 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Chunking for Soft Prompts: Accelerating Compressor Learning via Block-wise Causal Masking
Feb 15, 2026Providing extensive context via prompting is vital for leveraging the capabilities of Large Language Models (LLMs). However, lengthy contexts significantly increase inference latency, as the computational cost of self-attention grows quadratically with sequence length. To mitigate this issue, context compression-particularly soft prompt compressio-has emerged as a widely studied solution, which converts long contexts into shorter memory embeddings via a trained compressor. Existing methods typically compress the entire context indiscriminately into a set of memory tokens, requiring the compressor to capture global dependencies and necessitating extensive pre-training data to learn effective patterns. Inspired by the chunking mechanism in human working memory and empirical observations of the spatial specialization of memory embeddings relative to original tokens, we propose Parallelized Iterative Compression (PIC). By simply modifying the Transformer's attention mask, PIC explicitly restricts the receptive field of memory tokens to sequential local chunks, thereby lowering the difficulty of compressor training. Experiments across multiple downstream tasks demonstrate that PIC consistently outperforms competitive baselines, with superiority being particularly pronounced in high compression scenarios (e.g., achieving relative improvements of 29.8\% in F1 score and 40.7\% in EM score on QA tasks at the $64\times$ compression ratio). Furthermore, PIC significantly expedites the training process. Specifically, when training the 16$\times$ compressor, it surpasses the peak performance of the competitive baseline while effectively reducing the training time by approximately 40\%.
JPU: Bridging Jailbreak Defense and Unlearning via On-Policy Path Rectification
Jan 06, 2026Despite extensive safety alignment, Large Language Models (LLMs) often fail against jailbreak attacks. While machine unlearning has emerged as a promising defense by erasing specific harmful parameters, current methods remain vulnerable to diverse jailbreaks. We first conduct an empirical study and discover that this failure mechanism is caused by jailbreaks primarily activating non-erased parameters in the intermediate layers. Further, by probing the underlying mechanism through which these circumvented parameters reassemble into the prohibited output, we verify the persistent existence of dynamic $\textbf{jailbreak paths}$ and show that the inability to rectify them constitutes the fundamental gap in existing unlearning defenses. To bridge this gap, we propose $\textbf{J}$ailbreak $\textbf{P}$ath $\textbf{U}$nlearning (JPU), which is the first to rectify dynamic jailbreak paths towards safety anchors by dynamically mining on-policy adversarial samples to expose vulnerabilities and identify jailbreak paths. Extensive experiments demonstrate that JPU significantly enhances jailbreak resistance against dynamic attacks while preserving the model's utility.
Angel or Devil: Discriminating Hard Samples and Anomaly Contaminations for Unsupervised Time Series Anomaly Detection
Oct 26, 2024



Training in unsupervised time series anomaly detection is constantly plagued by the discrimination between harmful `anomaly contaminations' and beneficial `hard normal samples'. These two samples exhibit analogous loss behavior that conventional loss-based methodologies struggle to differentiate. To tackle this problem, we propose a novel approach that supplements traditional loss behavior with `parameter behavior', enabling a more granular characterization of anomalous patterns. Parameter behavior is formalized by measuring the parametric response to minute perturbations in input samples. Leveraging the complementary nature of parameter and loss behaviors, we further propose a dual Parameter-Loss Data Augmentation method (termed PLDA), implemented within the reinforcement learning paradigm. During the training phase of anomaly detection, PLDA dynamically augments the training data through an iterative process that simultaneously mitigates anomaly contaminations while amplifying informative hard normal samples. PLDA demonstrates remarkable versatility, which can serve as an additional component that seamlessly integrated with existing anomaly detectors to enhance their detection performance. Extensive experiments on ten datasets show that PLDA significantly improves the performance of four distinct detectors by up to 8\%, outperforming three state-of-the-art data augmentation methods.
Multi-scale Recurrent LSTM and Transformer Network for Depth Completion
Sep 28, 2023Lidar depth completion is a new and hot topic of depth estimation. In this task, it is the key and difficult point to fuse the features of color space and depth space. In this paper, we migrate the classic LSTM and Transformer modules from NLP to depth completion and redesign them appropriately. Specifically, we use Forget gate, Update gate, Output gate, and Skip gate to achieve the efficient fusion of color and depth features and perform loop optimization at multiple scales. Finally, we further fuse the deep features through the Transformer multi-head attention mechanism. Experimental results show that without repetitive network structure and post-processing steps, our method can achieve state-of-the-art performance by adding our modules to a simple encoder-decoder network structure. Our method ranks first on the current mainstream autonomous driving KITTI benchmark dataset. It can also be regarded as a backbone network for other methods, which likewise achieves state-of-the-art performance.
