 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-Guided Symbolic Regression: Towards Scientific Consistency in Equation Discovery
Feb 16, 2026Symbolic Regression (SR) aims to discover interpretable equations from observational data, with the potential to reveal underlying principles behind natural phenomena. However, existing approaches often fall into the Pseudo-Equation Trap: producing equations that fit observations well but remain inconsistent with fundamental scientific principles. A key reason is that these approaches are dominated by empirical risk minimization, lacking explicit constraints to ensure scientific consistency. To bridge this gap, we propose PG-SR, a prior-guided SR framework built upon a three-stage pipeline consisting of warm-up, evolution, and refinement. Throughout the pipeline, PG-SR introduces a prior constraint checker that explicitly encodes domain priors as executable constraint programs, and employs a Prior Annealing Constrained Evaluation (PACE) mechanism during the evolution stage to progressively steer discovery toward scientifically consistent regions. Theoretically, we prove that PG-SR reduces the Rademacher complexity of the hypothesis space, yielding tighter generalization bounds and establishing a guarantee against pseudo-equations. Experimentally, PG-SR outperforms state-of-the-art baselines across diverse domains, maintaining robustness to varying prior quality, noisy data, and data scarcity.
Nightjar: Dynamic Adaptive Speculative Decoding for Large Language Models Serving
Dec 27, 2025Speculative decoding (SD) accelerates LLM inference by verifying draft tokens in parallel. However, this method presents a critical trade-off: it improves throughput in low-load, memory-bound systems but degrades performance in high-load, compute-bound environments due to verification overhead. Current SD implementations use a fixed speculative length, failing to adapt to dynamic request rates and creating a significant performance bottleneck in real-world serving scenarios. To overcome this, we propose Nightjar, a novel learning-based algorithm for adaptive speculative inference that adjusts to request load by dynamically selecting the optimal speculative length for different batch sizes and even disabling speculative decoding when it provides no benefit. Experiments show that Nightjar achieves up to 14.8% higher throughput and 20.2% lower latency compared to standard speculative decoding, demonstrating robust efficiency for real-time serving.
Accurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance
Jul 24, 2024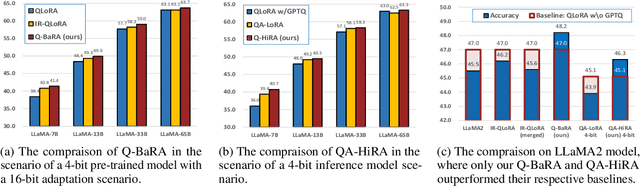
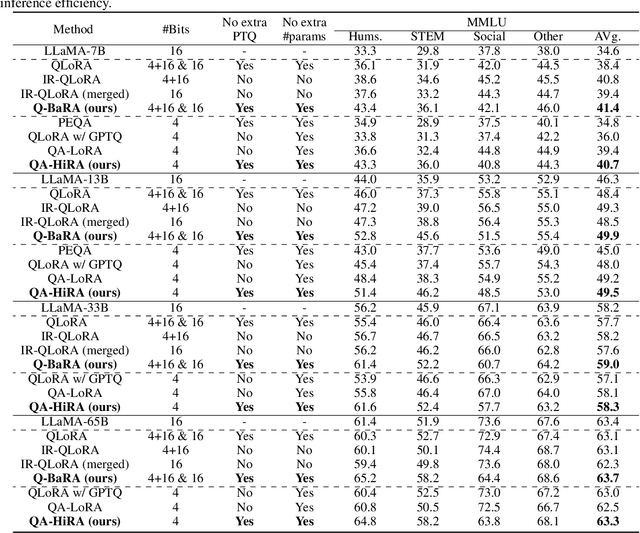
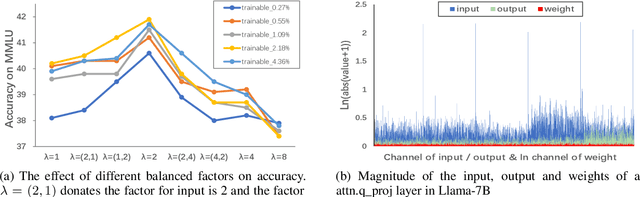
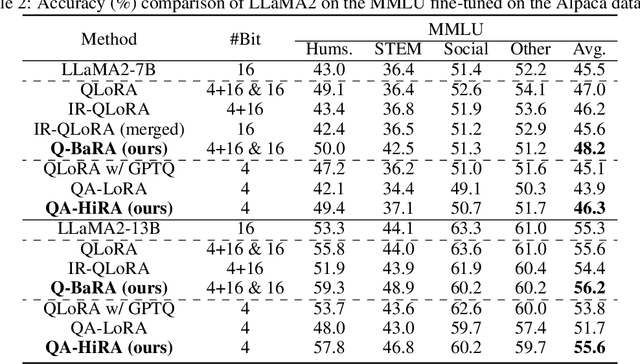
Large Language Models (LLMs) have demonstrated impressive performance across various domains. However, the enormous number of model parameters makes fine-tuning challenging, significantly limiting their application and deployment. Existing solutions combine parameter quantization with Low-Rank Adaptation (LoRA), greatly reducing memory usage but resulting in noticeable performance degradation. In this paper, we identify an imbalance in fine-tuning quantized pre-trained models: overly complex adapter inputs and outputs versus low effective trainability of the adaptation. We propose Quantized