 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Representation in Federated Unsupervised Learning with Non-IID Data
Mar 25, 2024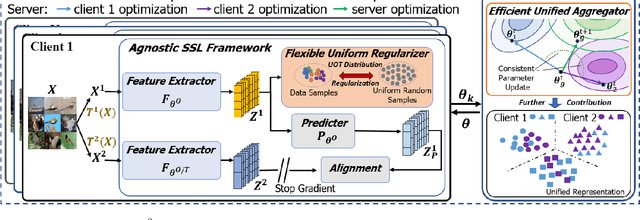
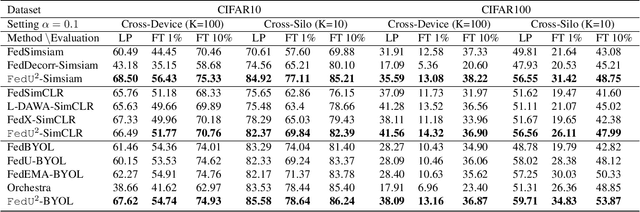

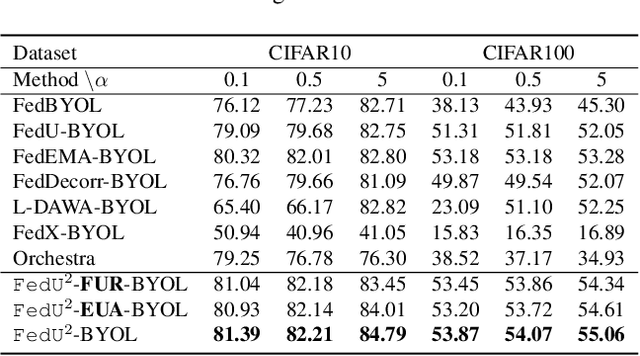
Federated learning achieves effective performance in modeling decentralized data. In practice, client data are not well-labeled, which makes it potential for federated unsupervised learning (FUSL) with non-IID data. However, the performance of existing FUSL methods suffers from insufficient representations, i.e., (1) representation collapse entanglement among local and global models, and (2) inconsistent representation spaces among local models. The former indicates that representation collapse in local model will subsequently impact the global model and other local models. The latter means that clients model data representation with inconsistent parameters due to the deficiency of supervision signals. In this work, we propose FedU2 which enhances generating uniform and unified representation in FUSL with non-IID data. Specifically, FedU2 consists of flexible uniform regularizer (FUR) and efficient unified aggregator (EUA). FUR in each client avoids representation collapse via dispersing samples uniformly, and EUA in server promotes unified representation by constraining consistent client model updating. To extensively validate the performance of FedU2, we conduct both cross-device and cross-silo evaluation experiments on two benchmark datasets, i.e., CIFAR10 and CIFAR100.
Reducing Communication for Split Learning by Randomized Top-k Sparsification
May 29, 2023

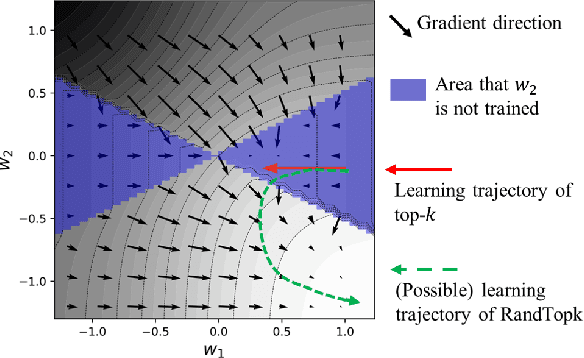
Split learning is a simple solution for Vertical Federated Learning (VFL), which has drawn substantial attention in both research and application due to its simplicity and efficiency. However, communication efficiency is still a crucial issue for split learning. In this paper, we investigate multiple communication reduction methods for split learning, including cut layer size reduction, top-k sparsification, quantization, and L1 regularization. Through analysis of the cut layer size reduction and top-k sparsification, we further propose randomized top-k sparsification, to make the model generalize and converge better. This is done by selecting top-k elements with a large probability while also having a small probability to select non-top-k elements. Empirical results show that compared with other communication-reduction methods, our proposed randomized top-k sparsification achieves a better model performance under the same compression level.