RoSAS: Deep Semi-Supervised Anomaly Detection with Contamination-Resilient Continuous Supervision
Jul 25, 2023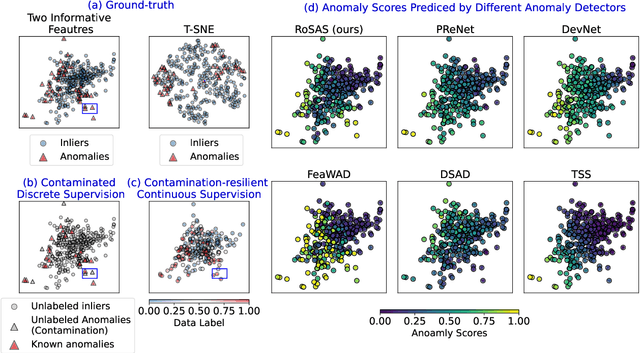

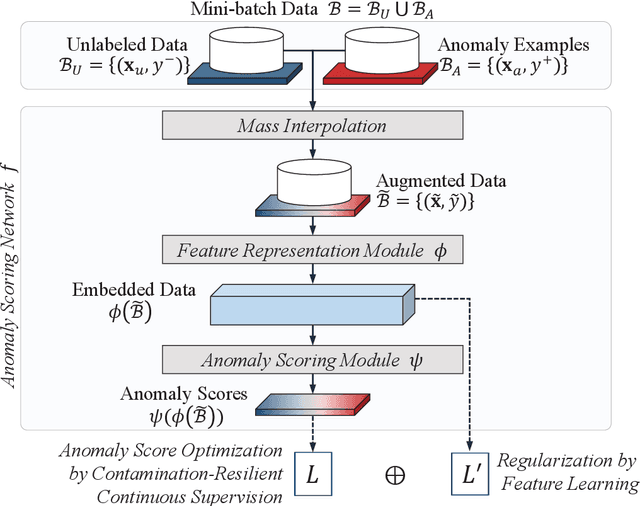
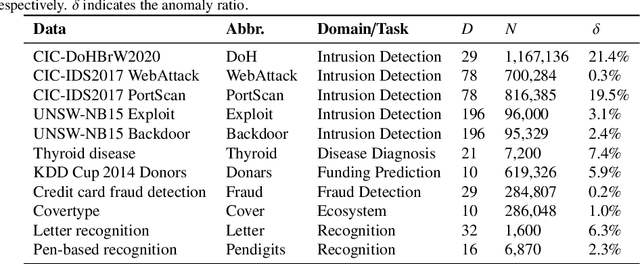
Semi-supervised anomaly detection methods leverage a few anomaly examples to yield drastically improved performance compared to unsupervised models. However, they still suffer from two limitations: 1) unlabeled anomalies (i.e., anomaly contamination) may mislead the learning process when all the unlabeled data are employed as inliers for model training; 2) only discrete supervision information (such as binary or ordinal data labels) is exploited, which leads to suboptimal learning of anomaly scores that essentially take on a continuous distribution. Therefore, this paper proposes a novel semi-supervised anomaly detection method, which devises \textit{contamination-resilient continuous supervisory signals}. Specifically, we propose a mass interpolation method to diffuse the abnormality of labeled anomalies, thereby creating new data samples labeled with continuous abnormal degrees. Meanwhile, the contaminated area can be covered by new data samples generated via combinations of data with correct labels. A feature learning-based objective is added to serve as an optimization constraint to regularize the network and further enhance the robustness w.r.t. anomaly contamination. Extensive experiments on 11 real-world datasets show that our approach significantly outperforms state-of-the-art competitors by 20%-30% in AUC-PR and obtains more robust and superior performance in settings with different anomaly contamination levels and varying numbers of labeled anomalies. The source code is available at https://github.com/xuhongzuo/rosas/.