LLMs with Balanced-rank Adaptation (Q-BaRA), which simplifies the adapter inputs and outputs while increasing the adapter's rank to achieve a more suitable balance for fine-tuning quantized LLMs. Additionally, for scenarios where fine-tuned LLMs need to be deployed as low-precision inference models, we introduce Quantization-Aware Fine-tuning with Higher Rank Adaptation (QA-HiRA), which simplifies the adapter inputs and outputs to align with the pre-trained model's block-wise quantization while employing a single matrix to achieve a higher rank. Both Q-BaRA and QA-HiRA are easily implemented and offer the following optimizations: (i) Q-BaRA consistently achieves the highest accuracy compared to baselines and other variants, requiring the same number of trainable parameters and computational effort; (ii) QA-HiRA naturally merges adapter parameters into the block-wise quantized model after fine-tuning, achieving the highest accuracy compared to other methods. We apply our Q-BaRA and QA-HiRA to the LLaMA and LLaMA2 model families and validate their effectiveness across different fine-tuning datasets and downstream scenarios. Code will be made available at \href{https://github.com/xiaocaigou/qbaraqahira}{https://github.com/xiaocaigou/qbaraqahira}
Merak: An Efficient Distributed DNN Training Framework with Automated 3D Parallelism for Giant Foundation Models
Jun 21, 2022
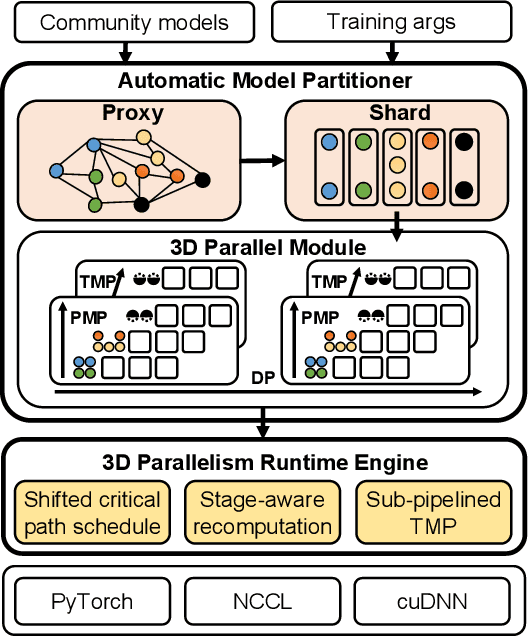

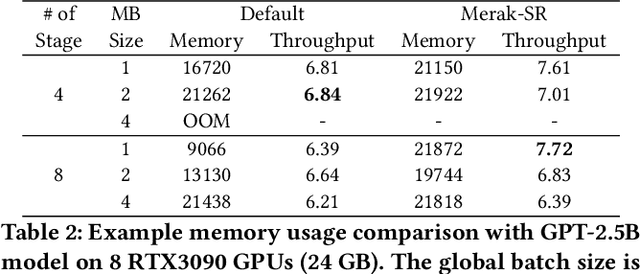
Foundation models are becoming the dominant deep learning technologies. Pretraining a foundation model is always time-consumed due to the large scale of both the model parameter and training dataset. Besides being computing-intensive, the training process is extremely memory-intensive and communication-intensive. These features make it necessary to apply 3D parallelism, which integrates data parallelism, pipeline model parallelism and tensor model parallelism, to achieve high training efficiency. To achieve this goal, some custom software frameworks such as Megatron-LM and DeepSpeed are developed. However, current 3D parallelism frameworks still meet two issues: i) they are not transparent to model developers, which need to manually modify the model to parallelize training. ii) their utilization of computation, GPU memory and network bandwidth are not sufficient. We propose Merak, an automated 3D parallelism deep learning training framework with high resource utilization. Merak automatically deploys with an automatic model partitioner, which uses a graph sharding algorithm on a proxy representation of the model. Merak also presents the non-intrusive API for scaling out foundation model training with minimal code modification. In addition, we design a high-performance 3D parallel runtime engine in Merak. It uses several techniques to exploit available training resources, including shifted critical path pipeline schedule that brings a higher computation utilization, stage-aware recomputation that makes use of idle worker memory, and sub-pipelined tensor model parallelism that overlaps communication and computation. Experiments on 64 GPUs show Merak can speedup the training performance over the state-of-the-art 3D parallelism frameworks of models with 1.5, 2.5, 8.3, and 20 billion parameters by up to 1.42X, 1.39X, 1.43X, and 1.61X, respectively.
