 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Split Learning Resilient to Label Leakage by Potential Energy Loss
Paper and Code
Oct 18, 2022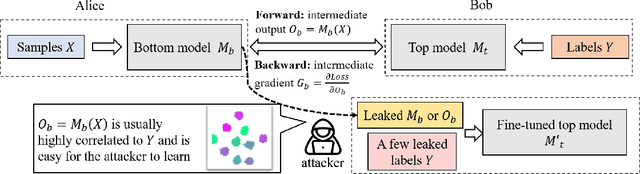
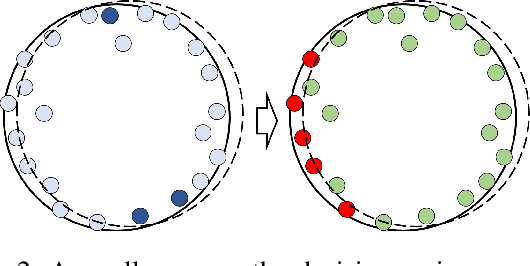
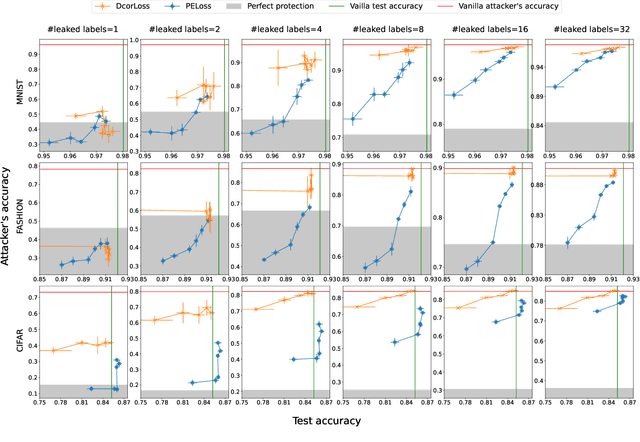
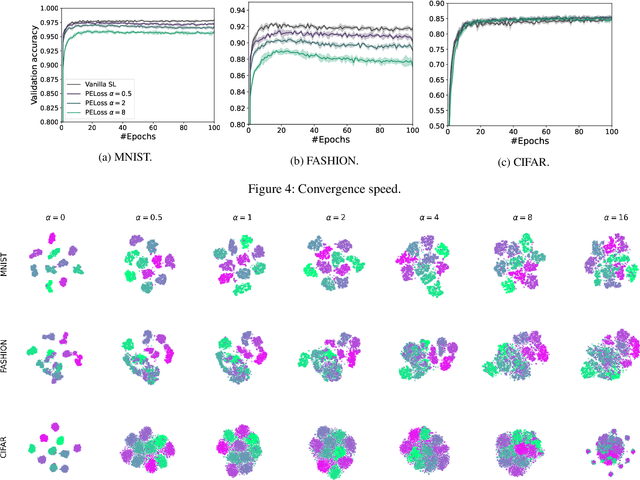
As a practical privacy-preserving learning method, split learning has drawn much attention in academia and industry. However, its security is constantly being questioned since the intermediate results are shared during training and inference. In this paper, we focus on the privacy leakage problem caused by the trained split model, i.e., the attacker can use a few labeled samples to fine-tune the bottom model, and gets quite good performance. To prevent such kind of privacy leakage, we propose the potential energy loss to make the output of the bottom model become a more `complicated' distribution, by pushing outputs of the same class towards the decision boundary. Therefore, the adversary suffers a large generalization error when fine-tuning the bottom model with only a few leaked labeled samples. Experiment results show that our method significantly lowers the attacker's fine-tuning accuracy, making the split model more resilient to label leakage.