Fascinating Supervisory Signals and Where to Find Them: Deep Anomaly Detection with Scale Learning
May 25, 2023Due to the unsupervised nature of anomaly detection, the key to fueling deep models is finding supervisory signals. Different from current reconstruction-guided generative models and transformation-based contrastive models, we devise novel data-driven supervision for tabular data by introducing a characteristic -- scale -- as data labels. By representing varied sub-vectors of data instances, we define scale as the relationship between the dimensionality of original sub-vectors and that of representations. Scales serve as labels attached to transformed representations, thus offering ample labeled data for neural network training. This paper further proposes a scale learning-based anomaly detection method. Supervised by the learning objective of scale distribution alignment, our approach learns the ranking of representations converted from varied subspaces of each data instance. Through this proxy task, our approach models inherent regularities and patterns within data, which well describes data "normality". Abnormal degrees of testing instances are obtained by measuring whether they fit these learned patterns. Extensive experiments show that our approach leads to significant improvement over state-of-the-art generative/contrastive anomaly detection methods.
Calibrated One-class Classification for Unsupervised Time Series Anomaly Detection
Jul 25, 2022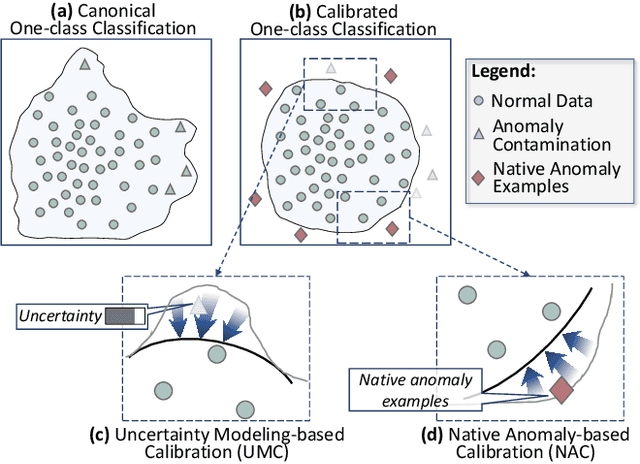
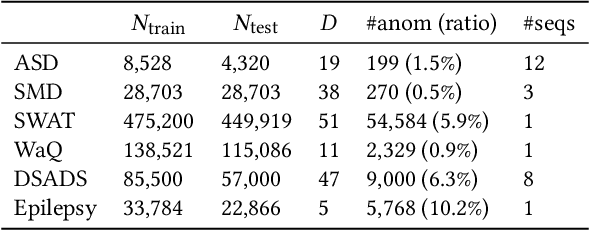
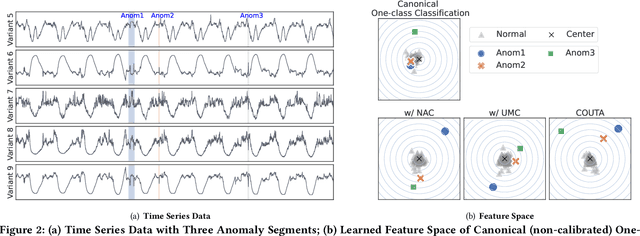
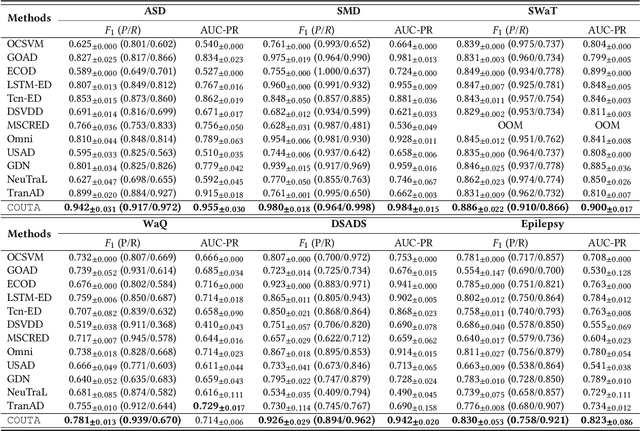
Unsupervised time series anomaly detection is instrumental in monitoring and alarming potential faults of target systems in various domains. Current state-of-the-art time series anomaly detectors mainly focus on devising advanced neural network structures and new reconstruction/prediction learning objectives to learn data normality (normal patterns and behaviors) as accurately as possible. However, these one-class learning methods can be deceived by unknown anomalies in the training data (i.e., anomaly contamination). Further, their normality learning also lacks knowledge about the anomalies of interest. Consequently, they often learn a biased, inaccurate normality boundary. This paper proposes a novel one-class learning approach, named calibrated one-class classification, to tackle this problem. Our one-class classifier is calibrated in two ways: (1) by adaptively penalizing uncertain predictions, which helps eliminate the impact of anomaly contamination while accentuating the predictions that the one-class model is confident in, and (2) by discriminating the normal samples from native anomaly examples that are generated to simulate genuine time series abnormal behaviors on the basis of original data. These two calibrations result in contamination-tolerant, anomaly-informed one-class learning, yielding a significantly improved normality modeling. Extensive experiments on six real-world datasets show that our model substantially outperforms twelve state-of-the-art competitors and obtains 6% - 31% F1 score improvement. The source code is available at \url{https://github.com/xuhongzuo/couta}.
