 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadLLM-TG: A Backdoor Defender powered by LLM Trigger Generator
Mar 16, 2026Backdoor attacks compromise model reliability by using triggers to manipulate outputs. Trigger inversion can accurately locate these triggers via a generator and is therefore critical for backdoor defense. However, the discrete nature of text prevents existing noise-based trigger generator from being applied to nature language processing (NLP). To overcome the limitations, we employ the rich knowledge embedded in large language models (LLMs) and propose a Backdoor defender powered by LLM Trigger Generator, termed BadLLM-TG. It is optimized through prompt-driven reinforcement learning, using the victim model's feedback loss as the reward signal. The generated triggers are then employed to mitigate the backdoor via adversarial training. Experiments show that our method reduces the attack success rate by 76.2\% on average, outperforming the second-best defender by 13.7.
Angel or Devil: Discriminating Hard Samples and Anomaly Contaminations for Unsupervised Time Series Anomaly Detection
Oct 26, 2024



Training in unsupervised time series anomaly detection is constantly plagued by the discrimination between harmful `anomaly contaminations' and beneficial `hard normal samples'. These two samples exhibit analogous loss behavior that conventional loss-based methodologies struggle to differentiate. To tackle this problem, we propose a novel approach that supplements traditional loss behavior with `parameter behavior', enabling a more granular characterization of anomalous patterns. Parameter behavior is formalized by measuring the parametric response to minute perturbations in input samples. Leveraging the complementary nature of parameter and loss behaviors, we further propose a dual Parameter-Loss Data Augmentation method (termed PLDA), implemented within the reinforcement learning paradigm. During the training phase of anomaly detection, PLDA dynamically augments the training data through an iterative process that simultaneously mitigates anomaly contaminations while amplifying informative hard normal samples. PLDA demonstrates remarkable versatility, which can serve as an additional component that seamlessly integrated with existing anomaly detectors to enhance their detection performance. Extensive experiments on ten datasets show that PLDA significantly improves the performance of four distinct detectors by up to 8\%, outperforming three state-of-the-art data augmentation methods.
Normality Learning-based Graph Anomaly Detection via Multi-Scale Contrastive Learning
Oct 01, 2023


Graph anomaly detection (GAD) has attracted increasing attention in machine learning and data mining. Recent works have mainly focused on how to capture richer information to improve the quality of node embeddings for GAD. Despite their significant advances in detection performance, there is still a relative dearth of research on the properties of the task. GAD aims to discern the anomalies that deviate from most nodes. However, the model is prone to learn the pattern of normal samples which make up the majority of samples. Meanwhile, anomalies can be easily detected when their behaviors differ from normality. Therefore, the performance can be further improved by enhancing the ability to learn the normal pattern. To this end, we propose a normality learning-based GAD framework via multi-scale contrastive learning networks (NLGAD for abbreviation). Specifically, we first initialize the model with the contrastive networks on different scales. To provide sufficient and reliable normal nodes for normality learning, we design an effective hybrid strategy for normality selection. Finally, the model is refined with the only input of reliable normal nodes and learns a more accurate estimate of normality so that anomalous nodes can be more easily distinguished. Eventually, extensive experiments on six benchmark graph datasets demonstrate the effectiveness of our normality learning-based scheme on GAD. Notably, the proposed algorithm improves the detection performance (up to 5.89% AUC gain) compared with the state-of-the-art methods. The source code is released at https://github.com/FelixDJC/NLGAD.
GADMSL: Graph Anomaly Detection on Attributed Networks via Multi-scale Substructure Learning
Dec 02, 2022
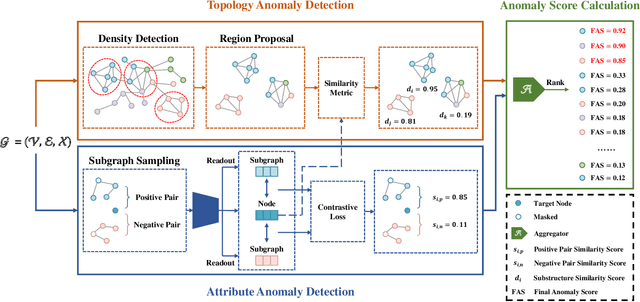
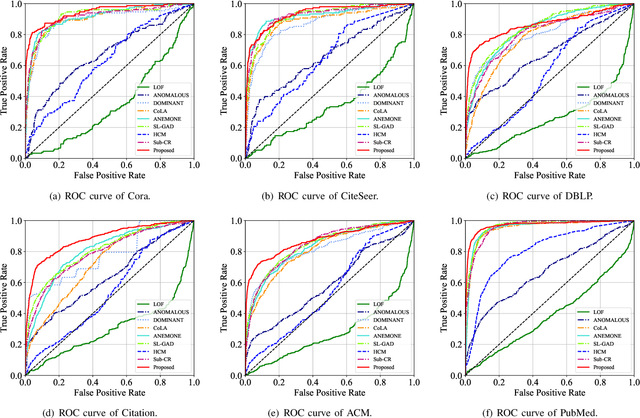

Recently, graph anomaly detection has attracted increasing attention in data mining and machine learning communities. Apart from existing attribute anomalies, graph anomaly detection also captures suspicious topological-abnormal nodes that differ from the major counterparts. Although massive graph-based detection approaches have been proposed, most of them focus on node-level comparison while pay insufficient attention on the surrounding topology structures. Nodes with more dissimilar neighborhood substructures have more suspicious to be abnormal. To enhance the local substructure detection ability, we propose a novel Graph Anomaly Detection framework via Multi-scale Substructure Learning (GADMSL for abbreviation). Unlike previous algorithms, we manage to capture anomalous substructures where the inner similarities are relatively low in dense-connected regions. Specifically, we adopt a region proposal module to find high-density substructures in the network as suspicious regions. Their inner-node embedding similarities indicate the anomaly degree of the detected substructures. Generally, a lower degree of embedding similarities means a higher probability that the substructure contains topology anomalies. To distill better embeddings of node attributes, we further introduce a graph contrastive learning scheme, which observes attribute anomalies in the meantime. In this way, GADMSL can detect both topology and attribute anomalies. Ultimately, extensive experiments on benchmark datasets show that GADMSL greatly improves detection performance (up to 7.30% AUC and 17.46% AUPRC gains) compared to state-of-the-art attributed networks anomaly detection algorithms.