 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAID: An In-Training Defense against Attribute Inference Attacks in Recommender Systems
Apr 15, 2025In various networks and mobile applications, users are highly susceptible to attribute inference attacks, with particularly prevalent occurrences in recommender systems. Attackers exploit partially exposed user profiles in recommendation models, such as user embeddings, to infer private attributes of target users, such as gender and political views. The goal of defenders is to mitigate the effectiveness of these attacks while maintaining recommendation performance. Most existing defense methods, such as differential privacy and attribute unlearning, focus on post-training settings, which limits their capability of utilizing training data to preserve recommendation performance. Although adversarial training extends defenses to in-training settings, it often struggles with convergence due to unstable training processes. In this paper, we propose RAID, an in-training defense method against attribute inference attacks in recommender systems. In addition to the recommendation objective, we define a defensive objective to ensure that the distribution of protected attributes becomes independent of class labels, making users indistinguishable from attribute inference attacks. Specifically, this defensive objective aims to solve a constrained Wasserstein barycenter problem to identify the centroid distribution that makes the attribute indistinguishable while complying with recommendation performance constraints. To optimize our proposed objective, we use optimal transport to align users with the centroid distribution. We conduct extensive experiments on four real-world datasets to evaluate RAID. The experimental results validate the effectiveness of RAID and demonstrate its significant superiority over existing methods in multiple aspects.
FOOGD: Federated Collaboration for Both Out-of-distribution Generalization and Detection
Oct 15, 2024



Federated learning (FL) is a promising machine learning paradigm that collaborates with client models to capture global knowledge. However, deploying FL models in real-world scenarios remains unreliable due to the coexistence of in-distribution data and unexpected out-of-distribution (OOD) data, such as covariate-shift and semantic-shift data. Current FL researches typically address either covariate-shift data through OOD generalization or semantic-shift data via OOD detection, overlooking the simultaneous occurrence of various OOD shifts. In this work, we propose FOOGD, a method that estimates the probability density of each client and obtains reliable global distribution as guidance for the subsequent FL process. Firstly, SM3D in FOOGD estimates score model for arbitrary distributions without prior constraints, and detects semantic-shift data powerfully. Then SAG in FOOGD provides invariant yet diverse knowledge for both local covariate-shift generalization and client performance generalization. In empirical validations, FOOGD significantly enjoys three main advantages: (1) reliably estimating non-normalized decentralized distributions, (2) detecting semantic shift data via score values, and (3) generalizing to covariate-shift data by regularizing feature extractor. The prejoct is open in https://github.com/XeniaLLL/FOOGD-main.git.
Rethinking the Representation in Federated Unsupervised Learning with Non-IID Data
Mar 25, 2024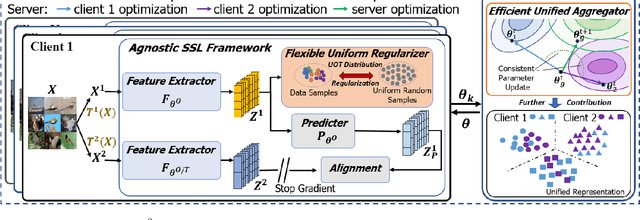
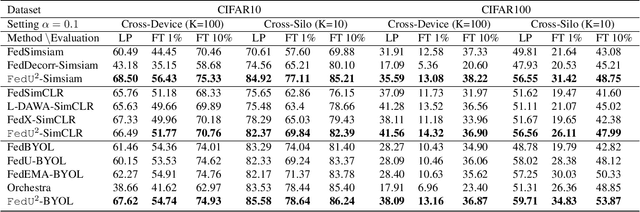

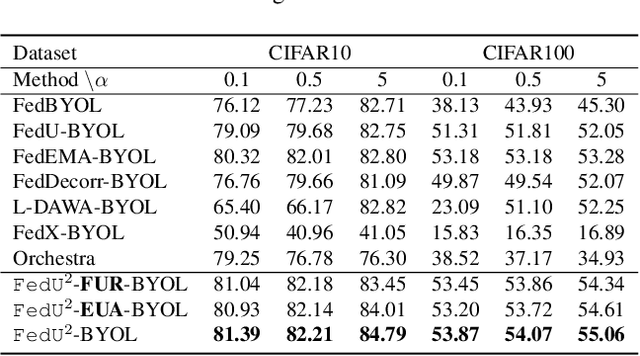
Federated learning achieves effective performance in modeling decentralized data. In practice, client data are not well-labeled, which makes it potential for federated unsupervised learning (FUSL) with non-IID data. However, the performance of existing FUSL methods suffers from insufficient representations, i.e., (1) representation collapse entanglement among local and global models, and (2) inconsistent representation spaces among local models. The former indicates that representation collapse in local model will subsequently impact the global model and other local models. The latter means that clients model data representation with inconsistent parameters due to the deficiency of supervision signals. In this work, we propose FedU2 which enhances generating uniform and unified representation in FUSL with non-IID data. Specifically, FedU2 consists of flexible uniform regularizer (FUR) and efficient unified aggregator (EUA). FUR in each client avoids representation collapse via dispersing samples uniformly, and EUA in server promotes unified representation by constraining consistent client model updating. To extensively validate the performance of FedU2, we conduct both cross-device and cross-silo evaluation experiments on two benchmark datasets, i.e., CIFAR10 and CIFAR100.