DRAM Failure Prediction in AIOps: Empirical Evaluation, Challenges and Opportunities
May 04, 2021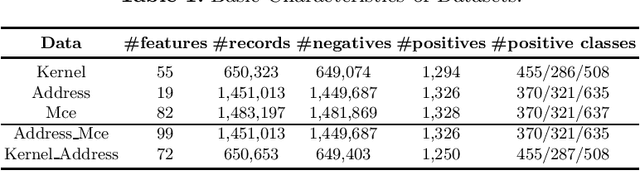
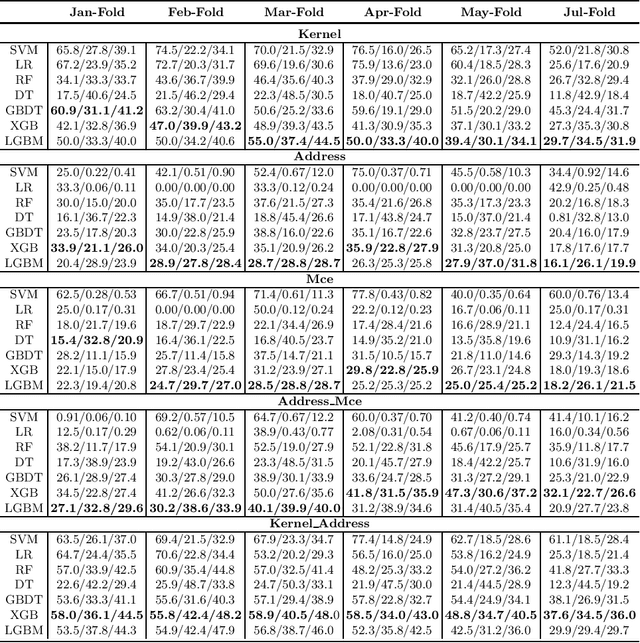
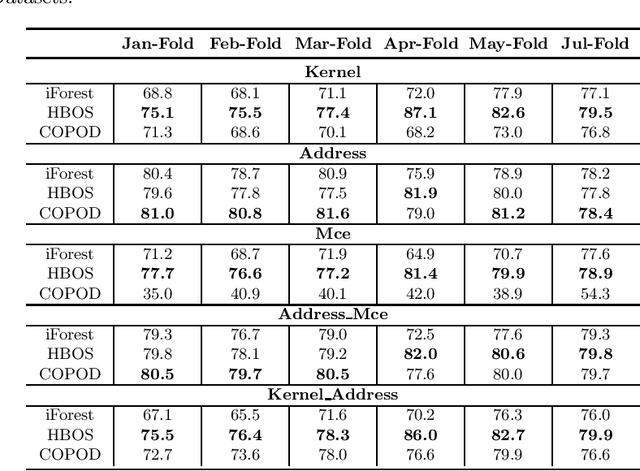
DRAM failure prediction is a vital task in AIOps, which is crucial to maintain the reliability and sustainable service of large-scale data centers. However, limited work has been done on DRAM failure prediction mainly due to the lack of public available datasets. This paper presents a comprehensive empirical evaluation of diverse machine learning techniques for DRAM failure prediction using a large-scale multi-source dataset, including more than three millions of records of kernel, address, and mcelog data, provided by Alibaba Cloud through PAKDD 2021 competition. Particularly, we first formulate the problem as a multi-class classification task and exhaustively evaluate seven popular/state-of-the-art classifiers on both the individual and multiple data sources. We then formulate the problem as an unsupervised anomaly detection task and evaluate three state-of-the-art anomaly detectors. Further, based on the empirical results and our experience of attending this competition, we discuss major challenges and present future research opportunities in this task.
