 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotent but Stealthy: Rethink Profile Pollution against Sequential Recommendation via Bi-level Constrained Reinforcement Paradigm
Nov 14, 2025Sequential Recommenders, which exploit dynamic user intents through interaction sequences, is vulnerable to adversarial attacks. While existing attacks primarily rely on data poisoning, they require large-scale user access or fake profiles thus lacking practicality. In this paper, we focus on the Profile Pollution Attack that subtly contaminates partial user interactions to induce targeted mispredictions. Previous PPA methods suffer from two limitations, i.e., i) over-reliance on sequence horizon impact restricts fine-grained perturbations on item transitions, and ii) holistic modifications cause detectable distribution shifts. To address these challenges, we propose a constrained reinforcement driven attack CREAT that synergizes a bi-level optimization framework with multi-reward reinforcement learning to balance adversarial efficacy and stealthiness. We first develop a Pattern Balanced Rewarding Policy, which integrates pattern inversion rewards to invert critical patterns and distribution consistency rewards to minimize detectable shifts via unbalanced co-optimal transport. Then we employ a Constrained Group Relative Reinforcement Learning paradigm, enabling step-wise perturbations through dynamic barrier constraints and group-shared experience replay, achieving targeted pollution with minimal detectability. Extensive experiments demonstrate the effectiveness of CREAT.
Deterministic-to-Stochastic Diverse Latent Feature Mapping for Human Motion Synthesis
May 02, 2025Human motion synthesis aims to generate plausible human motion sequences, which has raised widespread attention in computer animation. Recent score-based generative models (SGMs) have demonstrated impressive results on this task. However, their training process involves complex curvature trajectories, leading to unstable training process. In this paper, we propose a Deterministic-to-Stochastic Diverse Latent Feature Mapping (DSDFM) method for human motion synthesis. DSDFM consists of two stages. The first human motion reconstruction stage aims to learn the latent space distribution of human motions. The second diverse motion generation stage aims to build connections between the Gaussian distribution and the latent space distribution of human motions, thereby enhancing the diversity and accuracy of the generated human motions. This stage is achieved by the designed deterministic feature mapping procedure with DerODE and stochastic diverse output generation procedure with DivSDE.DSDFM is easy to train compared to previous SGMs-based methods and can enhance diversity without introducing additional training parameters.Through qualitative and quantitative experiments, DSDFM achieves state-of-the-art results surpassing the latest methods, validating its superiority in human motion synthesis.
Distilling Transitional Pattern to Large Language Models for Multimodal Session-based Recommendation
Apr 13, 2025Session-based recommendation (SBR) predicts the next item based on anonymous sessions. Traditional SBR explores user intents based on ID collaborations or auxiliary content. To further alleviate data sparsity and cold-start issues, recent Multimodal SBR (MSBR) methods utilize simplistic pre-trained models for modality learning but have limitations in semantic richness. Considering semantic reasoning abilities of Large Language Models (LLM), we focus on the LLM-enhanced MSBR scenario in this paper, which leverages LLM cognition for comprehensive multimodal representation generation, to enhance downstream MSBR. Tackling this problem faces two challenges: i) how to obtain LLM cognition on both transitional patterns and inherent multimodal knowledge, ii) how to align both features into one unified LLM, minimize discrepancy while maximizing representation utility. To this end, we propose a multimodal LLM-enhanced framework TPAD, which extends a distillation paradigm to decouple and align transitional patterns for promoting MSBR. TPAD establishes parallel Knowledge-MLLM and Transfer-MLLM, where the former interprets item knowledge-reflected features and the latter extracts transition-aware features underneath sessions. A transitional pattern alignment module harnessing mutual information estimation theory unites two MLLMs, alleviating distribution discrepancy and distilling transitional patterns into modal representations. Extensive experiments on real-world datasets demonstrate the effectiveness of our framework.