DELTA: Dynamically Optimizing GPU Memory beyond Tensor Recomputation
Mar 30, 2022

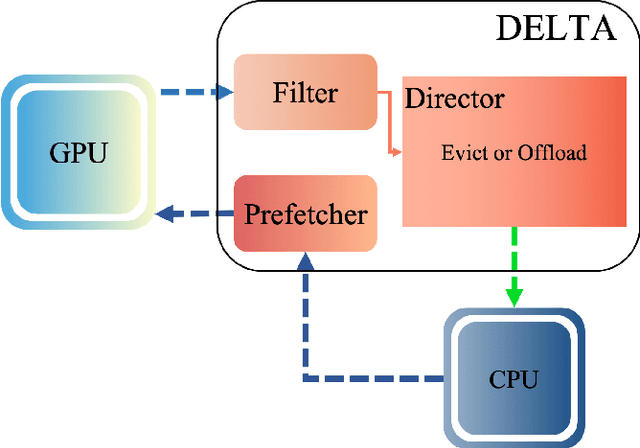
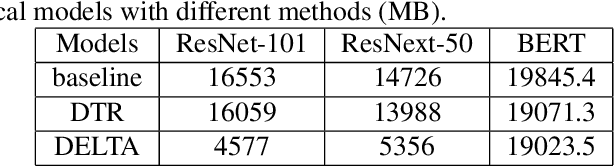
The further development of deep neural networks is hampered by the limited GPU memory resource. Therefore, the optimization of GPU memory resources is highly demanded. Swapping and recomputation are commonly applied to make better use of GPU memory in deep learning. However, as an emerging domain, several challenges remain:1)The efficiency of recomputation is limited for both static and dynamic methods. 2)Swapping requires offloading parameters manually, which incurs a great time cost. 3) There is no such dynamic and fine-grained method that involves tensor swapping together with tensor recomputation nowadays. To remedy the above issues, we propose a novel scheduler manager named DELTA(Dynamic tEnsor offLoad and recompuTAtion). To the best of our knowledge, we are the first to make a reasonable dynamic runtime scheduler on the combination of tensor swapping and tensor recomputation without user oversight. In DELTA, we propose a filter algorithm to select the optimal tensors to be released out of GPU memory and present a director algorithm to select a proper action for each of these tensors. Furthermore, prefetching and overlapping are deliberately considered to overcome the time cost caused by swapping and recomputing tensors. Experimental results show that DELTA not only saves 40%-70% of GPU memory, surpassing the state-of-the-art method to a great extent but also gets comparable convergence results as the baseline with acceptable time delay. Also, DELTA gains 2.04$\times$ maximum batchsize when training ResNet-50 and 2.25$\times$ when training ResNet-101 compared with the baseline. Besides, comparisons between the swapping cost and recomputation cost in our experiments demonstrate the importance of making a reasonable dynamic scheduler on tensor swapping and tensor recomputation, which refutes the arguments in some related work that swapping should be the first and best choice.