Hierarchical Adaptive Pooling by Capturing High-order Dependency for Graph Representation Learning
Apr 13, 2021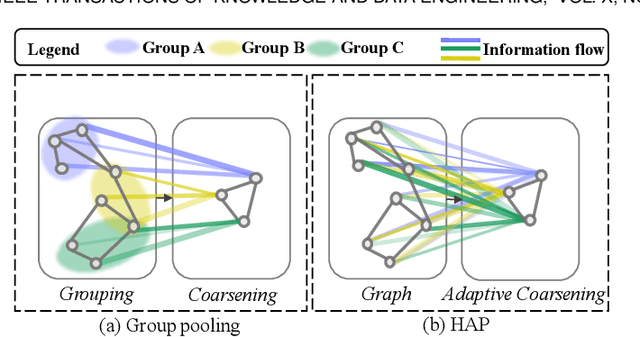
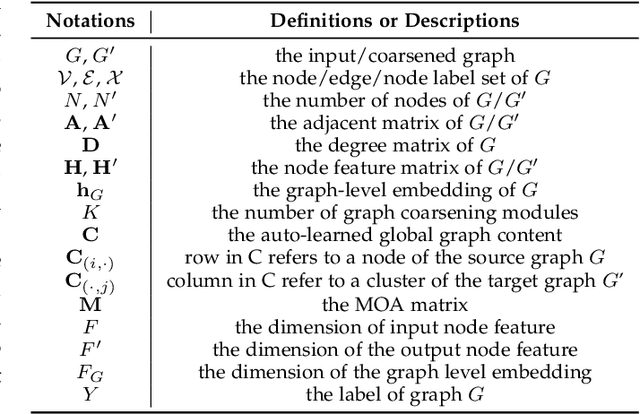
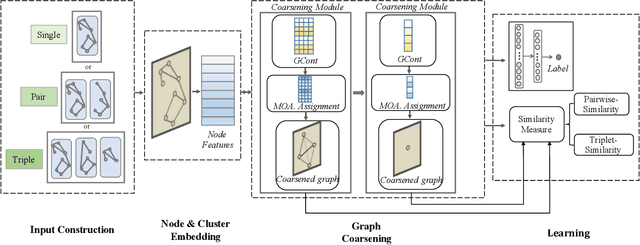
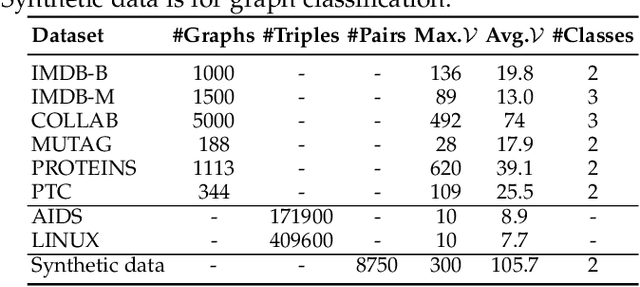
Graph neural networks (GNN) have been proven to be mature enough for handling graph-structured data on node-level graph representation learning tasks. However, the graph pooling technique for learning expressive graph-level representation is critical yet still challenging. Existing pooling methods either struggle to capture the local substructure or fail to effectively utilize high-order dependency, thus diminishing the expression capability. In this paper we propose HAP, a hierarchical graph-level representation learning framework, which is adaptively sensitive to graph structures, i.e., HAP clusters local substructures incorporating with high-order dependencies. HAP utilizes a novel cross-level attention mechanism MOA to naturally focus more on close neighborhood while effectively capture higher-order dependency that may contain crucial information. It also learns a global graph content GCont that extracts the graph pattern properties to make the pre- and post-coarsening graph content maintain stable, thus providing global guidance in graph coarsening. This novel innovation also facilitates generalization across graphs with the same form of features. Extensive experiments on fourteen datasets show that HAP significantly outperforms twelve popular graph pooling methods on graph classification task with an maximum accuracy improvement of 22.79%, and exceeds the performance of state-of-the-art graph matching and graph similarity learning algorithms by over 3.5% and 16.7%.
