating an exploration of the Pareto frontier emanating from these outcomes. Results on both the synthetic and real-world datasets demonstrate the superiority of our method.
Domain Generalization via Contrastive Causal Learning
Oct 06, 2022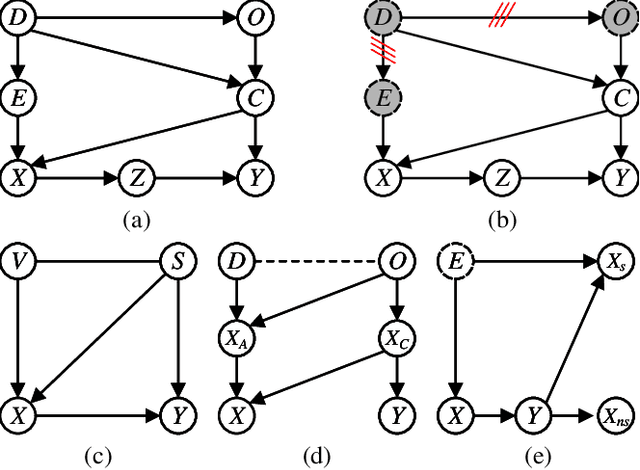
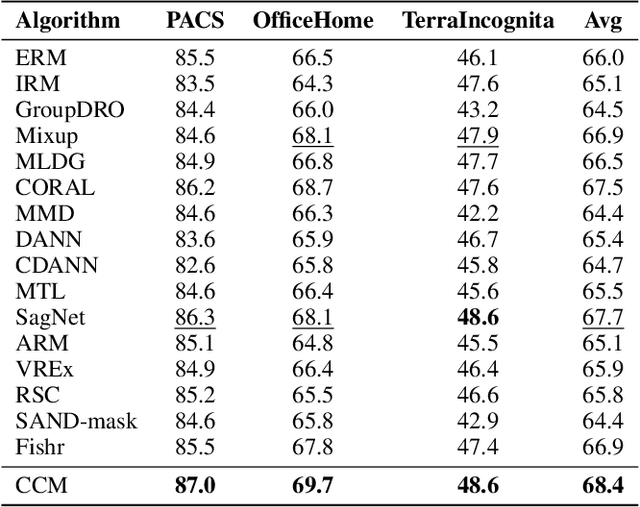
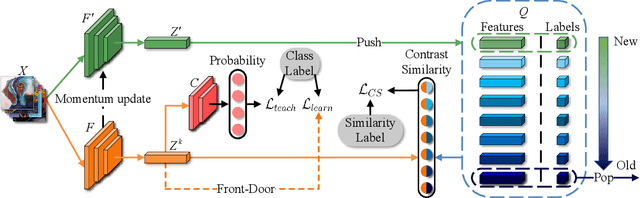
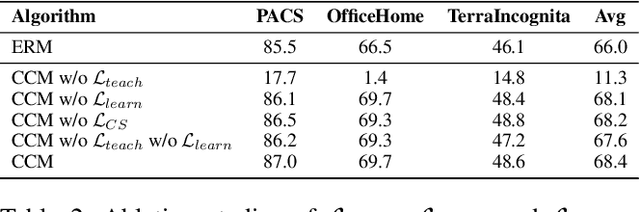
Domain Generalization (DG) aims to learn a model that can generalize well to unseen target domains from a set of source domains. With the idea of invariant causal mechanism, a lot of efforts have been put into learning robust causal effects which are determined by the object yet insensitive to the domain changes. Despite the invariance of causal effects, they are difficult to be quantified and optimized. Inspired by the ability that humans adapt to new environments by prior knowledge, We develop a novel Contrastive Causal Model (CCM) to transfer unseen images to taught knowledge which are the features of seen images, and quantify the causal effects based on taught knowledge. Considering the transfer is affected by domain shifts in DG, we propose a more inclusive causal graph to describe DG task. Based on this causal graph, CCM controls the domain factor to cut off excess causal paths and uses the remaining part to calculate the causal effects of images to labels via the front-door criterion. Specifically, CCM is composed of three components: (i) domain-conditioned supervised learning which teaches CCM the correlation between images and labels, (ii) causal effect learning which helps CCM measure the true causal effects of images to labels, (iii) contrastive similarity learning which clusters the features of images that belong to the same class and provides the quantification of similarity. Finally, we test the performance of CCM on multiple datasets including PACS, OfficeHome, and TerraIncognita. The extensive experiments demonstrate that CCM surpasses the previous DG methods with clear margins.