Joint Similarity Item Exploration and Overlapped User Guidance for Multi-Modal Cross-Domain Recommendation
Feb 22, 2025Cross-Domain Recommendation (CDR) has been widely investigated for solving long-standing data sparsity problem via knowledge sharing across domains. In this paper, we focus on the Multi-Modal Cross-Domain Recommendation (MMCDR) problem where different items have multi-modal information while few users are overlapped across domains. MMCDR is particularly challenging in two aspects: fully exploiting diverse multi-modal information within each domain and leveraging useful knowledge transfer across domains. However, previous methods fail to cluster items with similar characteristics while filtering out inherit noises within different modalities, hurdling the model performance. What is worse, conventional CDR models primarily rely on overlapped users for domain adaptation, making them ill-equipped to handle scenarios where the majority of users are non-overlapped. To fill this gap, we propose Joint Similarity Item Exploration and Overlapped User Guidance (SIEOUG) for solving the MMCDR problem. SIEOUG first proposes similarity item exploration module, which not only obtains pair-wise and group-wise item-item graph knowledge, but also reduces irrelevant noise for multi-modal modeling. Then SIEOUG proposes user-item collaborative filtering module to aggregate user/item embeddings with the attention mechanism for collaborative filtering. Finally SIEOUG proposes overlapped user guidance module with optimal user matching for knowledge sharing across domains. Our empirical study on Amazon dataset with several different tasks demonstrates that SIEOUG significantly outperforms the state-of-the-art models under the MMCDR setting.
Diverse Policies Recovering via Pointwise Mutual Information Weighted Imitation Learning
Oct 21, 2024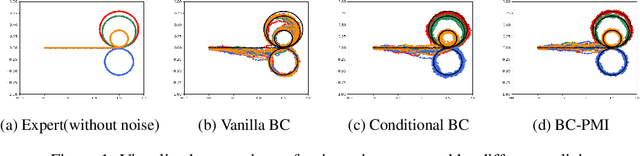
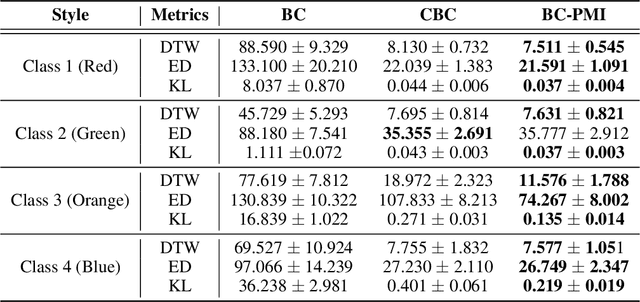
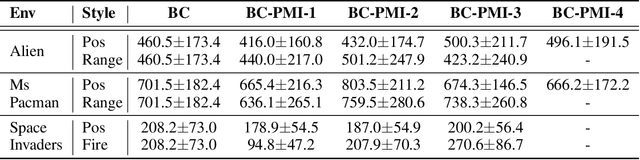
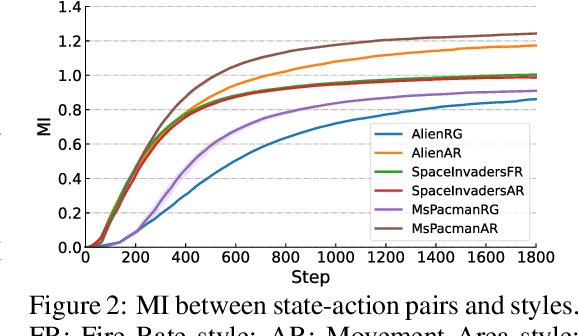
Recovering a spectrum of diverse policies from a set of expert trajectories is an important research topic in imitation learning. After determining a latent style for a trajectory, previous diverse policies recovering methods usually employ a vanilla behavioral cloning learning objective conditioned on the latent style, treating each state-action pair in the trajectory with equal importance. Based on an observation that in many scenarios, behavioral styles are often highly relevant with only a subset of state-action pairs, this paper presents a new principled method in diverse polices recovery. In particular, after inferring or assigning a latent style for a trajectory, we enhance the vanilla behavioral cloning by incorporating a weighting mechanism based on pointwise mutual information. This additional weighting reflects the significance of each state-action pair's contribution to learning the style, thus allowing our method to focus on state-action pairs most representative of that style. We provide theoretical justifications for our new objective, and extensive empirical evaluations confirm the effectiveness of our method in recovering diverse policies from expert data.