PPGenCDR: A Stable and Robust Framework for Privacy-Preserving Cross-Domain Recommendation
May 11, 2023Privacy-preserving cross-domain recommendation (PPCDR) refers to preserving the privacy of users when transferring the knowledge from source domain to target domain for better performance, which is vital for the long-term development of recommender systems. Existing work on cross-domain recommendation (CDR) reaches advanced and satisfying recommendation performance, but mostly neglects preserving privacy. To fill this gap, we propose a privacy-preserving generative cross-domain recommendation (PPGenCDR) framework for PPCDR. PPGenCDR includes two main modules, i.e., stable privacy-preserving generator module, and robust cross-domain recommendation module. Specifically, the former isolates data from different domains with a generative adversarial network (GAN) based model, which stably estimates the distribution of private data in the source domain with Renyi differential privacy (RDP) technique. Then the latter aims to robustly leverage the perturbed but effective knowledge from the source domain with the raw data in target domain to improve recommendation performance. Three key modules, i.e., (1) selective privacy preserver, (2) GAN stabilizer, and (3) robustness conductor, guarantee the cost-effective trade-off between utility and privacy, the stability of GAN when using RDP, and the robustness of leveraging transferable knowledge accordingly. The extensive empirical studies on Douban and Amazon datasets demonstrate that PPGenCDR significantly outperforms the state-of-the-art recommendation models while preserving privacy.
Making Split Learning Resilient to Label Leakage by Potential Energy Loss
Oct 18, 2022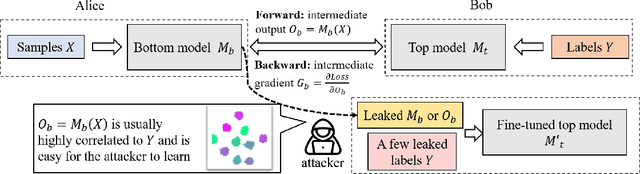
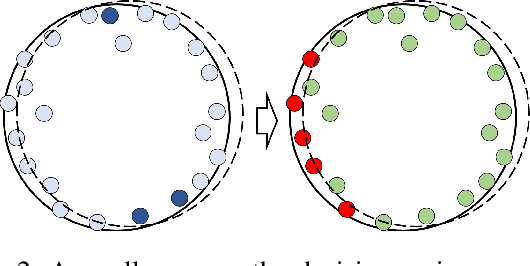
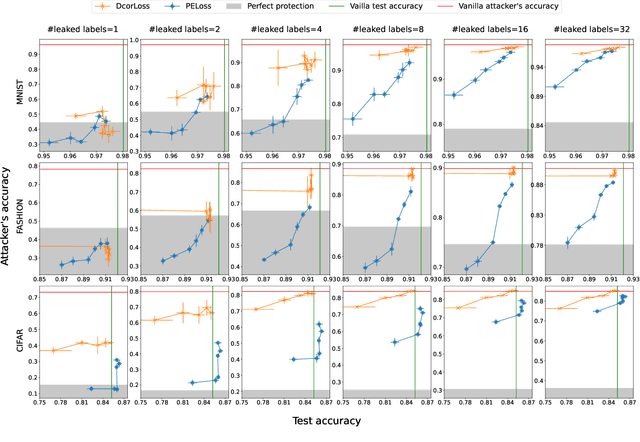
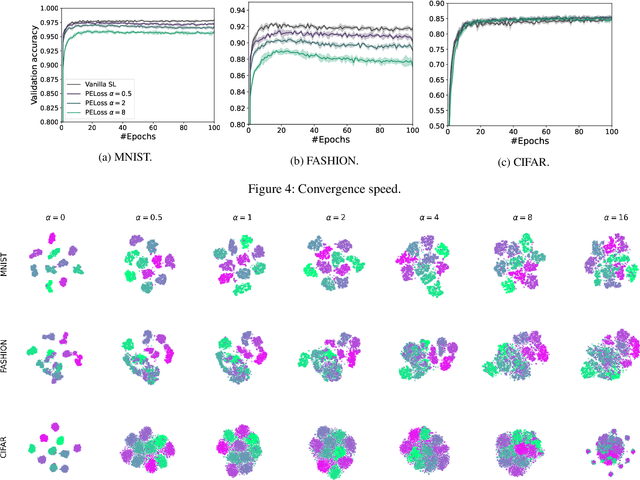
As a practical privacy-preserving learning method, split learning has drawn much attention in academia and industry. However, its security is constantly being questioned since the intermediate results are shared during training and inference. In this paper, we focus on the privacy leakage problem caused by the trained split model, i.e., the attacker can use a few labeled samples to fine-tune the bottom model, and gets quite good performance. To prevent such kind of privacy leakage, we propose the potential energy loss to make the output of the bottom model become a more `complicated' distribution, by pushing outputs of the same class towards the decision boundary. Therefore, the adversary suffers a large generalization error when fine-tuning the bottom model with only a few leaked labeled samples. Experiment results show that our method significantly lowers the attacker's fine-tuning accuracy, making the split model more resilient to label leakage.