EmbRace: Accelerating Sparse Communication for Distributed Training of NLP Neural Networks
Oct 18, 2021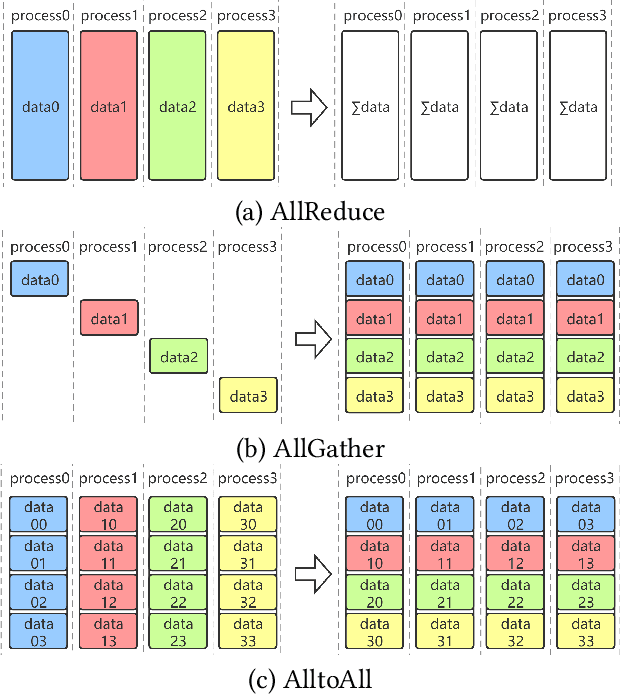
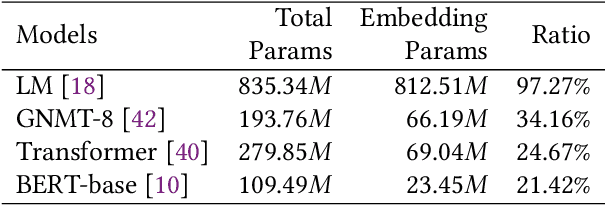
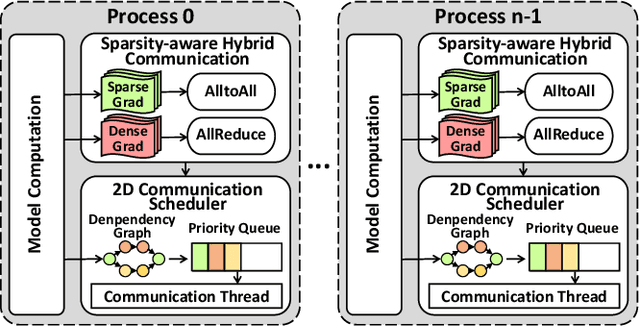
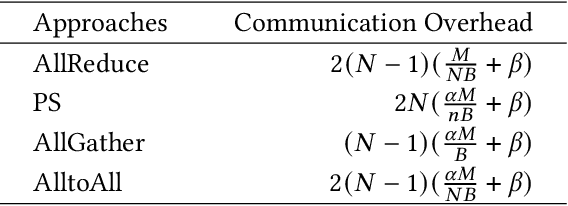
Distributed data-parallel training has been widely used for natural language processing (NLP) neural network models. However, the embedding tables in NLP models, holding a large portion of parameters and bringing dramatic sparsity in communication, make it a big challenge to efficiently scale the distributed training. Current distributed training frameworks mainly concentrate on dense models but neglect the sparsity of NLP models, resulting in significant communication overhead and relatively poor scalability. In this paper, we propose EmbRace, an efficient communication framework designed to accelerate sparse communication of distributed NLP model training. EmbRace introduces Sparsity-aware Hybrid Communication, which combines AlltoAll and AllReduce to optimize the communication overhead for sparse and dense data in NLP models. EmbRace further introduces a 2D Communication Scheduling approach to thoroughly overlap communication with computation by optimizing model computation procedure, relaxing the dependency of embeddings, and scheduling communication with a priority queue. We implement EmbRace based on PyTorch and Horovod, and conduct comprehensive evaluations with four representative NLP models on two high-performance GPU clusters. Experimental results show that EmbRace achieves up to 30.66X speedup on 16 GPUs clusters among four popular distributed training baselines.