FOOGD: Federated Collaboration for Both Out-of-distribution Generalization and Detection
Oct 15, 2024



Federated learning (FL) is a promising machine learning paradigm that collaborates with client models to capture global knowledge. However, deploying FL models in real-world scenarios remains unreliable due to the coexistence of in-distribution data and unexpected out-of-distribution (OOD) data, such as covariate-shift and semantic-shift data. Current FL researches typically address either covariate-shift data through OOD generalization or semantic-shift data via OOD detection, overlooking the simultaneous occurrence of various OOD shifts. In this work, we propose FOOGD, a method that estimates the probability density of each client and obtains reliable global distribution as guidance for the subsequent FL process. Firstly, SM3D in FOOGD estimates score model for arbitrary distributions without prior constraints, and detects semantic-shift data powerfully. Then SAG in FOOGD provides invariant yet diverse knowledge for both local covariate-shift generalization and client performance generalization. In empirical validations, FOOGD significantly enjoys three main advantages: (1) reliably estimating non-normalized decentralized distributions, (2) detecting semantic shift data via score values, and (3) generalizing to covariate-shift data by regularizing feature extractor. The prejoct is open in https://github.com/XeniaLLL/FOOGD-main.git.
Rethinking the Representation in Federated Unsupervised Learning with Non-IID Data
Mar 25, 2024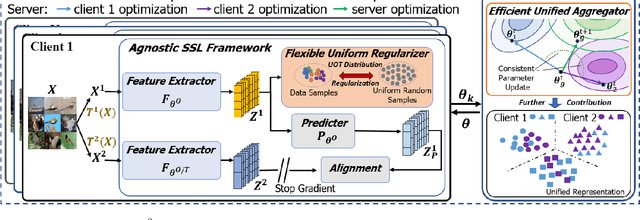
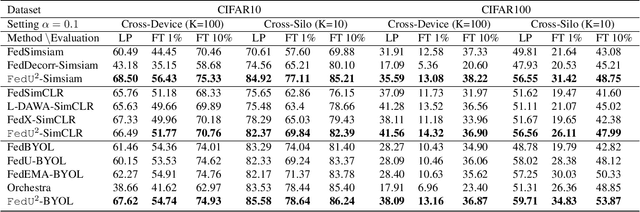

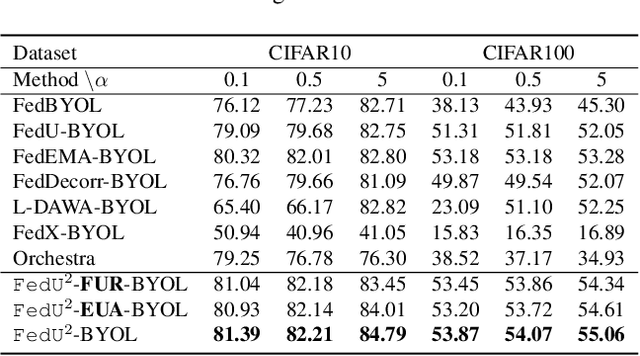
Federated learning achieves effective performance in modeling decentralized data. In practice, client data are not well-labeled, which makes it potential for federated unsupervised learning (FUSL) with non-IID data. However, the performance of existing FUSL methods suffers from insufficient representations, i.e., (1) representation collapse entanglement among local and global models, and (2) inconsistent representation spaces among local models. The former indicates that representation collapse in local model will subsequently impact the global model and other local models. The latter means that clients model data representation with inconsistent parameters due to the deficiency of supervision signals. In this work, we propose FedU2 which enhances generating uniform and unified representation in FUSL with non-IID data. Specifically, FedU2 consists of flexible uniform regularizer (FUR) and efficient unified aggregator (EUA). FUR in each client avoids representation collapse via dispersing samples uniformly, and EUA in server promotes unified representation by constraining consistent client model updating. To extensively validate the performance of FedU2, we conduct both cross-device and cross-silo evaluation experiments on two benchmark datasets, i.e., CIFAR10 and CIFAR100.
