 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2 Reducer: High-Performance Sparse Communication to Accelerate Distributed Deep Learning
Paper and Code
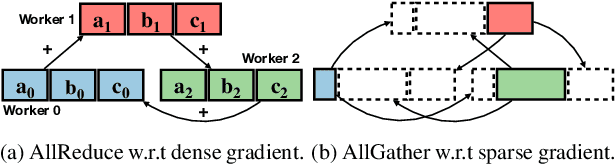
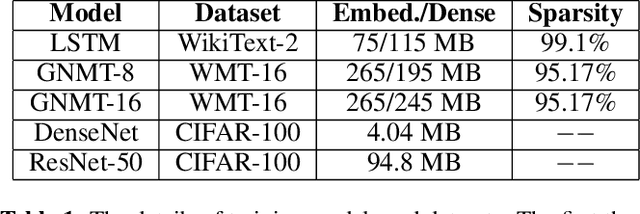
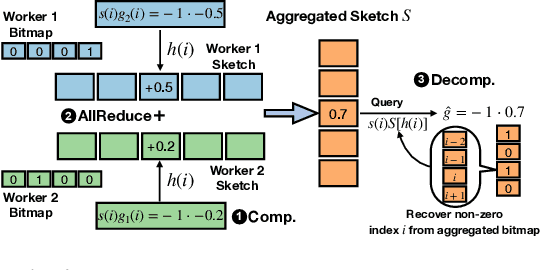

Distributed stochastic gradient descent (SGD) approach has been widely used in large-scale deep learning, and the gradient collective method is vital to ensure the training scalability of the distributed deep learning system. Collective communication such as AllReduce has been widely adopted for the distributed SGD process to reduce the communication time. However, AllReduce incurs large bandwidth resources while most gradients are sparse in many cases since many gradient values are zeros and should be efficiently compressed for bandwidth saving. To reduce the sparse gradient communication overhead, we propose Sparse-Sketch Reducer (S2 Reducer), a novel sketch-based sparse gradient aggregation method with convergence guarantees. S2 Reducer reduces the communication cost by only compressing the non-zero gradients with count-sketch and bitmap, and enables the efficient AllReduce operators for parallel SGD training. We perform extensive evaluation against four state-of-the-art methods over five training models. Our results show that S2 Reducer converges to the same accuracy, reduces 81\% sparse communication overhead, and achieves 1.8$ \times $ speedup compared to state-of-the-art approaches.