S2 Reducer: High-Performance Sparse Communication to Accelerate Distributed Deep Learning
Oct 05, 2021
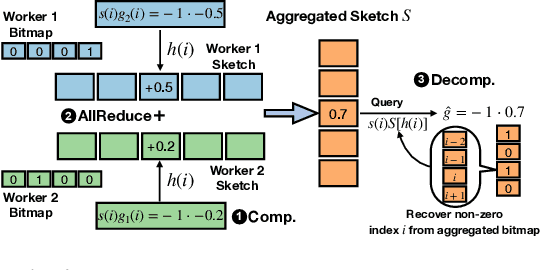

Distributed stochastic gradient descent (SGD) approach has been widely used in large-scale deep learning, and the gradient collective method is vital to ensure the training scalability of the distributed deep learning system. Collective communication such as AllReduce has been widely adopted for the distributed SGD process to reduce the communication time. However, AllReduce incurs large bandwidth resources while most gradients are sparse in many cases since many gradient values are zeros and should be efficiently compressed for bandwidth saving. To reduce the sparse gradient communication overhead, we propose Sparse-Sketch Reducer (S2 Reducer), a novel sketch-based sparse gradient aggregation method with convergence guarantees. S2 Reducer reduces the communication cost by only compressing the non-zero gradients with count-sketch and bitmap, and enables the efficient AllReduce operators for parallel SGD training. We perform extensive evaluation against four state-of-the-art methods over five training models. Our results show that S2 Reducer converges to the same accuracy, reduces 81\% sparse communication overhead, and achieves 1.8$ \times $ speedup compared to state-of-the-art approaches.
Hierarchical Adaptive Pooling by Capturing High-order Dependency for Graph Representation Learning
Apr 13, 2021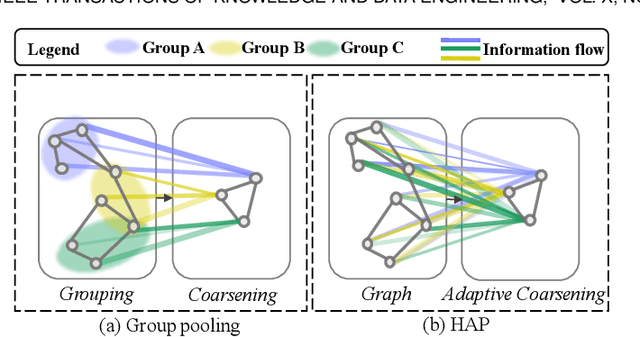
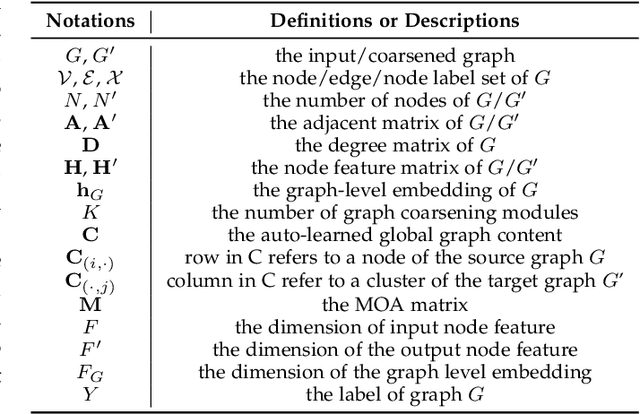
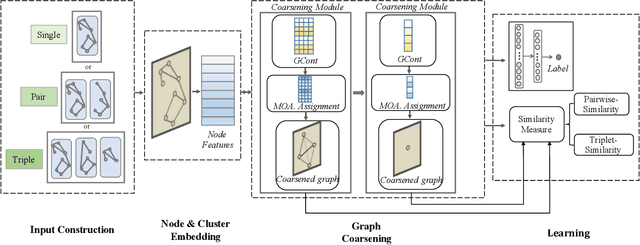
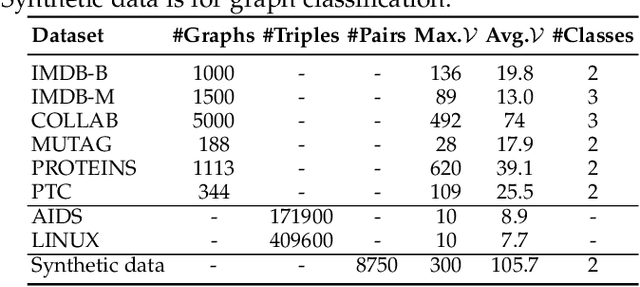
Graph neural networks (GNN) have been proven to be mature enough for handling graph-structured data on node-level graph representation learning tasks. However, the graph pooling technique for learning expressive graph-level representation is critical yet still challenging. Existing pooling methods either struggle to capture the local substructure or fail to effectively utilize high-order dependency, thus diminishing the expression capability. In this paper we propose HAP, a hierarchical graph-level representation learning framework, which is adaptively sensitive to graph structures, i.e., HAP clusters local substructures incorporating with high-order dependencies. HAP utilizes a novel cross-level attention mechanism MOA to naturally focus more on close neighborhood while effectively capture higher-order dependency that may contain crucial information. It also learns a global graph content GCont that extracts the graph pattern properties to make the pre- and post-coarsening graph content maintain stable, thus providing global guidance in graph coarsening. This novel innovation also facilitates generalization across graphs with the same form of features. Extensive experiments on fourteen datasets show that HAP significantly outperforms twelve popular graph pooling methods on graph classification task with an maximum accuracy improvement of 22.79%, and exceeds the performance of state-of-the-art graph matching and graph similarity learning algorithms by over 3.5% and 16.7%.