Rethinking Class Relations: Absolute-relative Few-shot Learning
Jan 12, 2020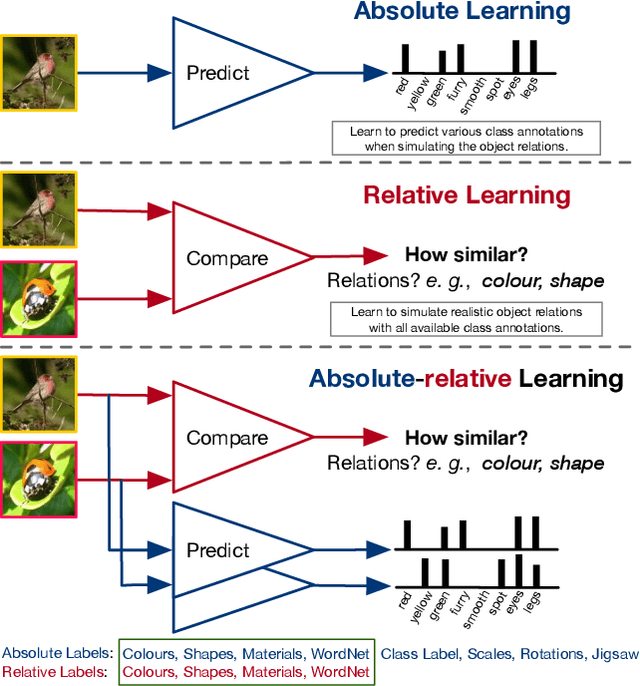
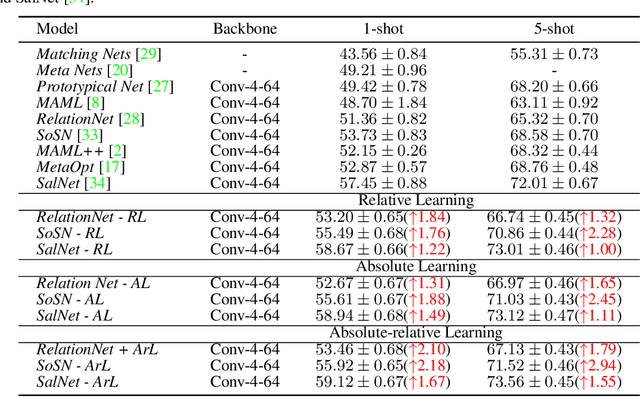
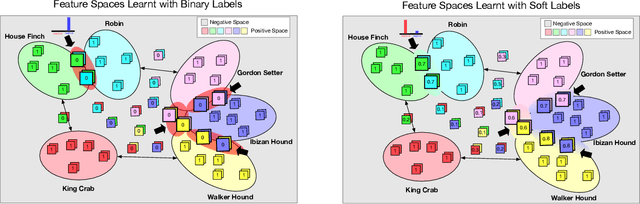
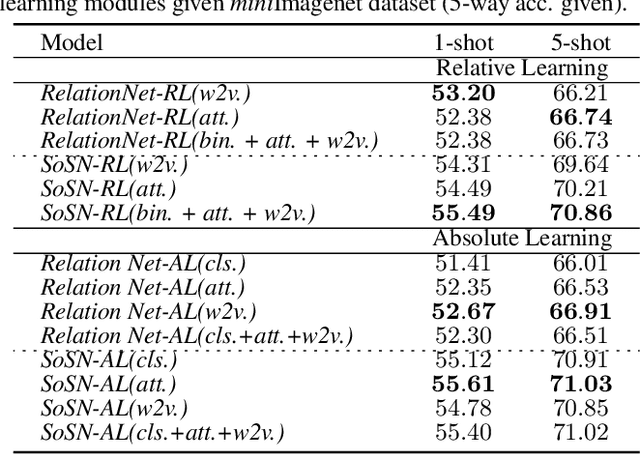
The majority of existing few-shot learning describe image relations with {0,1} binary labels. However, such binary relations are insufficient to teach the network complicated real-world relations, due to the lack of decision smoothness. Furthermore, current few-shot learning models capture only the similarity via relation labels, but they are not exposed to class concepts associated with objects, which is likely detrimental to the classification performance due to underutilization of the available class labels. To paraphrase, while children learn the concept of tiger from a few of examples with ease, and while they learn from comparisons of tiger to other animals, they are also taught the actual concept names. Thus, we hypothesize that in fact both similarity and class concept learning must be occurring simultaneously. With these observations at hand, we study the fundamental problem of simplistic class modeling in current few-shot learning, we rethink the relations between class concepts, and propose a novel absolute-relative learning paradigm to fully take advantage of label information to refine the image representations and correct the relation understanding. Our proposed absolute-relative learning paradigm improves the performance of several the state-of-the-art models on publicly available datasets.