DRAM Failure Prediction in AIOps: Empirical Evaluation, Challenges and Opportunities
May 04, 2021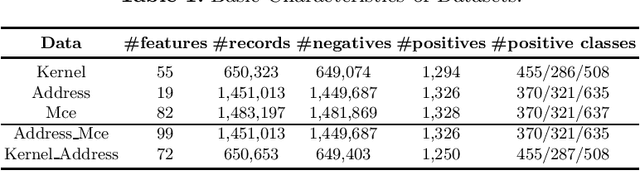
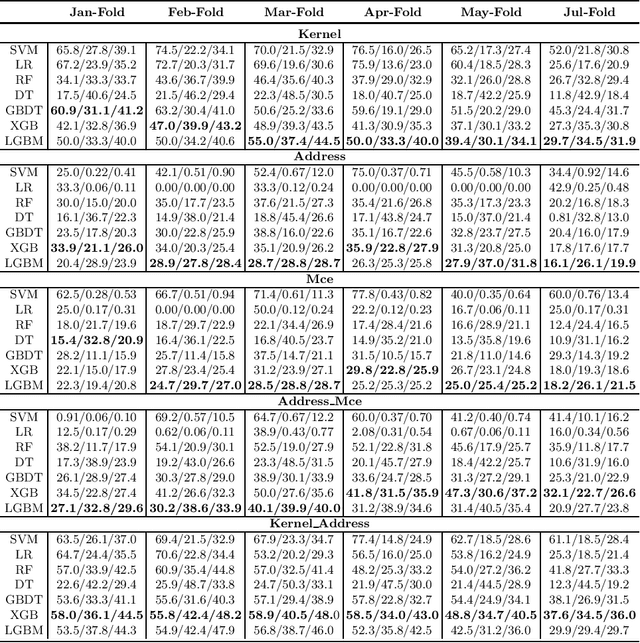
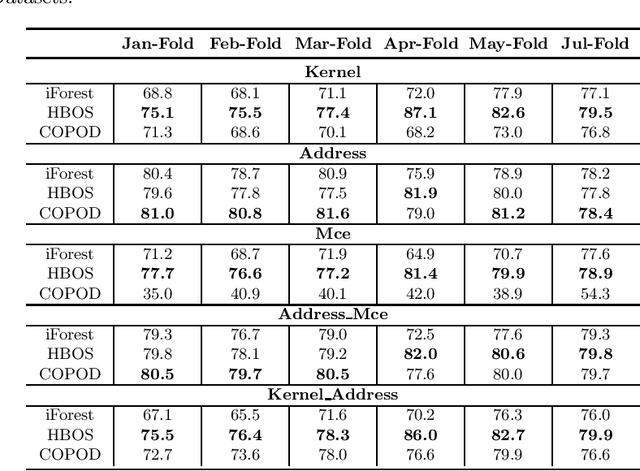
DRAM failure prediction is a vital task in AIOps, which is crucial to maintain the reliability and sustainable service of large-scale data centers. However, limited work has been done on DRAM failure prediction mainly due to the lack of public available datasets. This paper presents a comprehensive empirical evaluation of diverse machine learning techniques for DRAM failure prediction using a large-scale multi-source dataset, including more than three millions of records of kernel, address, and mcelog data, provided by Alibaba Cloud through PAKDD 2021 competition. Particularly, we first formulate the problem as a multi-class classification task and exhaustively evaluate seven popular/state-of-the-art classifiers on both the individual and multiple data sources. We then formulate the problem as an unsupervised anomaly detection task and evaluate three state-of-the-art anomaly detectors. Further, based on the empirical results and our experience of attending this competition, we discuss major challenges and present future research opportunities in this task.