ADMMiRNN: Training RNN with Stable Convergence via An Efficient ADMM Approach
Jun 17, 2020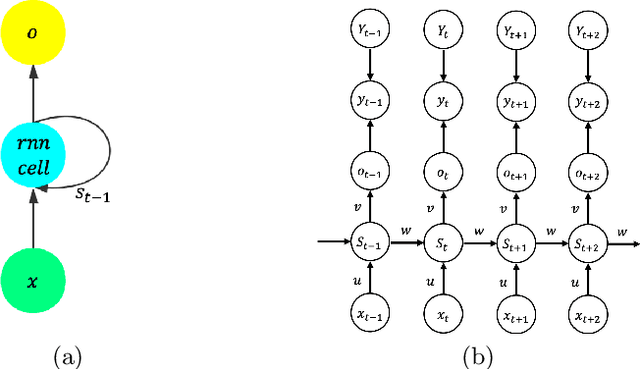

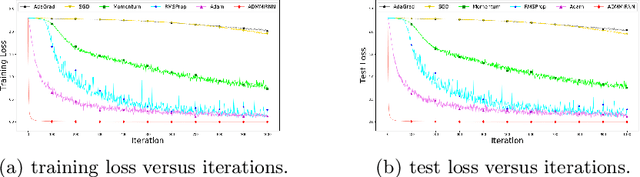
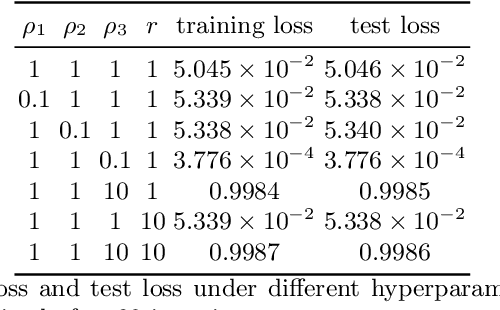
It is hard to train Recurrent Neural Network (RNN) with stable convergence and avoid gradient vanishing and exploding, as the weights in the recurrent unit are repeated from iteration to iteration. Moreover, RNN is sensitive to the initialization of weights and bias, which brings difficulty in the training phase. With the gradient-free feature and immunity to poor conditions, the Alternating Direction Method of Multipliers (ADMM) has become a promising algorithm to train neural networks beyond traditional stochastic gradient algorithms. However, ADMM could not be applied to train RNN directly since the state in the recurrent unit is repetitively updated over timesteps. Therefore, this work builds a new framework named ADMMiRNN upon the unfolded form of RNN to address the above challenges simultaneously and provides novel update rules and theoretical convergence analysis. We explicitly specify key update rules in the iterations of ADMMiRNN with deliberately constructed approximation techniques and solutions to each subproblem instead of vanilla ADMM. Numerical experiments are conducted on MNIST and text classification tasks, where ADMMiRNN achieves convergent results and outperforms compared baselines. Furthermore, ADMMiRNN trains RNN in a more stable way without gradient vanishing or exploding compared to the stochastic gradient algorithms. Source code has been available at https://github.com/TonyTangYu/ADMMiRNN.