Pareto-Optimal Estimation and Policy Learning on Short-term and Long-term Treatment Effects
Mar 12, 2024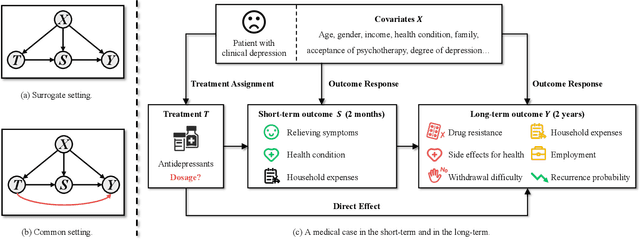



This paper focuses on developing Pareto-optimal estimation and policy learning to identify the most effective treatment that maximizes the total reward from both short-term and long-term effects, which might conflict with each other. For example, a higher dosage of medication might increase the speed of a patient's recovery (short-term) but could also result in severe long-term side effects. Although recent works have investigated the problems about short-term or long-term effects or the both, how to trade-off between them to achieve optimal treatment remains an open challenge. Moreover, when multiple objectives are directly estimated using conventional causal representation learning, the optimization directions among various tasks can conflict as well. In this paper, we systematically investigate these issues and introduce a Pareto-Efficient algorithm, comprising Pareto-Optimal Estimation (POE) and Pareto-Optimal Policy Learning (POPL), to tackle them. POE incorporates a continuous Pareto module with representation balancing, enhancing estimation efficiency across multiple tasks. As for POPL, it involves deriving short-term and long-term outcomes linked with various treatment levels, facilitating an exploration of the Pareto frontier emanating from these outcomes. Results on both the synthetic and real-world datasets demonstrate the superiority of our method.
Personalized Behavior-Aware Transformer for Multi-Behavior Sequential Recommendation
Feb 22, 2024



Sequential Recommendation (SR) captures users' dynamic preferences by modeling how users transit among items. However, SR models that utilize only single type of behavior interaction data encounter performance degradation when the sequences are short. To tackle this problem, we focus on Multi-Behavior Sequential Recommendation (MBSR) in this paper, which aims to leverage time-evolving heterogeneous behavioral dependencies for better exploring users' potential intents on the target behavior. Solving MBSR is challenging. On the one hand, users exhibit diverse multi-behavior patterns due to personal characteristics. On the other hand, there exists comprehensive co-influence between behavior correlations and item collaborations, the intensity of which is deeply affected by temporal factors. To tackle these challenges, we propose a Personalized Behavior-Aware Transformer framework (PBAT) for MBSR problem, which models personalized patterns and multifaceted sequential collaborations in a novel way to boost recommendation performance. First, PBAT develops a personalized behavior pattern generator in the representation layer, which extracts dynamic and discriminative behavior patterns for sequential learning. Second, PBAT reforms the self-attention layer with a behavior-aware collaboration extractor, which introduces a fused behavior-aware attention mechanism for incorporating both behavioral and temporal impacts into collaborative transitions. We conduct experiments on three benchmark datasets and the results demonstrate the effectiveness and interpretability of our framework. Our implementation code is released at https://github.com/TiliaceaeSU/PBAT.
Learning Uniform Clusters on Hypersphere for Deep Graph-level Clustering
Nov 23, 2023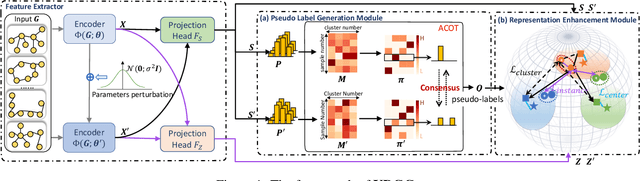



Graph clustering has been popularly studied in recent years. However, most existing graph clustering methods focus on node-level clustering, i.e., grouping nodes in a single graph into clusters. In contrast, graph-level clustering, i.e., grouping multiple graphs into clusters, remains largely unexplored. Graph-level clustering is critical in a variety of real-world applications, such as, properties prediction of molecules and community analysis in social networks. However, graph-level clustering is challenging due to the insufficient discriminability of graph-level representations, and the insufficient discriminability makes deep clustering be more likely to obtain degenerate solutions (cluster collapse). To address the issue, we propose a novel deep graph-level clustering method called Uniform Deep Graph Clustering (UDGC). UDGC assigns instances evenly to different clusters and then scatters those clusters on unit hypersphere, leading to a more uniform cluster-level distribution and a slighter cluster collapse. Specifically, we first propose Augmentation-Consensus Optimal Transport (ACOT) for generating uniformly distributed and reliable pseudo labels for partitioning clusters. Then we adopt contrastive learning to scatter those clusters. Besides, we propose Center Alignment Optimal Transport (CAOT) for guiding the model to learn better parameters, which further promotes the cluster performance. Our empirical study on eight well-known datasets demonstrates that UDGC significantly outperforms the state-of-the-art models.