 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiskQ: Risk-sensitive Multi-Agent Reinforcement Learning Value Factorization
Nov 03, 2023Multi-agent systems are characterized by environmental uncertainty, varying policies of agents, and partial observability, which result in significant risks. In the context of Multi-Agent Reinforcement Learning (MARL), learning coordinated and decentralized policies that are sensitive to risk is challenging. To formulate the coordination requirements in risk-sensitive MARL, we introduce the Risk-sensitive Individual-Global-Max (RIGM) principle as a generalization of the Individual-Global-Max (IGM) and Distributional IGM (DIGM) principles. This principle requires that the collection of risk-sensitive action selections of each agent should be equivalent to the risk-sensitive action selection of the central policy. Current MARL value factorization methods do not satisfy the RIGM principle for common risk metrics such as the Value at Risk (VaR) metric or distorted risk measurements. Therefore, we propose RiskQ to address this limitation, which models the joint return distribution by modeling quantiles of it as weighted quantile mixtures of per-agent return distribution utilities. RiskQ satisfies the RIGM principle for the VaR and distorted risk metrics. We show that RiskQ can obtain promising performance through extensive experiments. The source code of RiskQ is available in https://github.com/xmu-rl-3dv/RiskQ.
CGNN: Traffic Classification with Graph Neural Network
Oct 19, 2021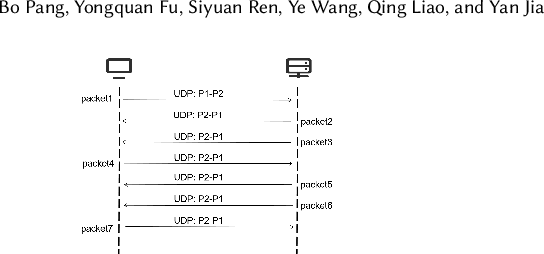

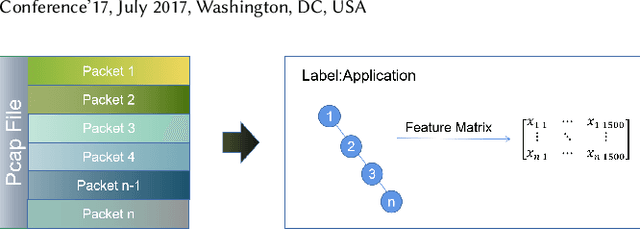
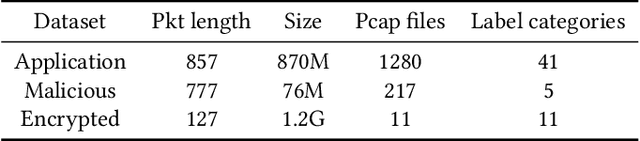
Traffic classification associates packet streams with known application labels, which is vital for network security and network management. With the rise of NAT, port dynamics, and encrypted traffic, it is increasingly challenging to obtain unified traffic features for accurate classification. Many state-of-the-art traffic classifiers automatically extract features from the packet stream based on deep learning models such as convolution networks. Unfortunately, the compositional and causal relationships between packets are not well extracted in these deep learning models, which affects both prediction accuracy and generalization on different traffic types. In this paper, we present a chained graph model on the packet stream to keep the chained compositional sequence. Next, we propose CGNN, a graph neural network based traffic classification method, which builds a graph classifier over automatically extracted features over the chained graph. Extensive evaluation over real-world traffic data sets, including normal, encrypted and malicious labels, show that, CGNN improves the prediction accuracy by 23\% to 29\% for application classification, by 2\% to 37\% for malicious traffic classification, and reaches the same accuracy level for encrypted traffic classification. CGNN is quite robust in terms of the recall and precision metrics. We have extensively evaluated the parameter sensitivity of CGNN, which yields optimized parameters that are quite effective for traffic classification.
S2 Reducer: High-Performance Sparse Communication to Accelerate Distributed Deep Learning
Oct 05, 2021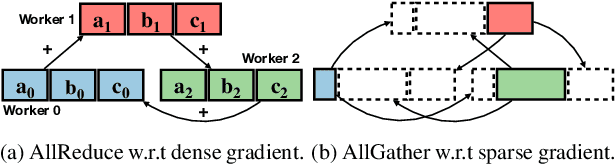
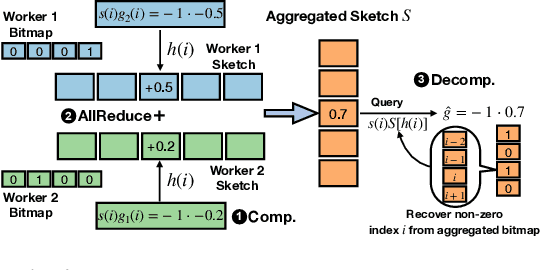

Distributed stochastic gradient descent (SGD) approach has been widely used in large-scale deep learning, and the gradient collective method is vital to ensure the training scalability of the distributed deep learning system. Collective communication such as AllReduce has been widely adopted for the distributed SGD process to reduce the communication time. However, AllReduce incurs large bandwidth resources while most gradients are sparse in many cases since many gradient values are zeros and should be efficiently compressed for bandwidth saving. To reduce the sparse gradient communication overhead, we propose Sparse-Sketch Reducer (S2 Reducer), a novel sketch-based sparse gradient aggregation method with convergence guarantees. S2 Reducer reduces the communication cost by only compressing the non-zero gradients with count-sketch and bitmap, and enables the efficient AllReduce operators for parallel SGD training. We perform extensive evaluation against four state-of-the-art methods over five training models. Our results show that S2 Reducer converges to the same accuracy, reduces 81\% sparse communication overhead, and achieves 1.8$ \times $ speedup compared to state-of-the-art approaches.
Nyström Approximation with Nonnegative Matrix Factorization
Aug 07, 2020
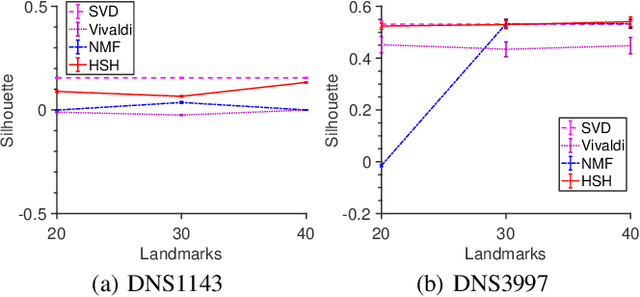

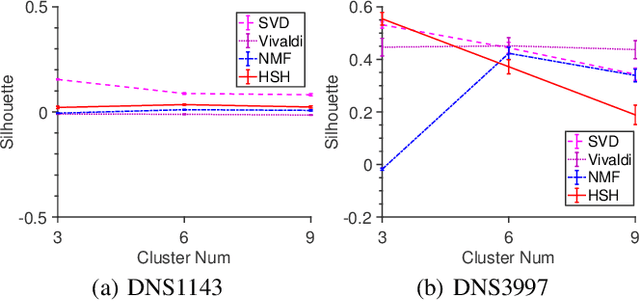
Motivated by the needs of estimating the proximity clustering with partial distance measurements from vantage points or landmarks for remote networked systems, we show that the proximity clustering problem can be effectively formulated as the Nystr\"om approximation problem, which solves the kernel K-means clustering problem in the complex space. We implement the Nystr\"om approximation based on a landmark based Nonnegative Matrix Factorization (NMF) process. Evaluation results show that the proposed method finds nearly optimal clustering quality on both synthetic and real-world data sets as we vary the range of parameter choices and network conditions.